 01.高并发在简历上如何体现?
01.高并发在简历上如何体现?
个人觉得并发相关的内容是最基础的,同时也是最重要的能力,在面试中并发相关的内容也是比较热点的,在项目中的优化也离不开并发!
最近更新的 并发专栏的内容终于完结了,包括:
[synchronized] 面试杀手锏:全面剖析 synchronized 锁升级流程 (opens new window)
[synchronized] 面试官:synchronized 关键字可以保证可见性吗? (opens new window)
[synchronized] 为什么不建议在高并发场景下使用 synchronized? (opens new window)
[ReentrantLock] 6K+字 ReentrantLock 原理全面详解 (opens new window)
[线程池、AQS、CAS] 京东并行框架asyncTool如何针对高并发场景进行优化? (opens new window)
[分布式锁] Redis和ZooKeeper分布式锁优缺点对比以及生产环境使用建议 (opens new window)
接下来说一下如何通过并发来优化自己的项目!
在面试中所谓的项目亮点要么是 业务亮点 ,要么是 技术亮点
- 业务亮点
业务亮点 也就是设计模式、业务、可用性的体现,而作为应届生来说,一般也写不了很多业务代码,这方面的积累不会太好,所以应届生的简历优化、项目优化更加侧重于 技术亮点
- 技术亮点 如何体现呢?
体现在对项目优化上,那么项目要如何优化呢?
可以从两个角度来考虑,一个是 高可用 方面的优化,另一个是 高并发 方面的优化
这里主要说一下高并发,要优化项目,首先要想当项目的访问量上来之后,我们应该如何去提升项目的 QPS 以及接口响应时间!
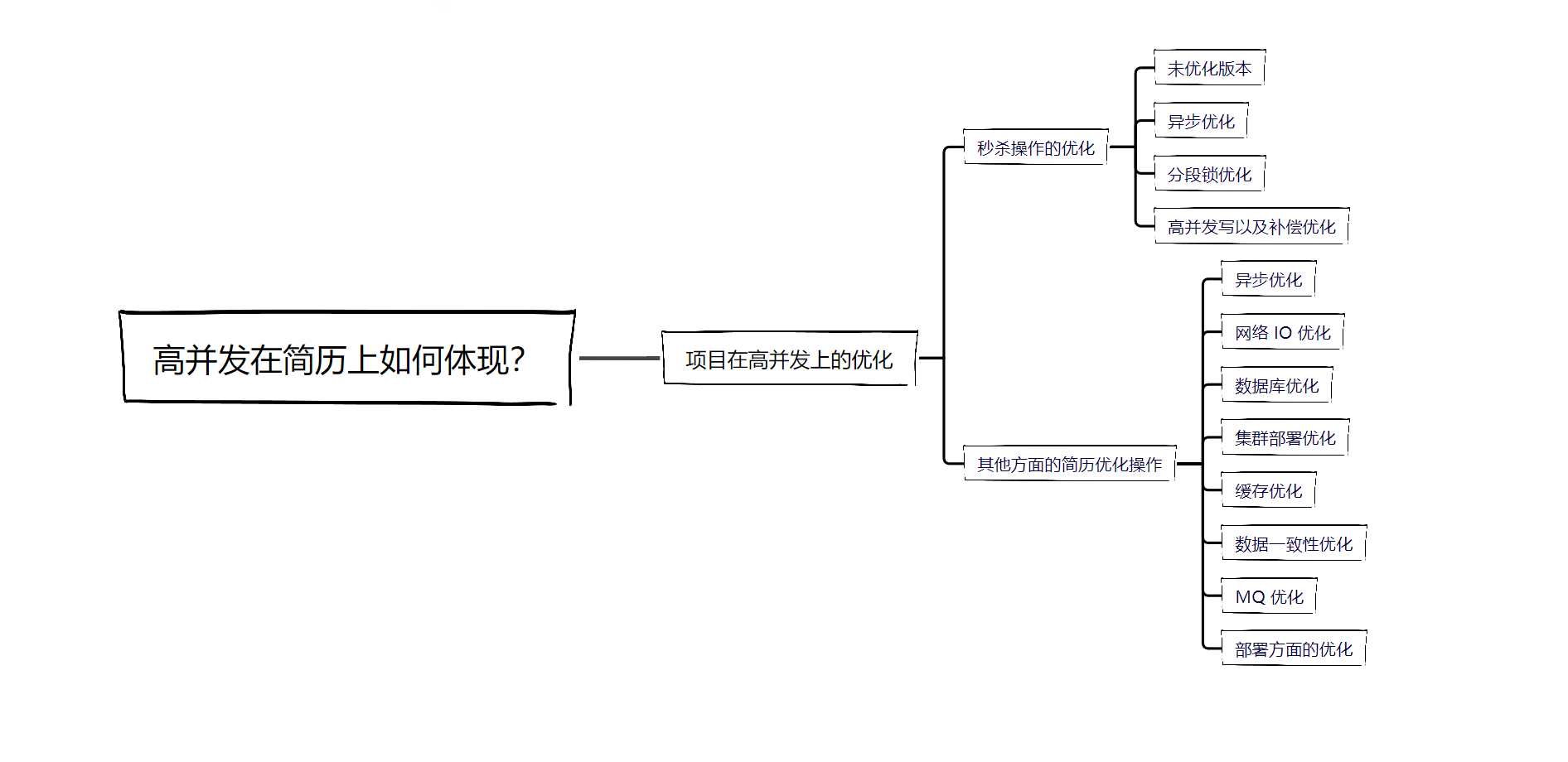
# 项目在高并发上的优化
# 秒杀操作的优化
# 未优化版本
以电商中的 秒杀操作 来说,需要加锁来保证秒杀操作的并发安全,如果没有什么并发量,用户量很小,那么我们可以使用最简单的方式实现:
- 如果秒杀模块是单节点部署,那么就使用 synchronized 将整个秒杀流程给锁住就好了
- 如果秒杀模块是多节点部署,那么就使用 Redis 分布式锁 或者 ZK 分布式锁 将整个秒杀流程给锁住就好了
这样做的话,好处就是实现起来比较方便,但是由于我们锁的粒度是比较大的,将整个秒杀流程都给锁住,并且秒杀中肯定会有许多耗时操作,比如扣减库存、生成订单等等,这些都是网络 IO 操作以及对共享资源的并发操作,这样耗时操作全部串行执行,会导致整个秒杀流程耗时较长
# 异步优化
- 那么我们就可以考虑通过异步化的方式对秒杀操作进行优化!
