 05.滴滴后端二面
05.滴滴后端二面
# 题目分析
# 1、如果需要做一个 starter,你会怎么去考虑、设计?
这面试官应该是想问设计 SpringBoot starter,要怎么去设计呢
这里先说一些 SpringBoot starter 是什么,这个 starter 就相当于是一个工具箱,封装一些比较通用的工具,比如果限流,基本上在所有项目中都比较常用一些,因此可以将 限流 封装成为一个 starter,以后在使用的时候,可以通过引入 starter 直接使用限流的功能,不需要再重复编写一套限流逻辑,这就是 starter 的作用
这里就以限流场景为例,说一下限流 starter 中间件的设计
先说一下限流中间件的 需求背景,在正常情况下,我们的系统访问量会维持在一个比较平稳的状态,如果有推广活动,可以通过提前报备,研发人员进行对应的扩容,而为了应对一些恶意攻击,导致系统访问量剧增的情况,我们需要一套限流机制来保证系统的平稳运行,因此,可以开发一个限流的 starter 中间件,在系统中引入,来进行一系列限流操作
接下来设计限流中间件的实现,采用 AOP + RateLimiter 来实现限流组件
首先要先自定义注解,包含两个属性值:每秒允许的请求量、访问失败时返回的结果
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface DoRateLimiter {
double permitsPerSecond() default 0D;
String errorResult() default "";
}
接下来说一下切面的实现,在切面中最后调用我们写的限流服务进行处理
@Component
@Aspect
public class DoRateLimiterPoint {
// 该切面匹配了所有带有 @DoRateLimiter 注解的方法
@Pointcut("@annotation(com.zqy.ratelimiter.annotation.DoRateLimiter)")
public void aopPoint() {}
// aopPoint() && @annotation(doRateLimiter) 这样处理,可以通过方法入参就直接拿到注解,比较方便
@Around("aopPoint() && @annotation(doRateLimiter)")
public Object doRouter(ProceedingJoinPoint jp, DoRateLimiter doRateLimiter) throws Throwable {
System.out.println("进入了切面");
IRateLimiterOpService rateLimiterOpService = new RateLimiterOpServiceImpl();
return rateLimiterOpService.access(jp, getMethod(jp), doRateLimiter, jp.getArgs());
}
private Method getMethod(JoinPoint jp) throws NoSuchMethodException {
Signature sig = jp.getSignature();
MethodSignature methodSignature = (MethodSignature) sig;
return jp.getTarget().getClass().getMethod(methodSignature.getName(), methodSignature.getParameterTypes());
}
}
接下来写一下限流服务的处理
public class RateLimiterOpServiceImpl implements IRateLimiterOpService{
@Override
public Object access(ProceedingJoinPoint jp, Method method, DoRateLimiter doRateLimiter, Object[] args) throws Throwable {
// 如果注解没有限流,则执行方法
if (0 == doRateLimiter.permitsPerSecond()) return jp.proceed();
String clzzName = jp.getTarget().getClass().getName();
String methodName = method.getName();
String key = clzzName + ":" + methodName;
// 这里用 Map 缓存一下限流器,每个方法创建一个限流器缓存
if (null == Constants.rateLimiterMap.get(key)) {
// 如果该方法没有限流器的话,就创建一个
Constants.rateLimiterMap.put(key, RateLimiter.create(doRateLimiter.permitsPerSecond()));
}
RateLimiter rateLimiter = Constants.rateLimiterMap.get(key);
// 如果没有达到限流器上限
if (rateLimiter.tryAcquire()) {
return jp.proceed();
}
// 将错误信息返回
return JSONObject.parseObject(doRateLimiter.errorResult());
}
}
如何使用限流器呢?
@RestController
public class HelloController {
@DoRateLimiter(permitsPerSecond = 1, errorResult = "{\"code\": \"1001\",\"info\": \"调用方法超过最大次数,限流返回!\"}")
@GetMapping("/hello")
public Object hello() {
return "hello";
}
}
上边限流器中核心的代码的写了出来,面试的时候肯定是不用说这么详细了,主要能说出来通过 AOP + 自定义注解实现即可
这里还有一个要注意的就是,在引入自定义的限流器中间件之后,怎么让 SpringBoot 去将切面的 Bean 给注册到 Spring 中去呢?
