 01.B 站百亿数据百万查询——关系链架构演进
01.B 站百亿数据百万查询——关系链架构演进
# B 站百亿数据百万查询——关系链架构演进
作者:刘鎏
哔哩哔哩高级开发工程师
转载自:哔哩哔哩技术
# 一、关系链业务简介
从主站业务角度来看,关系链指的是用户A与用户B的关注关系。以关注属性细分,以关注(订阅)为主,还涉及拉黑、悄悄关注、互相关注、特别关注等多种属性或状态。目前主站关系链量级较大,且还以较快速度持续增长。作为一个平台型的业务,关系链服务对外提供一对多关系点查、全量关系列表、关系计数等基础查询,综合查询峰值QPS近百万,被动态、评论等核心业务依赖。
在持续增长的数据量和查询请求的趋势下,保证数据的实时准确、保持服务高可用是关系链架构演进的核心目标。
(图:关系链在空间页的业务场景)

(图:关系链状态机)
# 二、事务瓶颈——存储的演进
# 关系型数据库
关注的写事件对应的就是单纯的状态属性流转,所以使用关系型数据库是非常适合的。在主站社区发展的早期,关系链量级较少,直接使用mysql有着天然的优势:开发维护简单、逻辑清晰,只需要直接维护一张关系表、一张计数表即可满足线上使用。考虑到社区的发展速度,前人的设计分别采用了分500表(关系表)和50表(计数表)来分散压力。

(图:关系表的结构示例)
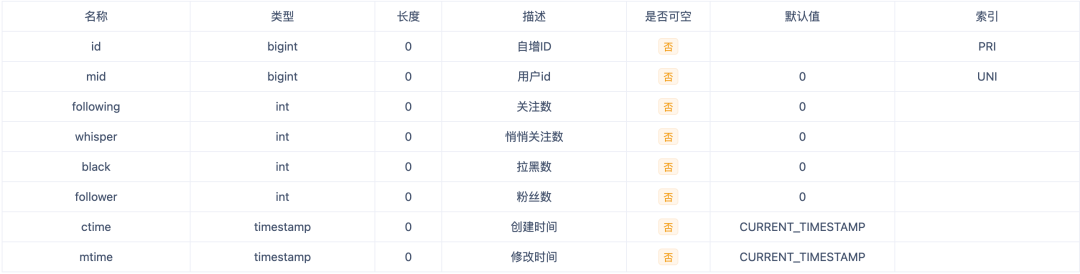
(图:计数表的结构示例)
在这种存储结构下,以一次mid新增关注fid请求为例,mysql需要以事务执行下述操作:
- 查询mid的计数并加锁,查询fid的计数并加锁;
- 查询mid->fid的关系并加锁,查询fid->mid的关系并加锁;
- 根据状态机,在内存计算新关系后,修改mid->fid的关系,修改fid->mid的关系(若有,比如由单向关注变为互关);
- 修改mid的关注数,修改fid的粉丝数;
这种架构一直保持到2021年,随着社区的不断发展壮大,架构的缺点也日益显现:一方面,即使做了分表,关系链数据整体规模仍然超出了建议的整体存储容量(目前已经TB级);另一方面,繁重的事务导致mysql无法支撑很高的写流量,在原始的同步写架构下,表现就是关注失败率变高;如果只是单纯地升级到异步写架构,表现就是消息积压,当消息积压持续时间超过临时缓存有效期时,会引起客诉,治标不治本。
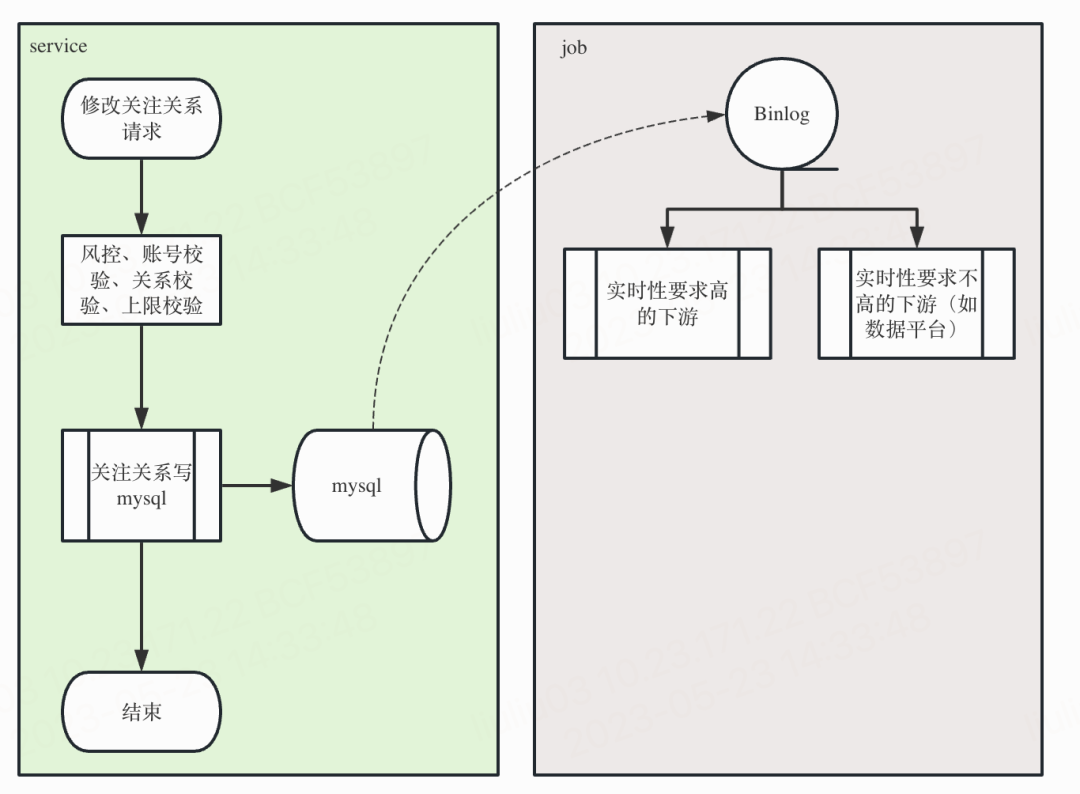
(图:使用mysql作为核心存储的“同步”写关系流程图)
# KV存储
关于B站自研分布式KV存储的介绍可以参阅:B站分布式KV存储实践 (opens new window)
最终决定使用的升级方案是:数据存储从mysql迁移到KV存储,逻辑方面把”同步写mysql“改为”异步写KV“。未选择”同步写KV“的原因,一方面是一条关系对应着多条KV记录,而KV不支持事务;另一方面是异步的架构可以扛住可能存在的瞬时大量关注请求。为了兼容订阅了mysql binlog的业务,在“异步写KV”之后还会”异步写mysql“。
在新架构下,对于每一次用户关注请求,投递databus即视为请求成功,mysql binlog只提供给一些对实时性不太敏感的业务方(如数据平台),所以对于异步写mysql事件的偶尔的轻微积压我们并不需要关心,而对实时性要求比较高的业务方,我们在处理完异步写KV事件后,会投递了databus供这些业务订阅。
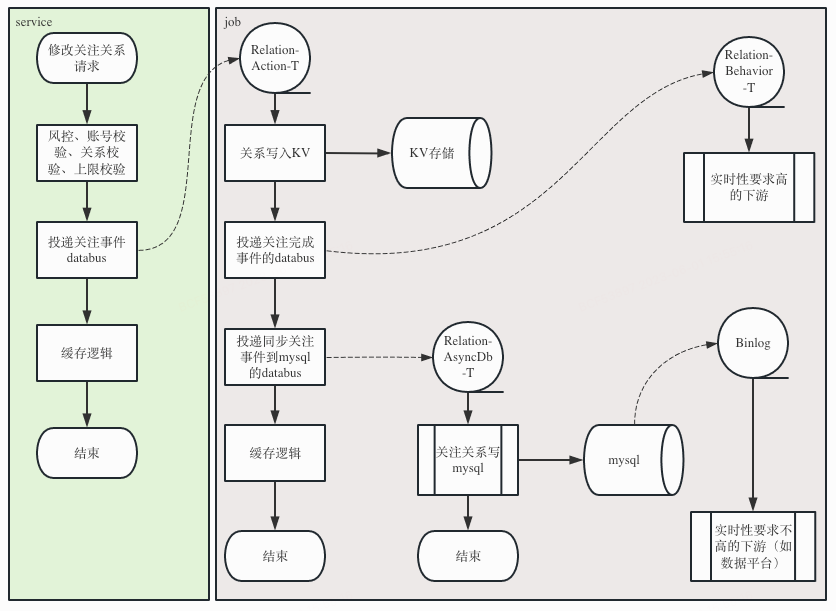
(图:使用KV作为核心存储、mysql冗余存储的异步写关系流程图)
KV存储最大的优势在于,底层能提供计数(count)方法以替代冗余的mysql计数表,这样的好处是,我们只需要维护一张单纯保存关系的KV表即可。我们设计的存储结构是:
- key为**{attr|mid}fid**,attr为关系拉链类型,mid和fid都表示用户id,{attr|mid}表示拼接attr和mid作为hash,该hash下的多个fid将按照字典序存储,结合KV服务提供的拉链遍历方法(scan),可以获取该hash下的所有的fid;
- value为结构体,包含了attribute(关系属性)和mtime(修改时间);
attr和attribute容易混淆,两者的区别如下:
key中的attr为关系拉链类型,一共有5类(3类正向关系,2类反向关系):ATTR_WHISPER表示悄悄关注类(mid悄悄关注了fid),ATTR_FOLLOW表示关注类(mid关注了fid),ATTR_BLACK表示拉黑类(mid拉黑了fid),ATTR_WHISPERED表示被悄悄关注类(mid被fid悄悄关注了),ATTR_FOLLOWED表示被关注类(mid被fid关注了)。对用户来说,各类列表和关系链类型的映射关系如下:
关注列表:根据产品需求的不同,大部分时候指关注类关系链(attr=ATTR_FOLLOW),有些场景也会加上悄悄关注类关系链(attr=ATTR_WHISPER);
粉丝列表:被悄悄关注类关系链(attr=ATTR_WHISPERED)和被关注类关系链(attr=ATTR_FOLLOWED)的合集;
黑名单列表:拉黑类关系链(attr=ATTR_BLACK)。
value中的attribute表示当前的关系属性,一共有4种:WHISPER表示悄悄关注、FOLLOW表示关注、FRIEND表示互相关注、BLACK表示拉黑。这里和前文的attr较易混淆,它们之间完整的映射关系如下:
attr=ATTR_WHISPER或ATTR_WHISPERED下可以有attribute=WHISPER;
attr=ATTR_FOLLOW或ATTR_FOLLOWED下可以有attribute=FOLLOW或者FRIEND;
attr=ATTR_BLACK下可以有attribute=BLACK。
midA的五种关系拉链如图:

(图:midA的五种关系拉链)
综上所述,升级到KV存储后,读操作相对来说并没有很复杂:
- 如果要正向查询mid与fid的关系,只需要点查(get、batch_get)遍历3种正向attr;
- 如果要查询全量关注关系、黑名单,只需要找对应attr分别执行scan;
- 如果要查询用户计数,只需要count对应的attr即可;
稍微复杂一点的逻辑在于关系的写入:
- mysql有事务来保证原子性,而kv存储并不支持事务。而对于用户的请求而言,投递databus即算关注成功,那么在异步处理这条消息时,需要100%保障成功写入,因此我们在处理异步消息时,对每个写入操作都加上了失败无限重试的逻辑。
- 极端情况下,还可能会遇到写入冲突问题:比如某个时间点用户A关注了用户B,”同时“用户B关注了用户A,此时就可能会引发一些意想不到的数据错误(因为单向关注和互关是两个不同的属性,任一方的关注行为都会影响这个属性)。为了避免这种情况出现,我们利用了消息队列同一个key下数据的有序特性,通过保证同一对用户分配到一个key,保证了同一对用户的操作是有序执行的。
还是以mid新增关注fid为例,对于每一条关注事件:
- job需要先put一条正向关注关系,然后进行上限校验,如果超过上限那么回滚退出;
- 然后批量put因本次关注动作所影响的所有其他反向attr,比如mid的被关注关系(attr=ATTR_WHISPERED)、fid的关注关系(attr=ATTR_FOLLOW,若有,比如由单向关注变为互关);
- 上述任何一个put操作失败了,都需要重试;直到这些动作都完成了,那么认为此次关注事件成功;
- 投递databus,告知订阅方发生了关注事件;
- 投递异步写mysql事件,把关注事件同步mysql,产出binlog供订阅方使用。
# 三、快速增长——缓存的迭代
# 存储层缓存memcached
线上查询请求中,有一定比例是查询全量关注列表、全量黑名单。上一节中提到,为了不冗余存储一份关系链计数,KV的存储设计得比较特殊,一个用户的正向关注关系分布在3个不同的attr(即3个不同的关系拉链)里。如果想从KV存储拉取一个用户的全量关系列表,那么同时需要分别对3种正向关系拉链都做循环scan(因为每次scan有数量上限),但由于scan方法性能相对较差,所以需要在KV存储的上层加一套缓存,通过降低回源比例严格控制scan QPS。
鉴于memcached对大key有比较好的性能,前人在KV存储的上层加了一个memcached缓存,用于存储用户的全量关系列表,具体业务流程如下:
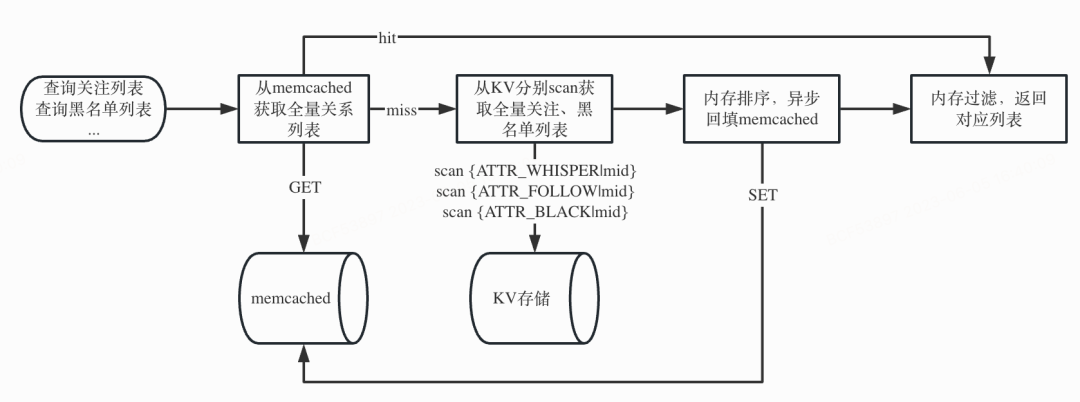
(图:全量关系列表的查询业务流程)
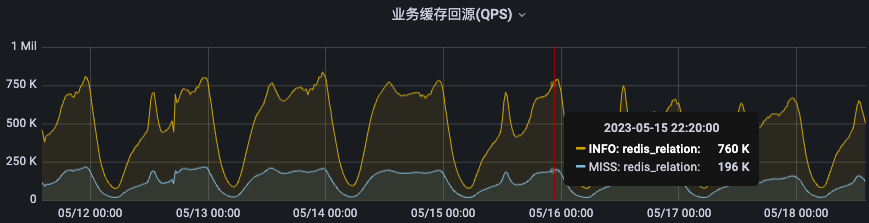
从高峰时期的缓存回源数据来看,memcached为KV存储抵挡住了97%-99%的请求,只有不到6K的QPS会miss缓存,效果比较明显。


(图:memcached的QPS和缓存回源率)
# 查询层缓存hash
除了关注列表的请求外,很大一部分请求是一对多的点查关系(查询用户和其他一个或多个用户的关系),如果每次都从memcached拉全量关系列表然后内存中取交集,网络的开销会非常大,因此对这种查询场景,也需要设计一套适用于点查的缓存。
活跃用户的关注数一般都在几十到几百的区间,用于点查的缓存不需要严格有序,但要支持指定hashkey的查询,redis hash和其提供的hget、hmget、hset、hmset方法都是非常适合这一场景的。因此查询层缓存设计如下:key为mid,hashkey为mid有关系的每一个用户id,value为他们的关系数据,和前面midA在KV存储的数据对应如下:

(图:redis hash缓存中关注关系的存储结构)
由于hash里保存的是midA的全部正向关注关系,当缓存miss需要回源时,要获取全量关注关系,可以和前面的memcached配合使用,业务流程如下:

(图:redis hash架构下的一对多关系的查询业务流程)
基于这套缓存,点查一对一、一对多关注关系的接口耗时平均基本维持在1ms,且hash的命中率能达到70%-75%,因此目前能比较轻松地支持近百万的QPS,并随着redis集群的横向扩展,可以支持更多的业务请求。
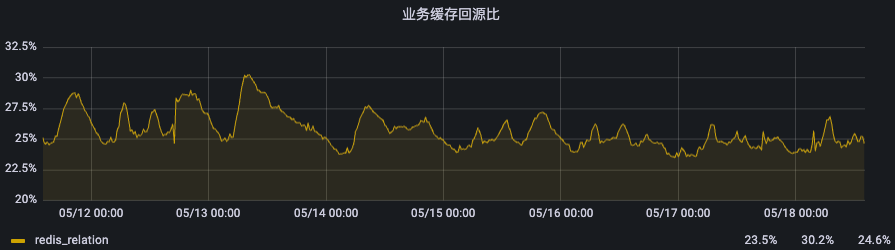
(图:redis hash缓存的QPS和缓存回源率)
# 查询层缓存kv(一次看似失败的尝试)
到2022年下半年,一方面产品提出“我关注的xx也关注了ta”需求,此类二度关系的查询在hash架构下是非常吃力的:
- 由于hash只存储了正向的关系查询,需要先获取”我“的关注列表,然后遍历查询关注列表中每个人和ta的关注关系;
- 由于”我“的关注列表中很多是非活跃用户,因此很难命中hash、memcached缓存,也就意味着每次请求都会批量并发回源KV存储。再加上推荐侧能留给关系链服务计算的时间非常短,当这一次请求超时被cancel,属于这次请求的回源KV存储的scan操作就会被全部cancel,所在实例就会触发rpc熔断事件告警,带来了大量的告警噪音(因为即使只是一个请求超时,rpc错误量是那一个请求下并发回源scan的个数)。
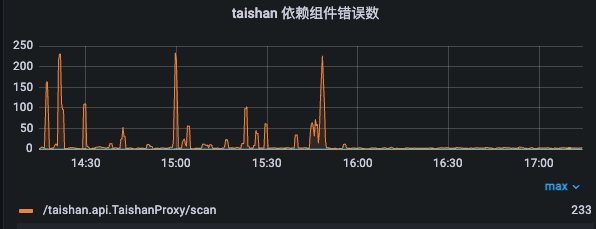
(图:切换架构前后的KV存储 scan操作RPC错误数情况)
另一方面,产品提出放开关注上限的想法,我们考虑在此类需求上线后,高关注量的用户会越来越多,甚至部分用户会在功能上线后迅速把关注拉满,hash结构的缺陷和风险也会日渐显现。其风险点在于:当同一个redis实例有多个高关注量的用户miss缓存、触发回源、hmset回填缓存时,持续性的高写入QPS可能会让redis cpu利用率打满(比如每秒2个用户需要回填缓存,且他们的关系列表5000个,实际写入QPS是1万)。
在上述大背景下,经团队内部讨论,我们先引入了redis kv结构缓存,希望能一步到位、通过简单缓存直接替换hash,key为用户A和用户B的用户id,value为用户A与用户B的关系,示例如下:

(图:redis kv缓存中关注关系的存储结构)
在这个缓存结构下,回源KV存储就只需要点查了,因为KV存储点查操作(get、batch_get)的性能远远好于scan操作,同时为了减少对memcached的依赖,因此当redis kv缓存miss时,我们直接回源KV存储执行点查(get、batch_get),然后回填缓存,流程图如下:
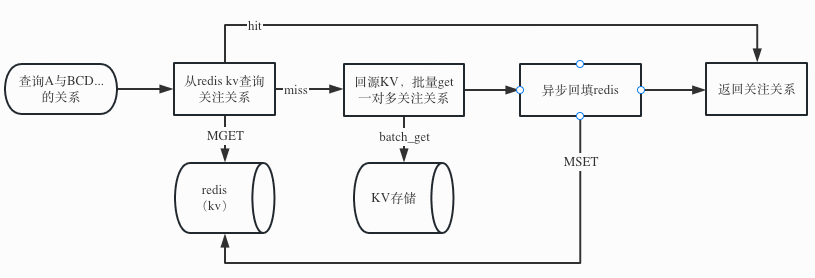
(图:redis kv架构下的一对多关系的查询业务流程)
我们灰度了2%的用户,发现kv结构缓存的命中率逐渐收敛在60%,而且缓存内存的使用率和key的数量却远远超出预期。这意味着有40%的请求会miss缓存并回源到kv,在百万QPS的压力下,这明显是不能接受的。分析miss缓存的请求后,我们发现主要的业务来源是评论,其大部分请求的返回是“无关系”,即评论场景会查询大量陌生人的关注关系,那么空哨兵会特别多且大部分不会被二次访问到(对于一个用户而言,空哨兵的数量可以认为是他看的评论用户数),这也就能对单kv结构缓存的表现做出合理解释了。
# 查询层缓存bloom_filter+kv
对于大量空哨兵场景,在上面套一层布隆过滤器是一个公认比较合理的方案。我们决定对每一个用户维护一个布隆过滤器,先把存量的所有关系链都添加到布隆过滤器,并消费新的写关系事件并更新布隆过滤器,使其作为一个常驻缓存过滤器。命中布隆过滤器有三种可能:
- 现在有关系
- 曾经有过关系,但现在没关系
- 一直没有过关系,但哈希碰撞到前面两种情况
命中布隆过滤器的才会走到下层的kv缓存,这样就解决了绝大部分空哨兵的问题了,具体流程图如下:
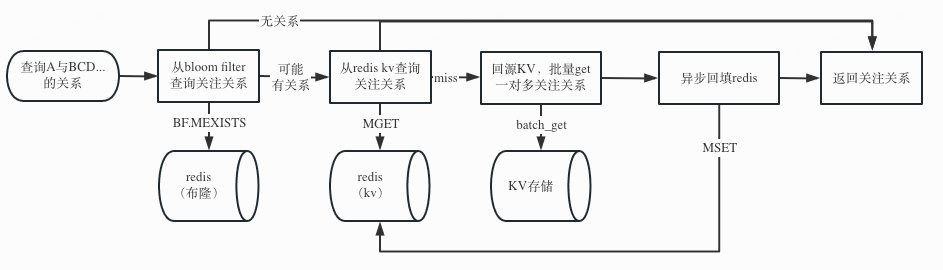
(图:bloom filter + redis kv架构下的一对多关系的查询业务流程)
目前关系链场景已经100%流量切到布隆的新架构下,布隆的命中率达到了80%+,hash的老架构正在灰度下线,这一技改不仅解决了关系链上限放开可能带来的问题、二度关系告警噪音问题、难以支持类似”多对一“的反向查询的问题,预计还能节省一部分缓存资源。
# 四、风险来临——热点的容灾
关系链的主要场景还是查询“用户A”与其他用户的关注关系。在同一时刻的请求里,当“用户A”的请求分散时,对Redis的压力会被均摊到集群的几十台实例上,此时系统所能承受的最大压力等于集群中每一个实例之和;而在极端情况下,如果“用户A”集中在少数几个用户上,那么压力都会集中在Redis的少数几台实例上,木桶短板效应就会非常明显。
回到去年的某次热点场景,流量都集中在环球网等热门up的动态详情页或稿件播放页上,而这些页面依赖实时查询up主与各个评论人的关注关系,当同一时刻大量用户加载评论时,即形成了该up主的查询热点。
当时关系链服务的架构对于热点的处理是相对滞后的,当发现热点up主(或已在事前知晓热点up主)时,会手动将其配置到热点名单中。对于热点用户,在请求Redis前会先查询本地Localcache(Localcache中存储的up主关系列表数据,隔十几秒更新一次)。虽然在这十几秒内可能会存在数据不一致的情况,但从实际业务角度看,引发热点请求的都是大up主,这些up主的关系列表较少发生变动,因此几乎不会对用户体验造成影响。
当天晚上热点请求发生时,随着用户的增长,Redis集群几个实例的CPU使用率逐步突破了70%,个别实例甚至突破了90%。

(图:热点事件当时的Redis单实例CPU使用率告警)
由于缺少热点探测能力,运维人员看到告警后,需要人工抓取当前的热点Key(在Redis实例CPU利用率已经几乎被打满的前提下,直连实例统计Key是一个高风险的操作),然后手动配置入库,随后Redis的压力就直线下降。为了避免可能存在的风险,后续又逐步把其他官媒号临时加到热点用户名单中,关系链服务算是有惊无险地度过此次流量高峰。

(图:配置本地缓存前后单实例Redis QPS)
事后,业务架构提供了热点检测工具,接入后能基于配置的阈值,自动地统计热点并临时性地使用本地缓存;在今年年初,热点检测工具和本地缓存sdk融合在了一起(*另一个本地缓存例子可以看这篇文章:B站动态outbox本地缓存优化 (opens new window)),热点自动检测与自动降级变得更加便捷,业务侧只需要简单修改本地缓存类型,即可低代码拥有防热点能力。经过英雄联盟S12和拜年祭的验证,关系链服务在上述活动期间各指标都比较平稳。
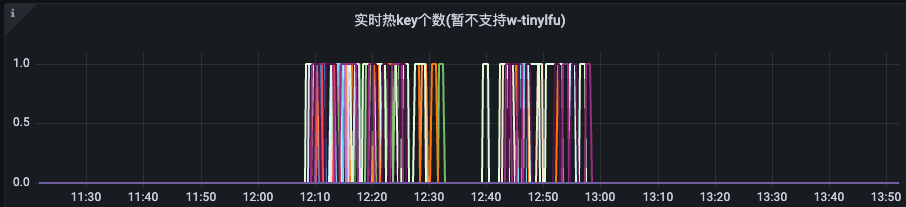
(图:某天中午被自动感知到并缓存的热key数量监控)
# 五、长远规划——关系的延伸
如何使用关系链能力赋能上层业务、如何让关系链基础服务更加靠谱,也是我们持续需要思考的问题,中期来看,还是有很多方向可以发力,这里仅列出几个方向:
- 赋能业务:以多租户的方式,通过关系链服务现有的一套代码,可以提供基础关系能力(关注/订阅、取消关注/订阅、关注列表、粉丝列表)给新的业务体系快速接入,避免二次开发。
- 赋能社区:如何让关系链这个平台服务更通用,可以尝试把关系的对象泛化,比如在动态feed场景,整合用户的泛订阅关系场景(如up主、合集、漫画、番剧、课堂等)。
- 稳定性提升:关系链服务接入业务方众多,通过0信任、100%配置quota的方式,避免业务间互相干扰,尤其避免普通业务流量暴涨影响核心业务。
参考阅读
- B站分布式KV存储实践 (opens new window)
- B站动态outbox本地缓存优化 (opens new window)
- TAO-Facebook的社交图分布式数据存储:https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf
往期精彩指路