在高并发系统中,要进行性能优化,无非是从 3 个方面:分流 、 缓存 、 异步
异步化 的好处就是可以让比较耗时的操作脱离主流程,这样主流程在发起这些比较耗时的操作之后,可以去接着做其他的事情
那么我们就可以使用队列来对秒杀操作进行异步化,当用户发起秒杀请求时,将秒杀请求放入队列中,消费者监听到消息之后,根据自己的能力去队列中取出请求进行秒杀的处理,这样就可以避免大量的下单请求从而导致应用负荷较高

- 因此经过队列优化后,整个秒杀的下单流程为:
1、用户提交订单请求,请求进入到队列中,并返回用户一个排队编号
2、用户提交订单后,进入到等待界面中,显示用户前边还有多少请求等待处理,预计多长时间处理完毕
3、当用户的订单被下单系统成功处理之后,将用户界面跳转到支付页面,提示用户进行支付,之后就完成这笔订单
- 那么既然使用队列来优化性能,选择哪一个队列组件来实现呢?
我们常用的消息队列有 RocketMQ、Kafka 等等,这里并没有选用这些消息队列,而是 使用了 Redis 来实现队列
相比于 RocketMQ 这些,Redis 更加轻量,并且基于内存操作,性能更好,使用 Redis 自带的队列数据结构,可以获取 队列长度 以及 请求在队列中的位置 ,可以及时反馈给用户排队进度
上边说了通过异步化的方式将秒杀流程给脱离出去,这样就可以保证比较好的性能
# 分段锁优化
那么还可不可以进一步优化呢?
可以的,上边虽然通过队列将秒杀流程异步化,但是最终主干流程还是需要取到这个异步化的结果的,那么可以针对秒杀流程中对共享资源的加锁进行优化,也就是 对分布式锁进行优化
这里假设使用了 Redis 分布式锁,针对分布式锁的优化其实比较简单,就是 降低锁粒度!
秒杀中肯定要扣减库存,秒杀模块多节点部署的话,多个节点同时操作库存是不安全的,因此肯定要使用分布式锁,原先我们使用分布式锁将整个库存给锁起来,比如果有 10000 件库存的话,每个节点来操作时,都会竞争这一把锁
降低锁粒度之后,也就是使用 分段锁 ,可以将 10000 个库存分为 100 份进行存储,即 inventory_01 = 100、inventory_02 = 100、...、inventory_100 = 100 ,每一份分配一把锁,那么原来所有的节点都是去竞争 1 把分布式锁,现在是竞争 100 把分布式锁,性能提升了 100 倍!

# 高并发写以及补偿优化
上边说了通过分段锁优化,其实还可以再进一步优化
在秒杀中,是需要针对库存进行 高并发的写操作 的,那么针对于高并发的写操作有这么一个优化流程:直接对 Redis 缓存进行写操作,再通过 RocketMQ 异步进行落库 ,也就是 将 Redis 作为主存储,将 DB 作为辅助存储
那么这样的话,可以大幅度提升高并发写的性能!