这里在 starter 中,还需要创建一个 /META-INF/spring.factories 文件,SpringBoot 项目在启动时会读取 spring.factories 文件,读取自动配置类,并将自动配置类给注册到 Spring 中
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.zqy.ratelimiter.config.RateLimiterAutoConfig
SpringBoot 启动时,就会将上边的 RateLimiterAutoConfig 给加载到 Spring 中去,而这个 RateLimiterAutoConfig 中就定义了切面的注册,将切面给注册到 Spring 中去,就可以生效了
@Configuration
public class RateLimiterAutoConfig {
@Bean
public DoRateLimiterPoint doRateLimiterPoint() {
System.out.println("创建了切面");
return new DoRateLimiterPoint();
}
}
Gitee 代码仓库:https://gitee.com/qylaile/rate-limiter-tool-starter
# 2、RocketMQ 延迟消息底层是怎么设计的
RocketMQ 的延迟消息还是比较常用的核心功能,底层原理其实很简单,设置好消息的延迟时间之后,将消息投入到延迟队列中去,ScheduleMessageService 是专门用于处理延迟任务的,当延迟时间到达之后,将去消费延迟消息队列中的消息并发送到原始 Topic 中,消费者就可以进行消费了

接下来详细说一下整个过程:
延迟消息的使用,通过 setDelayTimeLevel 设置延迟时间的级别,在RocketMQ 5.x 之前,只能设置固定时间的延时消息,5.x 之后,可以自定义任意时间的延时消息
这里按 5.x 之前的演示,RocketMQ 中延迟消息共有 18 个级别:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
// 设置定时的逻辑
// "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
message.setDelayTimeLevel(2);
当 Broker 收到生产者发送的延迟消息之后,并不会直接发送到指定的 Topic 中去,而是先进入到指定的延迟 Topic 中去
public static void transformDelayLevelMessage(BrokerController brokerController, MessageExtBrokerInner msg) {
if (msg.getDelayTimeLevel() > brokerController.getScheduleMessageService().getMaxDelayLevel()) {
msg.setDelayTimeLevel(brokerController.getScheduleMessageService().getMaxDelayLevel());
}
// Backup real topic, queueId
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_TOPIC, msg.getTopic());
MessageAccessor.putProperty(msg, MessageConst.PROPERTY_REAL_QUEUE_ID, String.valueOf(msg.getQueueId()));
msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties()));
// 设置延迟消息的 Topic 为:SCHEDULE_TOPIC_XXXX
msg.setTopic(TopicValidator.RMQ_SYS_SCHEDULE_TOPIC);
// 根据延迟时间的级别设置对应的 QueueId
msg.setQueueId(ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel()));
}
之后,由 ScheduleMessageService 来处理,ScheduleMessageService 是 RocketMQ 中专门用于处理延迟任务的组件,在它的 start 方法中,
public class ScheduleMessageService extends ConfigManager {
public void start() {
if (started.compareAndSet(false, true)) {
// 加载 this.delayLevelTable 的数据(key: 延迟级别,value: 延迟时间 ms)
this.load();
// 线程池
this.deliverExecutorService = new ScheduledThreadPoolExecutor(this.maxDelayLevel, new ThreadFactoryImpl("ScheduleMessageTimerThread_"));
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
if (timeDelay != null) {
// 在这提交了一个任务,用于转发延迟任务
this.deliverExecutorService.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME, TimeUnit.MILLISECONDS);
}
}
}
}
}
上边将 DeliverDelayedMessageTimerTask 任务提交给了线程池,核心方法就在 DeliverDelayedMessageTimerTask 的 run 方法中,run 方法调用了 executeOnTimeUp() 方法,在这里边就会将延迟任务给取出来,并发送到原始的 Topic 队列中去,消费者就可以消费延迟任务了
class DeliverDelayedMessageTimerTask implements Runnable {
@Override
public void run() {
// 核心方法
this.executeOnTimeUp();
}
}
# 3、那 ScheduleMessageService 怎么拉取延时消息的?
上边说了延迟消息被转发到延迟队列中去,通过 ScheduleMessageService 去拉取,这里还是先将 ScheduleMessageService 的 start 方法贴出来:
- 先通过 load 加载延迟级别对应的延迟时间的数据
- 创建有 18 个核心线程的线程池
- for 循环遍历 delayLevelTable,创建 18 个任务对每个延迟级别的任务进行处理,具体处理逻辑在 DeliverDelayedMessageTimerTask(线程) 中
public class ScheduleMessageService extends ConfigManager {
public void start() {
if (started.compareAndSet(false, true)) {
// 加载 this.delayLevelTable 的数据(key: 延迟级别,value: 延迟时间 ms)
this.load();
// 线程池
this.deliverExecutorService = new ScheduledThreadPoolExecutor(this.maxDelayLevel, new ThreadFactoryImpl("ScheduleMessageTimerThread_"));
for (Map.Entry<Integer, Long> entry : this.delayLevelTable.entrySet()) {
Integer level = entry.getKey();
Long timeDelay = entry.getValue();
Long offset = this.offsetTable.get(level);
if (null == offset) {
offset = 0L;
}
if (timeDelay != null) {
// 在这提交了一个任务,用于转发延迟任务
this.deliverExecutorService.schedule(new DeliverDelayedMessageTimerTask(level, offset), FIRST_DELAY_TIME, TimeUnit.MILLISECONDS);
}
}
}
}
}
DeliverDelayedMessageTimerTask 的 run() 中就是对延迟任务的处理,核心方法 executeOnTimeUp(),主要流程为:(这里就不列出具体的源码实现了)
- 根据 Topic 和 QueueId 找到对应的 ConsumeQueue
- 找到 ConsumeQueue 之后,根据偏移量找到消息,如果发现到达这个消息的延迟时间了,就把这个消息投递到原始的 Topic 中去,让消费者可以消费这个延迟任务
class DeliverDelayedMessageTimerTask implements Runnable {
@Override
public void run() {
// 核心方法
this.executeOnTimeUp();
}
}
# 4、MySQL 的查询能做哪些优化
这里面试官应该就是想要问一下 MySQL 的查询可以从哪些方面进行优化,这里先将思路写出来,再细说怎么优化
那么优化查询的话,毫无疑问就是通过索引来优化了,对表建立索引,还要让查询语句尽可能去命中索引
**优化一:**让查询语句尽量走 索引 的话,主要有两个方面:
- where 语句遵循最左前缀原则
- 使用覆盖索引优化
**优化二:**如果语句中,使用了 order by 的话,那么要通过 order by 和 where 的配合,让语句符合最左前缀原则,来使用索引排序(using index condition)而不是文件排序(using filesort)
下边是 8 种使用 order by 的情况,我们通过分析以下案例,可以判断出如何使用 order by 和 where 进行配合可以走using index condition(索引排序)而不是 using filesort(文件排序)
联合索引为 (name,age,position)