这里如果为了保证库存更新的可靠性的话,可以考虑在 DB 中先存储订单状态,当 RocketMQ 异步处理之后,将订单状态修改为已完成,如果存在未完成的订单状态,就 通过定时任务扫描进行补偿

# 其他方面的简历优化操作
# 异步优化
针对异步的优化,可能有些操作任务比较简单,并不需要使用很重的 RocketMQ 进行异步化,那么就可以使用简单的 CompletableFuture 进行异步化,并且京东还开源了 asyncTool 并行框架 ,提供了比 CompletableFuture 更加丰富的任务编排功能!
# 网络 IO 优化
还有一些网络 IO 的操作,可以将耗时的操作丢到线程池中去,通过 线程池 进行来提升耗时 IO 操作的性能
如果是传输类的优化,可以考虑 压缩传输数据的大小 或者 自定义网络传输协议 ,这样在网络中传输的数据量就小了,以此来提升网络传输的性能
# 数据库优化
数据库方面的优化,如果表数据量可能会达到几百万甚至上千万(用户表、订单表),可以考虑 提前进行分库分表
当业务基本稳定之后,可以根据业务去数据库中 建立索引 ,优化数据库查询性能
对 慢查询 问题的监控、排查,以及解决
# 集群部署优化
对于有些可能承载比较多请求的模块,可以考虑 多节点部署 ,针对这些节点进行负载均衡,来分散请求压力
# 缓存优化
读多写少 的场景使用 Redis 缓存数据,优化查询效率
写多读少 的场景可以使用 Redis 作为主存储 ,针对 Redis 执行写操作,通过 MQ 异步落库
Redis 中的热点数据存储在 JVM 缓存中,使用 二级缓存(Redis+JVM缓存) ,JVM 缓存可以使用 Guava Cache 或者 Caffeine 实现
# 数据一致性优化
既然用到了缓存,肯定是要保证缓存数据与数据库的一致性,这里说一下常用的 数据一致性保证策略 :
- AOP + 延时双删 :通过 AOP + 延时双删来保证 Redis 和 MySQL 的数据一致性
- Canal + MQ :通过 Canal + MQ 来同步数据库中的增量数据,来保证数据库和缓存的一致性
# MQ 优化
使用 MQ 的话,主要是针对于三个方面优化: 解耦 、 异步化
解耦 可以让系统的可扩展性更强,并且比较容易维护,比如用户取消订单的操作,在用户创建完订单之后,如果取消订单,在不使用 MQ 的情况下,需要在取消订单的逻辑中去一个一个执行取消订单后需要执行的操作,如下:
- 库存系统释放库存
- 返还用户积分
- 释放用户使用的优惠券
这样会导致取消订单的动作和其他业务耦合度很高,如果使用 MQ 之后,只需要在这三个地方关注订单取消的事件,不需要将取消订单中做很多耦合的操作
如果后续需要对取消订单做出调整,只用在订阅【取消订单】事件的位置修改代码即可
异步化 可以降低耗时操作对系统的影响,并且可以将一瞬间的大量请求给铺开来,也就是 削峰填谷
在用户推送消息的场景中,可能需要向大量用户推送数据,那么系统就需要向 MQ 推送大量数据,那么就可以引入 多线程 优化,如果数据量太大的话,可以考虑 将数据进行分片 ,提升推送的速度,如下图,将 1000w 用户分片为 10000 条,并使用多线程推送:

# 部署方面的优化
部署方面的话,就是机器如何部署,以及对机器性能的了解,这些属于生产经验
在项目上线部署之后,可以对项目部署一套监控环境(Prometheus + Grafana),再对项目进行压测,观察项目的:
- QPS: 每秒执行的请求数
- TPS: 每秒执行的事务数
- RT: 接口的响应时间(T99、T95)
- 机器的负荷指标 (CPU、IO、内存、带宽负荷):CPU 负荷可以使用 top 命令查看 Load Average 指标
这样可以了解项目在生产环境部署时可以承载的最大请求数量,心里对系统的性能有个大致的了解!
这里说一下常用的机器部署经验:
对于网关、注册中心、数据库这种属于是 基础架构类型的系统 ,一般来说机器的配置要高一些(4C8G、8C16G 以上)
一般网关、注册中心都是集群部署,网关一般部署 2-3 台,注册中心如果使用 ZK 的话,部署 1 主 2 从
数据库部署的话,4C8G 的机器部署 MySQL 一般每秒可以应对几百个请求;8C16G 可以应对几百上千的请求;16C32G 可以应对小几千请求
那么如果访问量突然扩大 10 倍该如何应对?
对于网关、服务这些实例对象来说,可以通过添加节点,再通过 Nginx 负载均衡到不同节点,来应对突增的请求
这其实就是 横向扩容 ,网关作为应用的入口,如果支持横向扩容的话,就可以动态扩容或者缩容来应对大量的请求