- case1
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' and position = 'dev' order by age;

分析:查询用到了 name 索引,从 key_len=74 也能看出,age 索引列用在排序过程中,符合最左前缀原则,使用了索引排序,因此 Extra 字段为 Using index condition
- case2
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' order by position;

分析:从 explain 执行结果来看,key_len = 74,查询使用了 name 索引,由于 order by 用了 position 进行排序,跳过了 age,不符合最左前缀原则,因此不走索引,使用了文件排序 Using filesort
- case3
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' order by age, position;

分析:查找只用到索引 name,age 和 position用于排序,与联合索引顺序一致,符合最左前缀原则,使用了索引排序,因此 Extra 字段为 Using index condition
- case4
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' order by position, age;

分析:因为索引的创建顺序为 name,age,position,但是排序的时候 age 和 position 颠倒位置了,和索引创建顺序不一致,不符合最左前缀原则,因此不走索引,使用了文件排序 Using filesort
- case5
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' and age = 18 order by position, age;

分析:与 case 4 相比,Extra 中并未出现 using filesort,并且查询使用索引 name,age,排序先根据 position 索引排序,索引使用顺序与联合索引顺序一致,因此使用了索引排序
- case6
EXPLAIN SELECT * FROM employees WHERE name = 'zqy' order by age asc, position desc;

分析:虽然排序字段列与联合索引顺序一样,但是这里的 position desc 变成了降序排序,导致与联合索引的排序方式不同,因此不走索引,使用了文件排序 Using filesort
- case7
EXPLAIN SELECT * FROM employees WHERE name in ('LiLei', 'zqy') order by age, position;
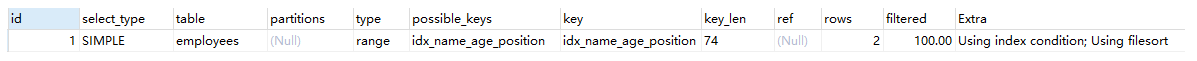
分析:先使用索引 name 拿到 LiLei,zqy 的数据,之后需要根据 age、position 排序,但是根据 name 所拿到的数据对于 age、position 两个字段来说是无序的,因此不走索引,使用了文件排序 Using filesort
为什么根据
name in拿到的数据对于 age、position 来说是无序的:对于下图来说,如果取出 name in (Bill, LiLei) 的数据,那么对于 age、position 字段显然不是有序的,因此肯定无法使用索引扫描排序

- case8
EXPLAIN SELECT * FROM employees WHERE name > 'a' order by name;

分析:对于上边这条 sql 来说,使用了 select *,因此 mysql 判断如果不走索引,直接使用全表扫描更快,因此不走索引,使用了文件排序 Using filesort
EXPLAIN SELECT name FROM employees WHERE name > 'a' order by name;

分析:因此可以使用覆盖索引来优化,只通过索引查询就可以查出我们需要的数据,不需要回表,通过覆盖索引优化,因此没有出现 using filesort
总结
- MySQL支持两种方式的排序 filesort 和 index,Using index 是指 MySQL 扫描索引本身完成排序。index 效率高,filesort 效率低。
- order by满足两种情况会使用Using index。
- order by语句使用索引最左前列。
- 使用where子句与order by子句条件列组合满足索引最左前列。
- 尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最左前缀法则。
- 如果order by的条件不在索引列上,就会产生Using filesort。
- 能用覆盖索引尽量用覆盖索引
- group by 与 order by 很类似,其实质是先排序后分组,遵照索引创建顺序的最左前缀法则。对于 group by 的优化如果不需要排序的可以加上 order by null 禁止排序。注意,where 高于 having,能写在 where 中的限定条件就不要去 having 限定了。
**优化三:**in 和 exists 的优化,原理也就是小表驱动大表,先拿到少量符合条件的数据,再去大量数据中比较,这样效率比较高
in:当 B 表的数据集小于 A 表的数据集时,使用 in
select * from A where id in (select id from B)
exists:当 A 表的数据集小于 B 表的数据集时,使用 exists
将主查询 A 的数据放到子查询 B 中做条件验证,根据验证结果(true 或 false)来决定主查询的数据是否保留
select * from A where exists (select 1 from B where B.id = A.id)
# 5、坐过高铁吧,有抢过票吗?你说说抢票会有哪些情况?
抢票会存在线程安全的问题,因为高铁票是作为一个共享的数据存在,多个线程去读写共享的数据,就会存现线程安全的问题
具体的线程不安全问题就是:高铁票的 少卖 和 超卖
先说一下整个抢票中所涉及的流程:生成订单、扣减库存、用户支付
那么为了保证高并发,扣减库存的操作可以放在本地去做,生成订单的操作通过异步,可以大幅提高系统并发度
接下来先说一下如何 优化抢票性能 :
将库存放在每台机器的本地,比如总共有 1w 个余票库存,共有 100 台机器,那么就在每台机器上方 100 个库存
当用户抢票之后,就会在本地先扣减库存,如果本地库存不足,此时可以给用户返回一个友好提示,让用户稍后再重试抢票,再将用户抢票的请求路由到其他有库存的机器上去
如果本地库存足够的话,就先扣除本地库存,之后再发送一个 MQ 消息异步的生成高铁票的订单,等待用户支付,如果用户十分钟内不支付的话,订单就失效,返还库存
接下来分析一下上边的流程是否会出现少卖和超卖的问题:
对于超卖来说,每次用户请求时,先扣除库存,再去生成订单,这样当库存不足时,就不会再生成订单了,因此肯定不会出现超卖的问题
对于少卖来说,总共有 100 台机器,每台机器有 100 个库存,如果其中的几台机器宕机了,那么宕机的机器上的库存就没办法继续售卖,就会出现少卖的问题
解决少卖问题:
可以在每台机器上放一些冗余的库存,如果其他机器发生了宕机,就将宕机的机器上的库存给放到健康的机器上去,就可以避免机器宕机而导致一部分库存卖不出去的问题了
那么这样的话,就需要使用 Redis 来统一管理每台机器上的库存,也就是在分布式缓存 Redis 中存储一份缓存,在每台机器的本地也存储一份缓存,当扣减完机器本地的库存之后,再去发送一个远程请求扣减 Redis 上的库存
最后完整的抢票流程:
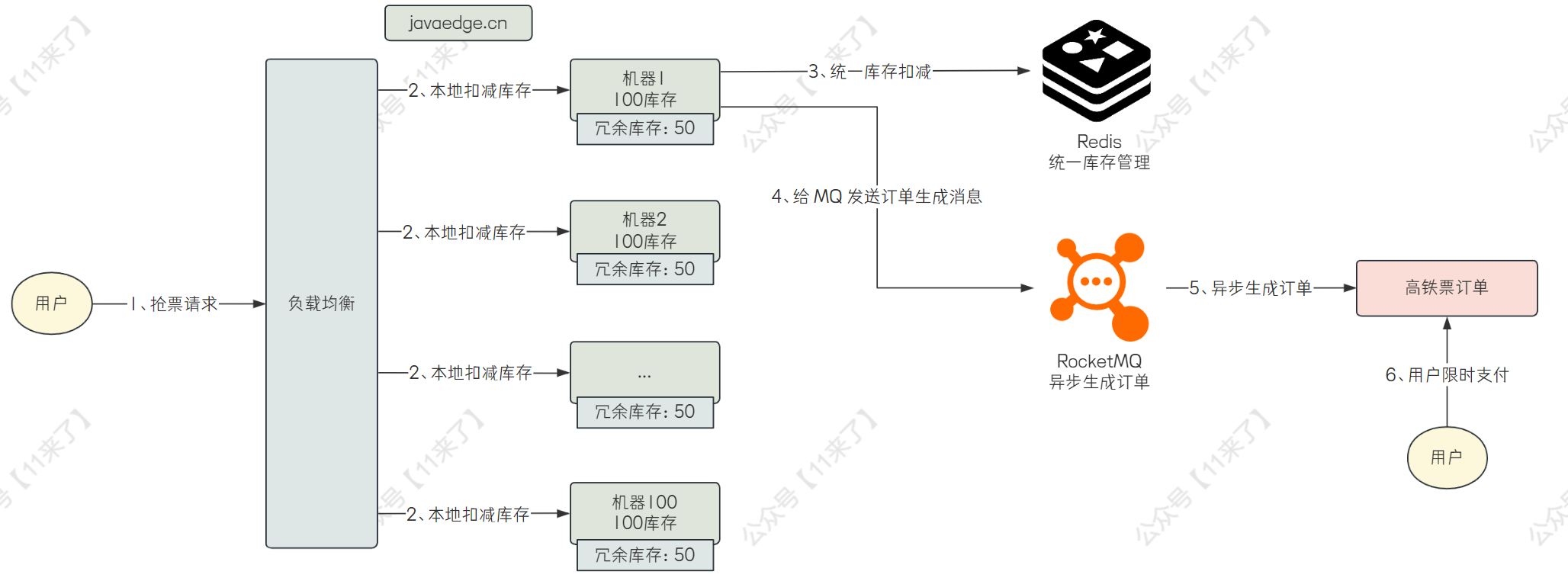
- 用户发出抢票请求,在本地进行扣减库存操作
- 如果本地库存不足,返回用户友好提示,可以稍后重试,如果所有机器上的库存都不足的话,可以直接返回用户已售罄的提示
- 如果本地库存充足,在本地扣减库存之后,再向 Redis 中发送网络请求,进行库存扣减(这里 Redis 的作用就是统一管理所有机器上的库存数量)
- 扣减库存之后,再发送 MQ 消息,异步的生成订单,之后等待用户支付即可
如有不足,欢迎指出
# 6、现在我们来给 12306 抢票系统设计一个缓存,kv 存什么?
在回答的时候,要先给面试官分析一下业务场景,再说怎么去设计缓存
在 12306 中如果要设计缓存的话,可以考虑给余票设计一个缓存,因为余票信息是读取比较多的数据,并且在首页,放在缓存中可以大大加快用户查询的速度,如下图
- 余票信息缓存
余票信息缓存的话,将车站到车站之间的信息以及余票信息给存储到缓存中,比如当用户查询 A 车站到 B 车站的车票信息时,直接从缓存中获取,如果缓存中没有的话,去数据库中查询,并且在 Redis 缓存中构建一份缓存数据
key 设计为站点的信息,比如查询 2023 年 12 月 15 日 A 车站到 B 车站的车票信息:remaining_ticket_info:{year}:{month}:{day}:{起使车站}:{终止车站}
value 为起使车站到终止车站的信息,比如车次号、余票信息、票价信息、经过车站等一些信息
这里我觉得余票数量可以和其他缓存给分开存储,因为像余票信息的话,用户购买后是需要修改的,如果将余票数量和其他缓存数据放在一起的话,每次修改的时候,都要重新构建很多数据,比较麻烦
- 余票数量缓存
余票数量缓存的 key 设计为:remaining_ticket_num:{year}:{month}:{day}:{起使车站}:{终止车站}
value :存储余票的数量

扩展:MyBatis 两级缓存
这里既然说了 Redis 缓存了,就再扩展说一下 MyBatis 的两级缓存吧
MyBatis 设计了两级缓存用于提升数据的检索效率,避免每次数据的访问都需要去查询数据库
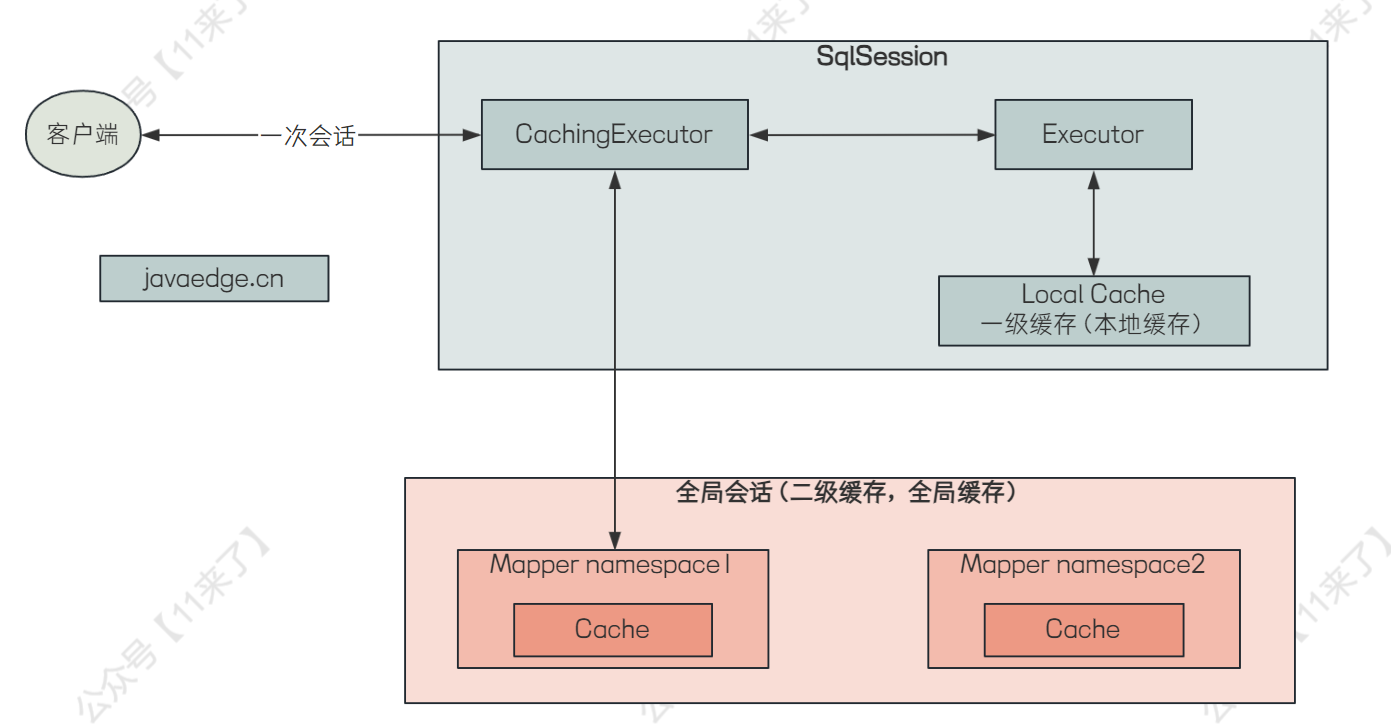
MyBatis 一级缓存:
MyBatis 中的一级缓存是会话(SqlSession)级别的,也叫本地缓存,每个用户在执行查询的时候都需要使用 SqlSession 来执行查询语句,MyBatis 将查询出来的数据缓存到 SqlSession 的本地缓存中,避免每次查询都去操作数据库
MyBatis 默认开启一级缓存
一级缓存在执行了增、删、改操作之后,缓存中的相关数据会失效并删除
MyBatis 二级缓存:
MyBatis 中的二级缓存是跨 SqlSession 级别的,一级缓存是只在当前的 SqlSession 中生效,当多个用户在查询数据时,只要有一个 SqlSession 拿到了数据就会存入到二级缓存中去,其他的 SqlSession 都可以读取到二级缓存中的数据
一级、二级缓存的缺点:
一级缓存的话是基于 SqlSession 的,如果 SqlSession 关闭,那么会导致一级缓存中的数据被清空
MyBatis 的一、二级缓存都会出现数据不一致的情况,由于 MyBatis 的缓存都是基于本地的,因此分布式环境中,多个机器的 SqlSession 修改了数据库的数据,如果有些 SqlSession 没有及时更新缓存中的数据,会导致数据不一致,产生了脏数据
一级缓存和二级缓存的使用:
一级缓存默认开启,因此不用手动去设置
二级缓存默认关闭,如果系统对数据的一致性要求不严格,那么开启二级缓存可以显著提升性能
MyBatis 查询流程:
在用户进行查询时,如果开启了二级缓存,则会先去二级缓存中进行查询,如果二级缓存中没有,再去查一级缓存,最后查询数据库
MyBatis 一二级缓存实现原理图:
一级缓存效果演示:
public class MyBatisCacheDemo {
public static void main(String[] args) {
try (InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml")) {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
// 第一次查询,会执行 SQL 并缓存结果
YourMapper mapper = sqlSession.getMapper(YourMapper.class);
User user = mapper.selectUserById(1);
// 输出第一次查询的结果
System.out.println("First query result: " + user);
// 第二次查询,由于一级缓存,不会执行 SQL,直接从缓存中获取结果
User cachedUser = mapper.selectUserById(1);
System.out.println("Second query result (cached): " + cachedUser);
// 确保两次查询返回的是同一个对象
System.out.println("Are they the same object? " + (user == cachedUser));
} finally {
sqlSession.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
# 7、那对于数据不一致我们一般怎么处理?
这里的不一致指的应该是数据库和缓存的数据不一致,这里就以商品缓存的更新举例:
如果不采用更新数据时双写来保证数据库与缓存的一致性的话,可以通过 canal + RocketMQ 来实现数据库与缓存的最终一致性,对于数据直接更新 DB,通过 canal 监控 MySQL 的 binlog 日志,并且发送到 RocketMQ 中,MQ 的消费者对数据进行消费并解析 binlog,过滤掉非增删改的 binlog,那么解析 binlog 数据之后,就可以知道对 MySQL 中的哪张表进行 增删改 操作了,那么接下来我们只需要拿到这张表在 Redis 中存储的 key,再从 Redis 中删除旧的缓存即可,那么怎么取到这张表在 Redis 中存储的 key 呢?
可以我们自己来进行配置,比如说监控 sku_info 表的 binlog,那么在 MQ 的消费端解析 binlog 之后,就知道是对 sku_info 表进行了增删改的操作,那么假如 Redis 中存储了 sku 的详情信息,key 为 sku_info:{skuId},那么我们就可以在一个地方对这个信息进行配置:
// 配置下边这三个信息
tableName = "sku_info"; // 表示对哪个表进行最终一致性
cacheKey = "sku_info:"; // 表示缓存前缀
cacheField = "skuId"; // 缓存前缀后拼接的唯一标识
// data 是解析 binlog 日志后拿到的 key-value 值,data.get("skuId") 就是获取这一条数据的 skuId 属性值
// 如下就是最后拿到的 Redis 的 key
redisKey = cacheKey + data.get(cacheField)
那么整体的流程图如下:
