 05.面试突击-下
05.面试突击-下
# 面试底层逻辑
面试官其实会根据公司的架构体系,提炼出一套符合公司体系的技术栈,再根据这些技术栈来进行面试,常见的一些如下:
Java 基础方面:Java 并发、Java 网络编程、MySQL、JDK 集合、JVM、Spring 源码、Tomcat、Linux中间件方面:Redis、MQ、Dubbo、分布式、ES可以体现过人之处的方面:生产实践、系统设计、源码了解深度
在面试中,其实面试官问的最多的还是一些基础方面的内容,只有基础方面你回答的非常好了,那么面试官才会考虑去问你更高阶的东西,所以在面试过程中,基础能力 是很重要的,也决定了面试官对你的印象怎样
而在上边列出的这么多的方面中,其中 Java 并发、MySQL、网络编程、JVM 是最基础也是最容易考察的部分,所以在学习的时候,要分好先后顺序,不要只顾上层建筑而忽略了地基
学完之后,可以拿到什么水平的 offer?
从技术角度而言,技术广度 要先达到,其次是 计算级基础的知识 是必须要掌握牢固的,比如基础的数据结构、计算机网络、操作系统方面的内容都要了解,还有就是 技术深度 (源码了解程度、项目挖掘的深度),项目经验(做的什么 2C 还是 2B 项目?哪些业务方面的项目?),以及 架构的一些设计,比如你负责了哪些项目的设计和开发,项目的架构是怎样的?系统的 QPS 是多少?巅峰期 QPS 怎样的呢?架构有多复杂?这些都是进阶内容
从综合角度而言,这方面比较看重你的 学历 以及过往的 履历,还有就是你的表达能力、性格方面是怎样的,以及对薪资的要求
如果学历是 211 本科及之上,或者履历比较优秀,进 BAT 是没有太大的问题的
如果学历一般,履历也一般,掌握这些后,对于中小型的公司的面试都可以拿下 offer
一线城市可以拿到 20k 左右
但是这要求你不仅要去学习上边列出的这些内容,还要学习之后,自己多多思考,提炼,提炼出来的这些东西,才是你真正去超越其他人的地方!
可以自己多去看一些技术书籍,多做一些积累,并且紧跟当前热点,比如 DDD 架构、云原生都比较火,那么都可以去了解一下,拓宽自己的思维
# Java 基础面试实战
Java 基础中一些常问的内容如下
HashMap 底层原理
ConcurrentHashMap 底层原理
synchronized 关键字底层原理
CAS 底层原理
AQS 实现原理
线程池的底层工作原理
Java 内存模型
volatile 关键字
Spring 的 AOP、IOC 机制的理解以及原理
JDK 中的动态代理
Spring 事务的原理?事务传播机制?
Spring 中的设计模式?
Spring 中的 Bean 是线程安全的吗?
接下来,对于上边这些问题进行解析
# HashMap、ConurrentHashMap 底层原理
HashMap 的底层原理之前我写过一篇文章,把相关的面试题都给列了出来,并且有原理解析
HashMap 这一块的内容其实就是问
- 如何计算插入元素的位置?
- 如何扩容操作?
- 插入元素的流程是怎样的?
- 如何扩容了?
- 哈希冲突了怎么办呢?
- 什么条件的时候,会从链表转成红黑树呢?
- HashMap 是线程不安全的,体现在了哪里呢?
这些内容肯定是不要求你全部背会的啊,只要面试的时候,能给面试官讲出来原理或者看着源码可以说出来就好了!
详细解析文章:HashMap源码面试解析 (opens new window)
ConcurrentHashMap 的话,也是对于初级开发、应届生面试肯定会问的东西,因为 HashMap 他就是并发不安全的,而 ConcurrentHashMap 是并发安全的,那么你肯定要去了解 ConcurrentHashMap 怎样保证了并发安全的呢?
并且 ConcurrentHashMap 在 1.7 和 1.8 对锁粒度做出了改变,这个也要清楚,JDK 1.7 中使用的是 分段锁,JDK 1.8 之后优化为了 CAS + synchronized
# ConcurrentHashMap 如何保证线程安全
这里最重要的就是,了解 ConcurrentHashMap 在插入元素的时候,在哪里通过 CAS 和 synchronized 进行加锁了,是对什么进行加锁
对于 ConcurrentHashMap 来说:
- 在 JDK1.7 中,通过
分段锁来实现线程安全,将整个数组分成了多段(多个 Segment),在插入元素时,根据 hash 定位元素属于哪个段,对该段上锁即可 - 在 JDK1.8 中,通过
CAS + synchronized来实现线程安全,相比于分段锁,锁的粒度进一步降低,提高了并发度
这里说一下在 插入元素 的时候,如何做了线程安全的处理(JDK1.8):
在将节点往数组中存放的时候(没有哈希冲突),通过 CAS 操作进行存放
如果节点在数组中存放的位置有元素了,发生哈希冲突,则通过 synchronized 锁住这个位置上的第一个元素
那么面试官可能会问 ConcurrentHashMap 向数组中存放元素的流程,这里我给写一下(主要看一下插入元素时,在什么时候加锁了):
根据 key 计算出在数组中存放的索引
判断数组是否初始化过了
如果没有初始化,先对数组进行初始化操作,通过 CAS 操作设置数组的长度,如果设置成功,说明当前线程抢到了锁,当前线程对数组进行初始化
如果已经初始化过了,判断当前 key 在数组中的位置上是否已经存在元素了(是否哈希冲突)
如果当前位置上没有元素,则通过 CAS 将要插入的节点放到当前位置上
如果当前位置上有元素,则对已经存在的这个元素通过 synchronized 加锁,再去遍历链表,通过将元素插到链表尾
6.1 如果该位置是链表,则遍历该位置上的链表,比较要插入节点和链表上节点的 hash 值和 key 值是否相等,如果相等,说明 key 相同,直接更新该节点值;如果遍历完链表,发现链表没有相同的节点,则将新插入的节点插入到链表尾即可
6.2 如果该位置是红黑树,则按照红黑树的方式写入数据
判断链表的大小和数组的长度是否大于预设的阈值,如果大于则转为红黑树
当链表长度大于 8 并且数组长达大于 64 时,才会将链表转为红黑树
这里推荐一篇文章,源码解析讲的非常清楚:马士兵教育-郑金维老师-ConcurrentHashMap源码解析 (opens new window)
# 并发编程面试实战
面试官为什么都喜欢问并发编程的问题?
如果面试的大一点的公司,用户量上来之后,那么并发包下的东西还是很容易会用到的,并且写代码时,如果对并发安全不算了解,那可能写完的代码存在许多并发上的问题,可能测试的时候没问题,到生产环境中造成严重后果!
我之前面试过唯品会,唯品会的面试官给我的印象就是很在乎你的基础,无论是并发、JVM、MySQL、Redis 原理,还是项目中使用到的技术,都会问你底层原理,我面试之后也问面试官了,为什么偏向于去问这么多技术的底层原理,面试官给的回答是因为只有了解底层的原理,你在使用的过程中才会更加注意他存在哪方面的问题,可以更好的去避免!
对于并发编程这块的内容,synchronized、CAS、AQS 的原理之前也写过一篇文章,详细内容可以点击:Java并发编程-synchronized解析 (opens new window)
# synchronized 底层原理
说说synchronized关键字的底层原理是什么?
下面来用 大白话 说一下原理:
synchronized 保证线程同步主要是依赖于两个 jvm 的指令:monitorenter、monitorexit 来实现的,比如说 synchronized 修饰一个代码块,那么进入代码块之前,执行 monitorenter 表示上锁,退出代码块之后,执行 monitorexit 表示解锁,以此来保证不同线程顺序执行这个代码块
并且 synchronized 在 jdk1.6 进行了优化,将锁分为了四种状态:无锁、偏向锁、轻量级锁、重量级锁,这 4 个状态会随着竞争激烈而逐渐升级,不过偏向锁在 jdk15 之后逐渐废弃,因为维护的开销比较大
# CAS 底层原理
能聊聊你对CAS的理解以及其底层实现原理可以吗?
CAS 操作需要 3 个参数:要写入的内存地址、预期值、要写入的值
CAS 的原理就是,去要写入的内存地址判断,如果这个值等于预期值,那么就在这个位置上写上要写入的值
CAS 存在一些缺陷:
循环时间过长:如果 CAS 自旋一直不成功,会给 CPU 带来很大开销
只能针对一个共享变量
存在 ABA 问题:CAS 只检查了值有没有发生改变,如果原本值为 A,被改为 B 之后,又被改为了 A,那么 CAS 是不会发现值被改编过了的
ABA 问题解决方案:为每个变量绑定版本号,A–>B–>A 加上版本号为:A1–>B2–>A3
# AQS 底层原理
了解 AQS 吗?底层原理是什么?
AQS 是抽象队列同步器,其实就是一个队列,存储的是线程,AQS 的作用就是 去管理线程加锁和解锁时的阻塞、唤醒
AQS 的原理:线程在获取锁失败之后,会被封装成 Node 节点假如到 AQS 阻塞等待,当获取锁的线程释放锁之后,会从 AQS 队列中唤醒一个线程,AQS 队列如下:
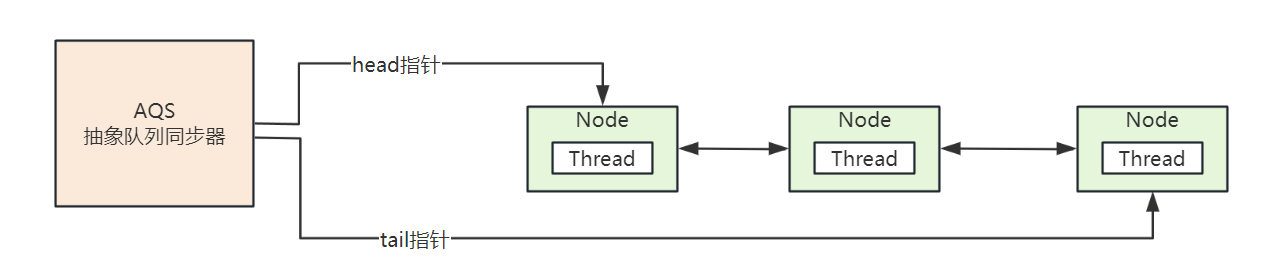
这里推荐一篇讲解 AQS 源码非常好的文章:AQS源码详细解析参考文章 (opens new window)
# 线程池的底层工作原理面试实战
接下来就不对线程池的细节进行讲解了,如果想要查看可以点击:线程池底层原理细节 (opens new window)
线程池其实就是对线程做一个 池化 操作,用于线程不断创建、销毁的开销,可以重复利用线程,节省资源
线程池中的重要参数如下:
corePoolSize:核心线程数量maximumPoolSize:线程池最大线程数量 = 非核心线程数+核心线程数keepAliveTime:非核心线程存活时间unit:空闲线程存活时间单位(keepAliveTime单位)workQueue:工作队列(任务队列),存放等待执行的任务threadFactory:线程工厂,创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。handler: 拒绝策略 ,如果阻塞队列满了之后,对于新加入的任务该如何处理
除了线程池的核心参数要掌握,任务提交到线程池中的执行流程也要了解:
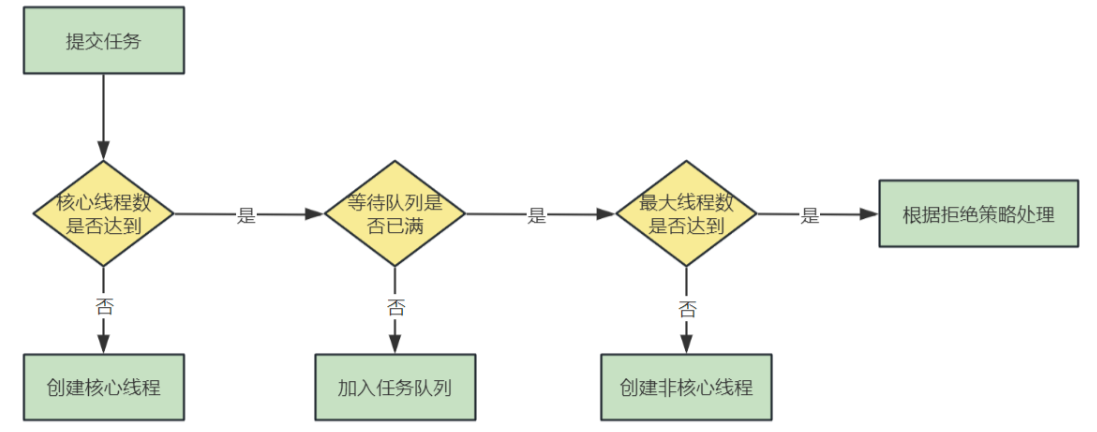
# 线程池参数设置攻略
下边以几种设置的例子,来说明一下会出现的情况:
- 如果将 maximumPoolSize 设置为 Integer.MAX_VALUE
这时,如果瞬间任务很多,核心线程都被占用,那么会无限创建线程去处理任务,导致消耗系统不断消耗资源去创建大量线程,如果任务提交速度大于线程处理速度,系统资源很快就会被耗尽,即使内存没有崩溃,也会导致 CPU 负载很高,所以要避免将 maximumPoolSize 设置的无限大
- 如果在线程中使用无界阻塞队列
如果发生了调用超时,导致队列越来越大,那么会导致任务一直向阻塞队列中存放,内存飙升,甚至出现 OOM 问题
- 自定义拒绝策略
其实可以自己去定义拒绝策略,如果线程池无法处理更多的任务了,可以在自定义的拒绝策略中,将拒绝的任务异步化持久化到磁盘中去,之后再通过一个后台线程去定时扫描这些被拒绝的任务,慢慢执行
# 如果机器宕机,线程池中请求会丢失吗?
如果线上机器突然宕机,线程池的阻塞队列中的请求怎么办?
如果宕机,重启之后,线程池阻塞队列中的任务就会全部丢失
如果想要解决这种情况的话,有这么一个 解决方案:在将任务提交到线程池中去的时候,先把任务在数据库中存储一份,并记录任务执行的状态:未提交、已提交、已完成,执行完之后的话,将任务状态标记为 已完成,如果宕机后,导致任务丢失,就可以去数据库中扫描任务,重新提交给线程池执行
# Java 内存模型面试实战
这块属于是 JVM 中的内容了,JVM 中的面试内容也是比较多的,包括常用的垃圾回收算法、垃圾回收器、堆、栈等等..
Java 内存模型(即 JMM)是在 《Java 虚拟机规范》 中定义的,目的是:定义程序中各种变量的访问规则,即关注在虚拟机中把变量值存储到内存和从内存中取出变量值这样的底层细节
JMM 规定了所有变量存储在主内存,每个线程都有自己的工作内存,线程 A 和线程 B 如果需要通信的话,需要经过 2 个步骤:
- 线程 A 把工作内存 A 中更新过的值刷新到主内存中
- 线程 B 去主内存中读取线程 A 刚更新过的值

# 原子性、有序性、可见性
Java 内存模型中的原子性、有序性、可见性是什么?
原子性:一个操作以原子的方式执行,要么该操作不执行,要么执行过程中不可以被其他线程中断,就比如多线程环境下,i++ 必须是独立执行的,因为 i++ 不是原子操作,如果多线程同时执行,就会出现问题可见性:多个线程共享一个变量时,需要保证其中一个线程修改变量之后,被其他线程所感知到,并及时读取变量最新值有序性:指程序执行的顺序按照代码的先后顺序执行。在并发环境中,为了提高效率,编译器和处理器可能会对代码进行重排序,但是这种重排序不会影响单线程程序的执行,却可能影响到多线程并发执行的正确性
# volatile 底层原理
如果面试中问到了 volatile 关键字,应该从 Java 内存模型开始讲解,再说到原子性、可见性、有序性是什么
之后说 volatile 解决了有序性和可见性,但是并不解决原子性
volatile 可以说是 Java 虚拟机提供的最轻量级的同步机制,在很多开源框架中,都会大量使用 volatile 保证并发下的有序性和可见性
volatile 实现
可见性和有序性就是基于内存屏障的:
内存屏障是一种 CPU 指令,用于控制特定条件下的重排序和内存可见性问题
- 写操作时,在写指令后边加上 store 屏障指令,让线程本地内存的变量能立即刷到主内存中
- 读操作时,在读指令前边加上 load 屏障指令,可以及时读取到主内存中的值
JMM 中有 4 类内存屏障:(Load 操作是从主内存加载数据,Store 操作是将数据刷新到主内存)
LoadLoad:确保该内存屏障前的 Load 操作先于屏障后的所有 Load 操作。对于屏障前后的 Store 操作并无影响屏障类型StoreStore:确保该内存屏障前的 Store 操作先于屏障后的所有 Store 操作。对于屏障前后的Load操作并无影响LoadStore:确保屏障指令之前的所有Load操作,先于屏障之后所有 Store 操作StoreLoad:确保屏障之前的所有内存访问操作(包括Store和Load)完成之后,才执行屏障之后的内存访问操作。全能型屏障,会屏蔽屏障前后所有指令的重排
在字节码层面上,变量添加 volatile 之后,读取和写入该变量都会加入内存屏障:
读取 volatile 变量时,在后边添加内存屏障,不允许之后的操作重排序到读操作之前
volatile变量读操作
LoadLoad
LoadStore
写入 volatile 变量时,前后加入内存屏障,不允许写操作的前后操作重排序
LoadStore
StoreStore
volatile变量写操作
StoreLoad
# happens-before 原则
接下来了解一下 happens-before 是什么?
happens-before 原则是对 Java 内存模型的简化,帮助编程人员理解并发安全,happens-before 定义了一些规则,只要符合了这些规则,这些执行的先后关系就已经被确定了,不需要再通过 volatile 和 synchronized 来保证有序性,如果不符合这些规则,那么它们的执行就没有顺序性的保障,虚拟机可能会进行重排序!
- 程序次序规则(Program Order Rule):在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。准确地说,应该是控制流顺序而不是程序代码顺序,因为要考虑分支、循环等结构。
- 管程锁定规则(Monitor Lock Rule):一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。这里必须强调的是同一个锁,而 “后面” 是指时间上的先后顺序。
- volatile 变量规则(Volatile Variable Rule):对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作,这里的 “后面” 同样是指时间上的先后顺序。
- 线程启动规则(Thread Start Rule):Thread 对象的 start () 方法先行发生于此线程的每一个动作。
- 线程终止规则(Thread Termination Rule):线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过 Thread.join () 方法结束、Thread.isAlive () 的返回值等手段检测到线程已经终止执行。
- 线程中断规则(Thread Interruption Rule):对线程 interrupt () 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 Thread.interrupted () 方法检测到是否有中断发生。
- 对象终结规则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize () 方法的开始。
- 传递性(Transitivity):如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那就可以得出操作 A 先行发生于操作 C 的结论。
对于 happens-before 原则,不需要记它具体有哪些规则,也根本记不住,只要了解 happens-before 包括了一些规则,符合这些规则的情况下,有序性就已经被保证了,那么就不需要通过 volatile 去保证有序性
# 为什么需要 happens-before 原则呢?
这里也是为了大家理解,说一下为什么会需要这个原则
如果在 Java 内存模型中,所有代码的有序性都依靠 volatile 和 synchronized 去保证,那么很多操作将会变得非常罗嗦
而我们在编写代码时,并没有使用很多的 volatile 和 synchronized 去保证有序性,就是因为 Java 语言中的 happens-before 原则的存在
通过这个原则,就可以很快判断并发环境中,两个操作之间是否会存在冲突的问题
# Spring 面试实战
Spring 在面试中考察的概率也是比较大的,这部分主要对 Spring 中可能出现的面试题做一个分析
# 谈一谈对 Spring IOC 的理解
Spring IOC 是为了去解决 类与类之间的耦合 问题的
如果不用 Spring IOC 的话,如果想要去使用另一个类的对象,必须通过 new 出一个实例对象使用:
UserService userService = new UserServiceImpl();
这样存在的问题就是,如果在很多类中都使用到了 UserServiceImpl 这个对象,但是如果因为变动,不去使用 UserServiceImpl 这个实现类,而要去使用 UserManagerServiceImpl 这个实现类,那么我们要去很多创建这个对象的地方进行修改,这工作量是巨大的
有了 IOC 的存在,通过 Spring 去统一管理对象实例,我们使用 @Resource 直接去注入这个
@Resource
UserService userServiceImpl;
如果要切换实现类,通过注解 @Service 来控制对哪个实现类进行扫描注册到 Spring 即可,如下
@Controller
public class UserController {
@Resource
private UserService userService;
// 方法...
}
public class UserService implements UserService {}
@Service
public class UserManagerServiceImpl implements UserService {}
# 谈一谈对 Spring AOP 的理解
Spring AOP 主要是 去做一个切面的功能 ,可以将很多方法中 通用的一些功能从业务逻辑中剥离出来 ,剥离出来的功能通常与业务无关,如 日志管理、事务管理等,在切面中进行管理
Spring AOP 实现的底层原理就是通过动态代理来实现的,JDK 动态代理和 CGLIB 动态代理
Spring AOP 会根据目标对象是否实现接口来自动选择使用哪一种动态代理,如果目标对象实现了接口,默认情况下会采用 JDK 动态代理,否则,使用 CGLIB 动态代理
JDK 动态代理和 CGLIB 动态代理具体的细节这里就不讲了,可以参考之前我写的文章:JDK和CGLIB动态代理 (opens new window)
# Spring 的 Bean 是线程安全的吗?
能说说 Spring 中的 Bean 是线程安全的吗?
首先来分析一下什么时候会线程不安全,如果每个线程过来操作都创建一个新的对象,那么肯定不对出现线程安全的问题,如果多个线程操作同一个对象,那么就会出现线程不安全问题
而 Spring 中的 Bean 默认是 单例 的,也就是在 Spring 容器中,只有这一份 Bean 对象,每个线程过来都是操作这一份变量,那么肯定是线程不安全的
# Spring 的事务实现原理
Spring 事务的实现原理了解过吗?
Spring 的事务就是通过 动态代理 来实现的,如果开启事务,会在整个事务方法执行之前开启事务,如果执行过程中出现异常,将事务进行回滚,如果没有异常就提交事务,这些对事务的操作是业务无关的,因此在动态代理中执行
# Spring 事务的传播机制
Spring 中事务的传播机制了解吗?
Spring 事务的传播机制就是定义在多个事务存在的时候,Spring 该如何去处理这些事务的行为
事务传播机制有以下 7 种:
PROPAGATION_REQUIRED:如果当前没有事务,就新建一个事务,如果当前存在事务,就加入该事务。这是最常见的选择,也是 Spring 默认的事务的传播PROPAGATION_REQUIRES_NEW:新建事务,无论当前是否存在事务,都会创建新的事务,新建的事务将和外层的事务没有任何关系,是两个独立的事务,外层事务失败回滚之后,不能回滚内层事务执行的结果,内层事务失败抛出异常,外层事务捕获,也可以不处理回滚操作PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前没有事务,就以非事务方式执行PROPAGATION_NESTED:如果当前事务存在,则运行在一个嵌套的事务中。如果当前没有事务,则按 REQUIRED 属性执行PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前没有事务,就抛出异常PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
其中常用的事务传播机制就是前边 4 种,下边解释一下:
对于 PROPAGATION_REQUIRED 来说,是默认的事务传播机制,比如 A 方法调用 B 方法,A 方法开启了事务,那么 B 方法会加入 A 方法的事务,A 方法或 B 方法种只要出现异常,这个事务就会回滚
对于 PROPAGATION_REQUIRES_NEW 来说,如果 A 方法开启事务,A 方法调用 B 方法,A 方法的事务级别为PROPAGATION_REQUIRED,B 方法的事务级别为 PROPAGATION_REQUIRES_NEW,那么执行到 B 方法时,A 方法的事务就会挂起,给 B 方法创建一个新的事务开始执行,此时 A 和 B 是不同的事务,当 B 的事务执行完毕之后,在执行 A 的事务(每次创建的事务都是一个新的物理事务,也就是每创建一个新的事务,都会为这个事务绑定一个新的数据库连接)
对于 PROPAGATION_SUPPORTS 这个事务级别很简单,这里也不说了,看上边的说明也能看懂
对于 PROPAGATION_NESTED 来说,如果 A 方法开启事务,A 方法调用 B 方法,A 方法的事务级别为PROPAGATION_REQUIRED,B 方法的事务级别为 PROPAGATION_NESTED,如果执行 B 方法出现异常,B 方法会回滚,而在 A 方法的事务可以选择回滚也可以选择不回滚,当 B 的事务开始执行时,它将取得一个 savepoint,当 B 的事务执行失败,会回滚到这个 savepoint 上,B 的事务是 A 事务的一部分,当 A 事务执行结束之后才会去提交 B 事务
其中 PROPAGATION_REQUIRED 和 PROPAGATION_NESTED 这两个比较类似,不过 NESTED 使用了保存点(savepoint),事务可以回滚到 savepoint,而不是回滚整个事务
事务传播机制总结:
面试的时候,肯定不会一个一个去问你,某一个事务传播机制对应的特性是什么,这样问也没有意义
把常用的 4 个事务传播机制给记住,面试官问的话,可能会这么去问:
现在有两个方法 A 和 B,A 调用 B,如果希望 A 出错了,此时仅仅回滚 A 方法,而不去回滚 B 方法,那么需要使用哪一种传播机制呢?
当然是使用 PROPAGATION_REQUIRES_NEW 让两个事务之间独立即可
如果希望出现异常的时候,B 方法只可以回滚自己,而 A 方法可以带着 B 方法回滚,该使用哪一种传播机制呢?
那当然使用 PROPAGATION_NESTED 了,嵌套事务,内部事务会在外部事务执行之后,才决定是否提交
# Spring 中的设计模式
Spring 中使用了哪些设计模式?
这个其实出现的频率也是比较高的,因为设计模式本来就很容易问,结合上 Spring 正好充当一个提问的背景
问 Spring 中使用了哪些设计模式,用的最多的就是:工厂模式、单例模式、代理模式
工厂模式,其实就是在 Spring IOC 中使用了,IOC 其实就是通过一个大的工厂管理 Spring 中所有的 Bean,如果需要使用 Bean,去工厂中获取单例模式,Spring 中的 Bean 都是作为单例存在的,确保了每个类在系统运行期间都只有一个实例对象,这个就是通过单例模式来实现的,之前我面试的时候问到单例模式时,面试官还让手写了单例,这个一定要掌握一下,这里写一种单例的实现:
public class SingletonDemo {
private static volatile UserService userService;
public static UserService getInstance() {
if (userService == null) {
synchronized (UserService.class) {
// 双端检锁
if (userService == null) {
userService = new UserServiceImpl();
}
}
}
return userService;
}
}
代理模式,主要体现在 Spring AOP 中,通过动态代理为其他对象创建一个代理对象,来控制对其他对象的访问,可以通过代理模式添加一些业务无关的通用功能
# 计算机网络面试实战
为什么要学习网络相关知识?
对于好一些的公司,计算机基础的内容是肯定要面的,尤其是 30k 以内的工程师,因为目前处于的这个级别肯定是要去写项目的,还没上升到去设计架构的高度,因此不可避免地要和机器、网络、cpu、磁盘、内存打交道,就比如线上机器 cpu 负载 100% 了怎么办呢?内存使用率过高怎么办?
对于这些问题,必须依靠计算机基础才可以去解决,并且如果不了解这些,以后如果去带头做一个项目,在生产环境稍微碰到一些相关问题,根本也就不知道怎么去解决,所以对于计算机基础的内容一定要好好掌握!
# 计算级网络的模型
计算级网络的模型有 OSI 七层模型和 TCP/IP 四层模型,而 OSI 七层模型是先出现的理论模型,再进行实践,而 TCP/IP 是参考 OSI 七层模型,先有了协议和应用再提出了四层模型,目前 TCP/IP 四层模型被广泛使用就是因为 OSI 七层模型实践之前,TCP/IP 四层模型就已经广泛使用了,已经成为了流行的网络模型,当 OSI 七层模型的具体协议及应用出来的时候,市场已经被 TCP/IP 所霸占了
OSI 七层模型:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层
TCP/IP 四层模型:应用层、传输层、网络层、链路层、物理层
我之前也写了一篇文章,详细写了每一层具体是做什么的,以及每一层的协议,TCP 和 UDP 等等:网络相关面试题 (opens new window)
这里也简单写一下每一层到底是做什么的,了解一下有个大概的感觉即可:
物理层:通过物理介质,光缆等介质传输电路信号,二进制 0 和 1 在物理层被转换为电路信号进行传输数据链路层:通过物理层传输了电路信号,但是并不知道电路信号的含义,数据链路层将电路信号翻译为 0 和 1,并且将电路信号分组,知道哪些 0 和哪些 1 是同一组的,网络交换机工作在数据链路层,主要是用在局域网的通信,在传输数据包时是通过 mac 地址进行接收的,如果一个电脑发个数据包出去,会广播给局域网内的所有机器设备的网卡,每台机器都从数据包中取出 mac 地址和自己的 mac 地址比较,如果一样,表示是给自己发送的数据包网络层:在数据链路层是通过广播给局域网的机器来发送数据包的,那么如何区分局域网呢?就是通过网络层中 IP 协议的 IP 地址来区分的,也就是通过子网掩码来判断哪些 IP 属于同一个子网,路由器工作在网络层,通过路由器就可以连入英特网,也就是常说的“你的电脑可以上网了”,你如果要和另一个局域网上的电脑进行通信,那么就是通过路由器转发数据包的,先是通过交换机将数据转发送给路由器,路由器收到数据包之后,再次通过交换机将数据包发送给另一个局域网上的路由器,之后再转发给目标电脑传输层:在一台机器上是同时有多个进程使用一个网卡进行通信的,比如 QQ、微信,但是这些进程的端口号不同,网络层是基于 ip 协议进行主机间的寻址和通信的,那么传输从就是基于端口号来进行两个主机的端口之间的连接和通信,其中 udp 和 tcp 就是传输层的协议会话层:会话层用于建立连接、管理连接、发送和接收数据,在客户端和服务器建立会话之前,服务端会对客户端进行身份验证并且授权表示层:表示层从应用层接收数据,这些数据以字符和数字的形式出现,表示层将这些字符和数据转成二进制,在传输数据之前,表示层将原始数据进行压缩,可以加快传输,并且保证完整性数据传输前的数据加密,在发送端,数据在表示层会被加密,在接收端,数据在表示层会进行解密操作应用层:应用层是由网络应用程序使用的,是离用户最近的一层,应用层通过各种协议,为网络应用提供服务,常见协议如下:- FTP - 文件传输协议
- HTTP/S - 超文本传输(安全)协议
- SMTP - 邮件发送协议:用于与邮件服务器建立通信,并处理电子邮件的发送操作
- POP3 - 邮件接收协议:用于与邮件服务器建立通信,并且从服务器中检索邮件
- Telnet : 与虚拟段之间的通信协议
# 浏览器请求 www.baidu.com 的流程
首先,假设我们电脑配置如下:
- ip 地址:192.168.30.30
- 子网掩码:255.255.255.0
- 网关地址:192.168.30.1
- DNS 地址:8.8.8.8
当我们通过域名 www.baidu.com 进行访问时,首先会找到 DNS 服务器 解析域名得到对应的 ip 地址,这里假设为 172.194.17.109
之后判断本机 ip 与目的地址的 ip 是否处于同一子网,显然不在一个子网,一个 192 开头,另一个 172 开头(根据子网掩码判断),那么就将数据包发送给 网关
那么浏览器要访问一个网站,是基于应用层的 http 协议 的,并且要将浏览器发出的请求封装成应用层数据包,如下

那么这个数据包就会由应用层向下传输,到表示层、会话层、传输层,到达 传输层 之后,传输层的 TCP 协议需要去 设置数据包的端口号,发送方的端口号随机算一个,接收方的端口号一般默认是 80
之后数据包由到了网络层,通过 IP 协议,将数据包进一步封装,添加上 IP 协议所需的本机 IP 地址和目的 IP 地址,之后判断如果两台机器不在同一个子网内的话,就将数据包先广播到网关中去,通过网关发送给目的地址
接下来到了数据链路层,将网络层的数据包进一步封装,并加上本机 mac 地址和网关的 mac 地址,这里封装好的就是 以太网数据包,大小限制为 1500 字节,如果超过网络层传输下来的数据包超过 1500 个字节,需要切分为多个数据包传输
之后你发送的请求就可以发送到目标电脑了
# Https 的工作原理
Http 的内容是明文传输的,铭文数据经过中间代理服务器、路由器、wifi 热点等多个物理节点,如果被劫持会导致传输内容完全暴露,因此需要对信息进行加密
Https 是一种通过计算机网络进行安全通信的传输协议,Https 经由 Http 进行通信,利用 SSL/TLS 来加密数据包,HTTPS 在内容传输的加密上使用的是 对称加密,非对称加密 只作用在证书验证阶段
Https 的信任基于预先安装在操作系统中的证书颁发机构(CA)
那么通过 Https 进行通信的流程如下:
证书验证阶段
- 浏览器发起 Https 请求
- 服务端返回 Https 证书
- 客户端验证证书是否合法,如果不合法则提示告警
数据传输阶段
- 当证书验证合法后,在本地生成随机数
- 通过公钥加密随机数,并把加密后的随机数传输到服务端
- 服务端通过私钥对随机数进行解密
- 服务端通过客户端传入的随机数构造对称加密算法,对返回结果内容进行加密后传输
具体的一些细节可以了解一下,我也发现了一篇比较好的文章,可以看一下:彻底搞懂HTTPS的加密原理 (opens new window)
# 为什么要网络分层?
网络分层可以简化复杂性,提高 模块化程度 和 可维护性
分层之后,各个层次负责特定的功能,每一层不需要关心上层或下层的具体细节,如果需要修改,直接对某个层进行修改即可,不会影响到其他层,这种模块化设计可以使网络系统扩展性更强
并且在网络出现问题时,由于分层的设计,可以根据每一层的职责更容易地定位到问题所在的层次,而不需要了解整个系统
# 网络模型中各层都有哪些协议?
物理层和数据链路层比较偏向于底层,就不说了
网络层主要的协议有:
- IP 协议:互联网协议(IP)是网络层的核心协议,负责将数据包从源地址传输到目的地址
- ICMP 协议:互联网控制消息协议(ICMP)用于在网络设备之间传递控制消息,如错误报告、网络不可达、重定向等。它帮助网络设备诊断和处理网络问题
- IGMP 协议:互联网组管理协议(IGMP)用于在主机和相邻的路由器之间建立多播组成员关系。它允许主机加入或离开多播组,以便接收特定类型的数据包
- OSPF 协议:开放最短路径优先(OSPF)是一种内部网关协议(IGP),用于在自治系统(AS)内部的路由器之间交换路由信息,以确定最短路径
传输层主要的协议有:
- TCP 协议:传输控制协议(TCP)提供了一种可靠的、面向连接的服务。它确保数据按顺序到达目的地,并且没有丢失或损坏
- UDP 协议:用户数据报协议(UDP)提供了一种无连接、不可靠的服务。它比TCP更快,但不保证数据的完整性和顺序
会话层主要的协议有:
- RPC(Remote Procedure Call):远程过程调用(RPC)允许程序在一个网络上的客户端请求另一个网络上的服务器执行特定的任务或操作
- NCP 协议:网络控制协议(NCP)是早期网络协议,用于在客户端和服务器之间建立会话。它在现代网络中已经很少使用
表示层主要的协议有:
- ASCII:美国信息交换标准代码(ASCII)是一种字符编码标准,用于表示文本数据
- JPEG:联合图像专家组(JPEG)是一种用于压缩图像的格式,它提供了良好的图像质量和相对较小的文件大小
- GIF:图形交换格式(GIF)是另一种图像格式,支持动画和透明背景
应用层:
- FTP:文件传输协议(FTP)用于在网络上传输文件
- Http:超文本传输协议(HTTP)用于网页的传输,是互联网上最常用的协议之一
- SMTP:简单邮件传输协议(SMTP)用于发送电子邮件
- SSH:安全外壳协议(SSH)提供了一种加密的网络服务,用于安全地访问远程计算机
- DNS:域名系统(DNS)用于将人类可读的域名转换为IP地址,使得用户可以通过网址而不是IP地址来访问网站
# 三次握手
TCP 三次握手和四次挥手也是网络中比较常问的问题,因为两台机器之间需要通信就需要去建立 TCP 连接,建立 TCP 连接就是通过 TCP 三次握手建立的,通过四次挥手关闭 TCP 连接
TCP 三次握手和四次挥手的细节这里就不说了,之前写过一篇文章,TCP 三次握手和四次挥手 (opens new window)
那么面试官可能会问,问什么一定要三次握手呢?
首先,简单来理解的话,通过三次握手,客户端和服务器端都可以证明自己的 接收 和 发送 能力都是正常的,之后才可以正常通信
如果非要举出一个例子,在谢希仁版《计算机网络》中是这样说的,如果 client 发送的第一个 SYN 包并没有丢失,只是在网络中滞留,以致于延误到连接释放以后的某个时间才到达 server。本来这是一个早已失效的报文,但 server 收到此失效报文后,就误认为是 client 再次发出的一个新的连接,于是向 client 发出 SYN+ACK 包,如果不采用三次握手,只要 server 发出 SYN+ACK 包,就建立连接,会导致 client 没有发出建立连接的请求,因此不会理会 server 的 SYN+ACK 包,但是 server 却以为新的连接建立好了,并一直等待 client 发送数据,导致资源被浪费
那么为什么不四次握手呢?
因为三次握手后,建立正常通信就没有问题了,没有必要再继续握手,浪费网络资源
# HTTP 是基于 TCP 还是 UDP 呢?
HTTP 协议在 HTTP/1.1 和 HTTP/2 版本都是 基于 TCP 协议 的,而 HTTP/3 是 基于 UDP 协议 传输的,可以根据浏览器查看 HTTP 协议到底是哪个版本的
F12 打开控制台,右键记得选择 Protocol,h2 则代表是 HTTP/2 版本的

HTTP/1 、HTTP/2 和 HTTP/3 的区别如下:
- HTTP/1(1997 年推出) 有连接无法复用、队头阻塞、协议开销大和安全因素等多个缺陷
- HTTP/2(2015 年推出) 通过多路复用、二进制流与 Header 压缩等技术,极大地提高了性能,但是还是存在一些问题
- HTTP/3(2022 年发布标准) 抛弃 TCP 协议,以全新的视角重新设计 HTTP。其底层支撑是 QUIC 协议,该协议基于 UDP,有 UDP 特有的优势,同时它又取了 TCP 中的精华,实现了即快又可靠的协议
虽然 HTTP/3 版本出现了,但是我们通过浏览器发现,常用的版本还是 HTTP/1.1 和 HTTP/2,为什么呢?(历史原因,比较老的系统使用的还是 1.1 和 2 版本较多,不过目前版本 3 也在逐步推广)

# 数据库面试实战
数据库方面也是面试中的基础知识,基本上都是必问的,其中索引、事务更是 重中之重!
# 存储引擎
先来说一下 MySQL 的存储引擎,有很多个,但是常见的其实就有两个:InnoDB 和 MyISAM
而 MyISAM 现在用的也非常少了,基本上都是用的 InnoDB 存储引擎,并且 InnoDB 也是 MySQL5.5 之后默认的存储引擎了
说一下两种存储引擎的区别:
主要了解一下两种存储引擎各自的优点以及适合的场景:
MyISAM 不支持事务,不支持外键约束,支持表级锁定,写操作时会导致整张表被锁住,并发性能较差,索引文件和数据文件是分开的,这样就可以在内存中缓存更多的索引,适合读操作远多于写操作的场景
InnoDB 支持事务,支持行级锁定,提供 MVCC 来处理并发事务,适用于对并发性能要求高的应用
# 索引
索引这块东西,只要问数据库了是必问的,InnoDB 的两种索引一定要掌握:B-tree 索引、自适应哈希索引
MySQL 中 B-tree 索引是如何实现的?
其实就是问的 B-tree 索引的数据结构,底层是 B+ 树,结构如下图(粉色区域存放索引数据,白色区域存放下一级磁盘文件地址):
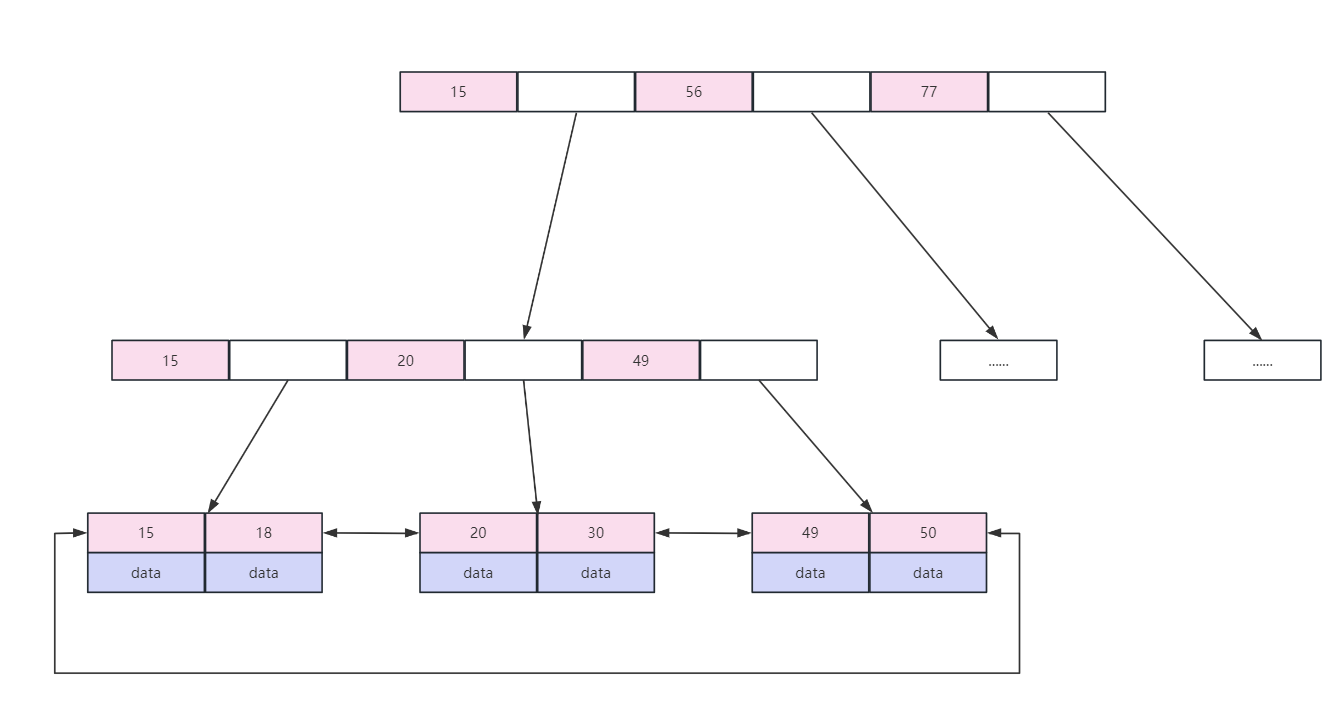
既然使用 B+ 树了,一定要知道 B+ 树的一些特点,不要面试的时候,只能说出来索引用了 B+ 树,但是也说不出来 B+ 树是什么,这是对你的面试是比较伤的
B-tree 索引(B+ 树实现)的一些特点:
- B+ 树叶子节点之间按索引数据的大小顺序建立了双向链表指针,适合按照范围查找
- 使用 B+ 树非叶子节点
只存储索引,在 B 树中,每个节点的索引和数据都在一起,因此使用 B+ 树时,通过一次磁盘 IO 拿到相同大小的存储页,B+ 树可以比 B 树拿到的索引更多,因此减少了磁盘 IO 的次数。 - B+ 树查询性能更稳定,因为数据
只保存在叶子节点,每次查询数据,磁盘 IO 的次数是稳定的
索引的数据结构了解之后,还要了解一些索引的基本知识,比如聚簇索引、非聚簇索引是什么?覆盖索引了解吗?最左前缀匹配原则了解吗?索引下推了解吗?
这些都是索引相关的 基础知识,那么初次之外,还要知道哪些情况下 索引会失效 呢?
像是索引失效这块的内容还是比较重要的,下边我也将是否使用索引的内容给整理了出来
# 如何判断是否使用索引?
建表 SQL
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
‐‐ 插入一些示例数据
drop procedure if exists insert_emp;
delimiter ;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('zqy',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter ;
call insert_emp()
1、联合索引第一个字段用范围不走索引
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';

结论:type 为 ALL 表示进行了全表扫描,mysql 内部可能认为第一个字段使用范围,结果集可能会很大,如果走索引的话需要回表导致效率不高,因此直接使用全表扫描
2、强制走索引
EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' AND age = 22 AND position ='manager';

结论:虽然走了索引,扫描了 50103 行,相比于上边不走索引扫描的行数少了一半,但是查找效率不一定比全表扫描高,因为回表导致效率不高。
可以使用以下代码测试:
set global query_cache_size=0;
set global query_cache_type=0;
SELECT * FROM employees WHERE name > 'LiLei' limit 1000;
> OK
> 时间: 0.408s
SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' limit 1000;
> OK
> 时间: 0.479s
SELECT * FROM employees WHERE name > 'LiLei' limit 5000;
> OK
> 时间: 0.969s
SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' limit 5000;
> OK
> 时间: 0.827s
结论:在查询 1000 条数据的话,全表扫描还是比走索引消耗时间短的,但是当查询 5000 条数据时,还是走索引效率高
3、覆盖索引优化
EXPLAIN SELECT name,age,position FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
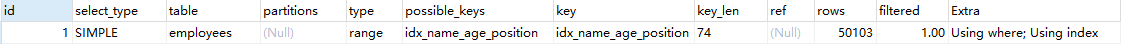
结论:将 select * 改为 select name, age, position,优化为使用覆盖索引,因此不需要回表,效率更高
4、in、or
in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
EXPLAIN SELECT * FROM employees WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position='manager'; # 结果1
EXPLAIN SELECT * FROM employees WHERE (name = 'LiLei' or name = 'HanMeimei') AND age = 22 AND position='manager'; # 结果2


结论:in、or 的查询的 type 都是 range,表示使用一个索引来检索给定范围的行
给原来的 employee 表复制为一张新表 employee_copy ,里边只保留 3 条记录
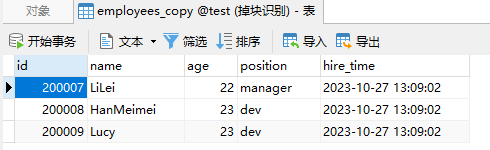
EXPLAIN SELECT * FROM employees_copy WHERE name in ('LiLei','HanMeimei','Lucy') AND age = 22 AND position ='manager';
EXPLAIN SELECT * FROM employees_copy WHERE (name = 'LiLei' or name = 'HanMeimei') AND age = 22 AND position ='manager';


结论:in、or 的查询的 type 都是 ALL,表示进行了全表扫描,没有走索引
5、like KK% 一般情况都会走索引
EXPLAIN SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager';

EXPLAIN SELECT * FROM employees_copy WHERE name like 'LiLei%' AND age = 22 AND position ='manager';

# 事务基础
事务中的 ACID 特性 是必须要知道:
- Atomic:原子性,一组 SQL 要么同时成功,要么同时失败
- Consistency:一致性,保证执行完 SQL 之后数据是准确的
- Isolation:隔离性,多个事务之间不会互相干扰
- Durability:持久性,事务提交之后,可以保证对数据库所作的更改是永久性的
# 事务的隔离级别
MySQL 的 事务隔离级别 有 4 种:
- 读未提交:事务 A 会读取到事务 B 更新但没有提交的数据。如果事务 B 回滚,事务 A 产生了脏读
- 读已提交:事务 A 会读取到事务 B 更新且提交的数据。事务 A 在事务 B 提交前后两次查询结果不同,产生不可重复读
- 可重复读:保证事务 A 中多次查询数据一致。
可重复读是 MySQL 的默认事务隔离级别。可重复读可能会造成幻读,事务A进行了多次查询,但是事务B在事务A查询过程中新增了数据,事务A虽然查询不到事务B中的数据,但是可以对事务B中的数据进行更新 - 可串行化:并发性能低,不常使用
这一部分需要了解的就是每一种隔离级别可能会带来的问题,如下这个表格所示:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
那么肯定就要了解 脏读、不可重复读、幻读 到底是个什么东东?
脏写:多个事务更新同一行,每个事务不知道其他事务的存在,最后的更新覆盖了其他事务所做的更新脏读:事务 A 读取到了事务 B 已经修改但是没有提交的数据,此时如果事务 B 回滚,事务 A 读取的则为脏数据不可重复读:事务 A 内部相同的查询语句在不同时刻读出的结果不一致,在事务 A 的两次相同的查询期间,有其他事务修改了数据并且提交了幻读:当事务 A 感知到了事务 B 提交的新增数据
# 幻读问题
在可重复读隔离级别中,通过 临键锁 在一定程度上缓解了幻读的问题,但是在特殊情况下,还是会出现幻读
以下两种情况下,会出现 幻读,大家可以先看一下如何出现的幻读, 思考一下为什么会出现幻读 ,答案会写在后边!
- 情况1:事务 A 通过更新操作获取最新视图之后,可以读取到事务 B 提交的数据,出现幻读现象
对于下图中的执行顺序,会出现幻读现象,可以看到在事务 A 执行到第 7 行发现查询到了事务 B 新提交的数据了
这里都假设使用的 InnoDB 存储引擎,事务隔离级别默认都是 可重复读
在可重复读隔离级别下,使用了 MVCC 机制,select 操作并不会更新版本号,是快照读(历史版本),执行 insert、update 和 delete 时会更新版本号,是当前读(当前版本),因此在事务 A 执行了第 6 行的 update 操作之后,更新了版本号,读到了 id = 5 这一行数据的最新版本,因此出现了幻读!

- 情况2:事务 A 在步骤 2 执行的读操作并不会生成间隙锁,因此事务 B 会在事务 A 的查询范围内插入行
对于下边这种情况也会出现幻读,在第 6 行使用 select ... for update 进行查询,这个查询语句是当前读(查询的最新版本),因此查询到了事务 B 新提交的数据,出现了幻读!
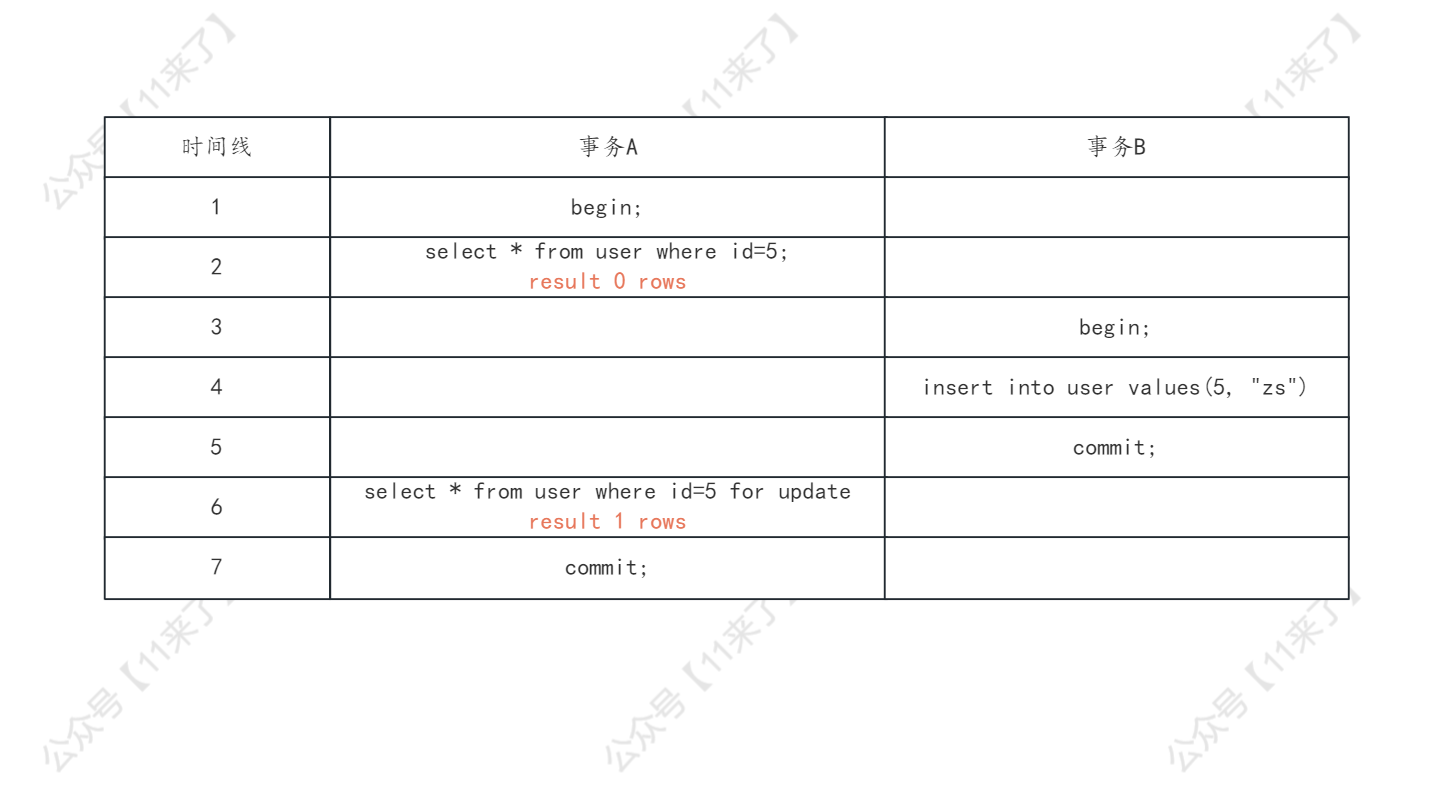
那么对于以上两种情况来说,为什么会出现幻读呢?
对于事务 A 出现了幻读,原因就是,事务 A 执行的第 2 行是普通的 select 查询,这个普通的 select 查询是快照读,不会生成临键锁(具体生成临键锁、记录锁还是间隙锁根据 where 条件的不同来选择),因此就 不会锁住这个快照读所覆盖的记录行以及区间
那么事务 B 去执行插入操作,发现并没有生成临键锁,因此直接可以插入成功
重要:那么我们从代码层面尽量去避免幻读问题呢?
在一个事务开始的时候,尽量先去执行 select ... for update,执行这个当前读的操作,会先去生成临键锁,锁住查询记录的区间,不会让其他事务插入新的数据,因此就不会产生幻读
这里我也画了一张图如下,你也可以去启动两个会话窗口,连接上 mysql 执行一下试试,就可以发现,当事务 A 执行 select ... for update 操作之后,就会加上临键锁(由于 where 后的条件是 id=5,因此这个临键锁其实会退化为记录锁,将 id=5 这一行的数据锁起来),那么事务 B 再去插入 id=5 这条数据,就会因为有锁的存在,阻塞插入语句

# MySQL 的锁
为什么需要问 MySQL 中锁的问题呢?
如果在线上系统中,在高并发的访问之下,出现了 死锁问题 或者 等待锁时间过长导致超时,那么碰到这些情况,就可能问你锁相关的问题
MySQL 这一块锁的内容还是比较复杂的,需要写一些功夫来学习,接下来我尽量写的简单易懂一些
首先还是先给锁分类,之后再来逐个了解:
按照功能划分:
共享锁:也叫
S 锁或读锁,是共享的,不互斥加锁方式:
select ... lock in share mode排他锁:也叫
X 锁或写锁,写锁阻塞其他锁加锁方式:
select ... for update
按照锁的粒度划分:
- 全局锁:锁整个数据库
- 表级锁:锁整个表
- 行级锁:锁一行记录的索引
- 记录锁:锁定索引的一条记录
- 间隙锁:锁定一个索引区间
- 临键锁:记录锁和间隙锁的结合,
解决幻读问题 - 插入意向锁:执行 insert 时添加的行记录 id 的锁
- 意向锁:存储引擎级别的“表级锁”
# 全局锁
全局锁是对整个数据库实例加锁,加锁后整个数据库实例就处于只读状态
什么时候会用到全局锁呢?
在 全库逻辑备份 的时候,对整个数据库实例上锁,不允许再插入新的数据
相关命令:
-- 加锁
flush tables with read lock;
-- 释放锁
unlock tables;
# 表级锁
表级锁中又分为以下几种:
- 表读锁:阻塞对当前表的写,但不阻塞读
- 表写锁:阻塞队当前表的读和写
- 元数据锁:这个锁不需要我们手动去添加,在访问表的时候,会自动加上,这个锁是为了保证读写的正确
- 当对表做
增删改查时,会自动添加元数据读锁 - 当对表做
结构变更时,会自动添加元数据写锁
- 当对表做
- 自增锁:是一种特殊的表级锁,自增列事务执行插入操作时产生
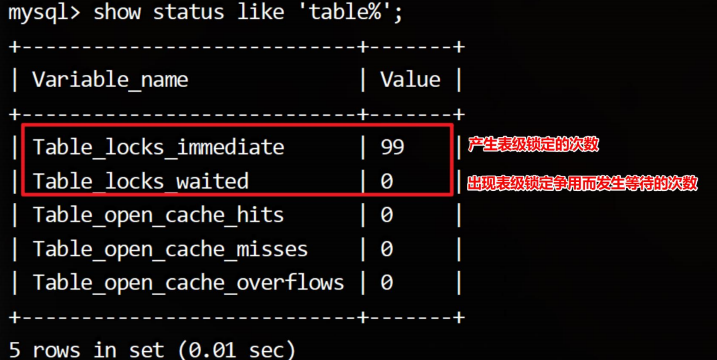
查看表级锁的命令:
-- 查看表锁定状态
show status like 'table_locks%';
-- 添加表读锁
lock table user read;
-- 添加表写锁
lock table user write;
-- 查看表锁情况
show open tables;
-- 删除表锁
unlock tables;
# 行级锁
MySQL 的行级锁是由存储引擎是实现的,InnoDB 的行锁就是通过给 索引加锁 来实现
注意:InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则会从行锁升级为表锁
行锁根据 范围 分为:记录锁(Record Locks)、间隙锁(Gap Locks)、临键锁(Next-Key Locks)、插入意向锁(Insert Intention Locks)
行锁根据 功能 分为:读锁和写锁
什么时候会添加行锁呢?
- 对于 update、insert 语句,InnoDB 会自动添加写锁(具体添加哪一种锁会根据 where 条件判断,后边会提到
加锁规则) - 对于 select 不会添加锁
- 事务手动给 select 记录集添加读锁或写锁
接下来对记录锁、间隙锁、临键锁、插入意向锁来一个一个解释,这几个锁还是比较重要的,一定要学习!
记录锁:
记录锁:锁的是一行索引,而不是记录
那么可能有人会有疑问了,如果这一行数据上没有索引怎么办呢?
其实如果一行数据没有索引,InnoDB 会自动创建一个隐藏列 ROWID 的聚簇索引,因此每一行记录是一定有一个索引的
下边给出记录锁的一些命令:
-- 加记录读锁
select * from user where id = 1 lock in share mode;
-- 加记录写锁
select * from user where id = 1 for update;
-- 新增、修改、删除会自动添加记录写锁
insert into user values (1, "lisi");
update user set name = "zhangsan" where id = 1;
delete from user where id = 1;
间隙锁
间隙锁用于锁定一个索引区间,开区间,不包括两边端点,用于在索引记录的间隙中加锁,不包括索引记录本身
间隙锁的作用是 防止幻读,保证索引记录的间隙不会被插入数据
间隙锁在 可重复读 隔离级别下才会生效
如下:
select * from users where id between 1 and 10 for update;
# 间隙锁、临键锁区间图
这里将间隙锁和临键锁(下边会讲到)在主键索引 id 列和普通索引 num 列上的区间图画出来,方便通过图片更加直观的学习
首先,表字段和表中数据如下:

对于这两个字段,他们的间隙锁和临键锁的区间如下(红色部分):
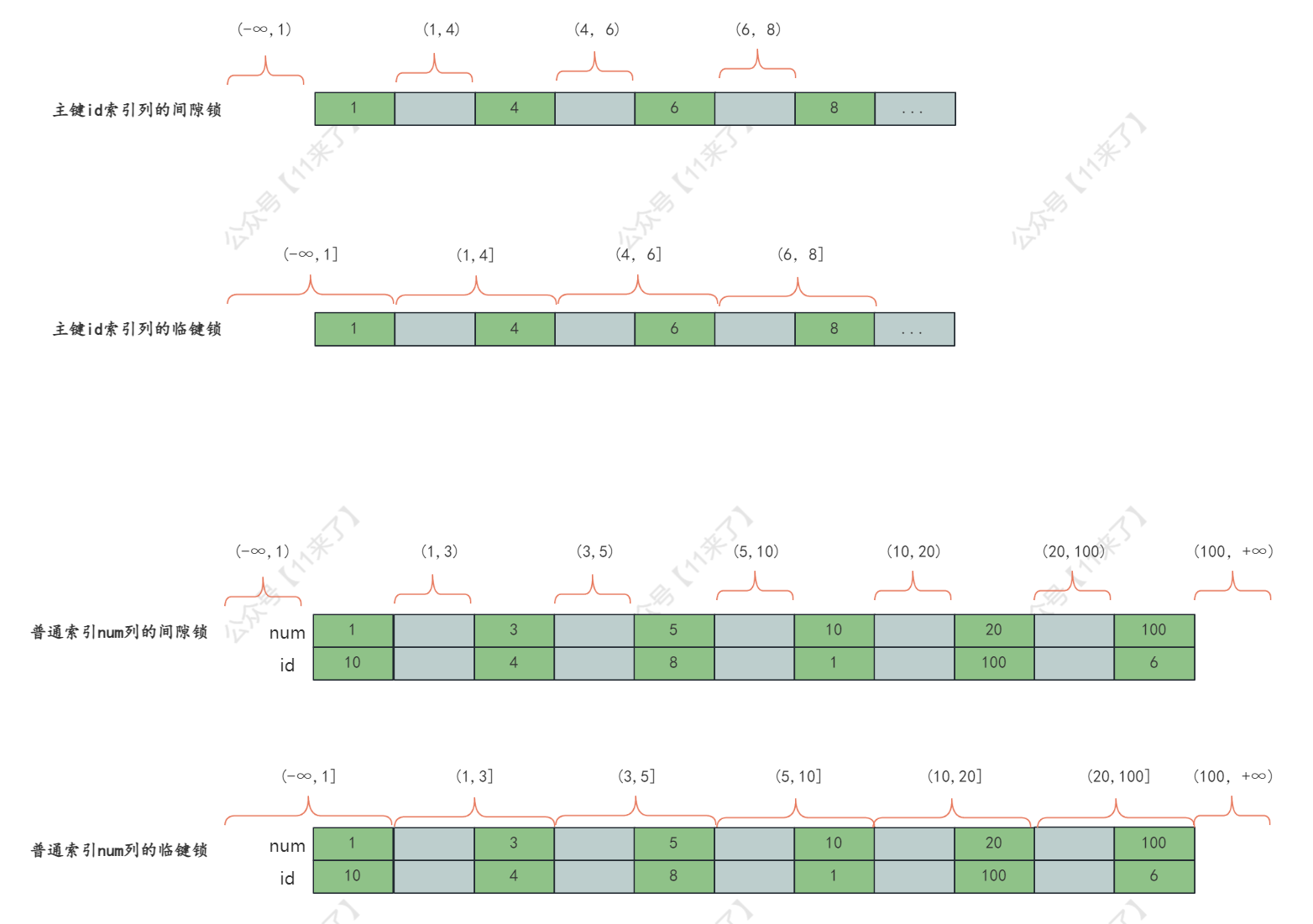
临键锁
临键锁是记录锁和间隙锁的组合,这里之所以称临键锁是这两个锁的组合是因为它会锁住一个左开右闭的区间(间隙锁是两边都是开区间,通过记录锁锁住由边的记录,成为左开右闭的区间),可以看上边的图片来查看临键锁的范围
默认情况下,InnoDB 使用临键锁来锁定记录,但会在不同场景中退化
- 使用唯一索引(Unique index)等值(=)且记录存在,退化为
记录锁 - 使用唯一索引(Unique index)等值(=)且记录不存在,退化为
间隙锁 - 使用唯一索引(Unique index)范围(>、<),使用
临键锁 - 非唯一索引字段,默认是
临键锁
每个数据行上的 非唯一索引 都会存在一把临键锁,但某个事务持有这个临键锁时,会锁一段左开右闭区间的数据
插入意向锁
间隙锁在一定程度上可以解决幻读问题,但是如果一个间隙锁锁定的区间范围是(10,100),那么在这个范围内的 id 都不可以插入,锁的范围很大,导致很容易发生锁冲突的问题
插入意向锁就是用来解决这个问题
插入意向锁是在 Insert 操作之前设置的一种 特殊的间隙锁,表示一种插入意图,即当多个不同的事务同时向同一个索引的同一个间隙中插入数据时,不需要等待
插入意向锁不会阻塞 插入意向锁,但是会阻塞其他的 间隙写锁、记录锁
举个例子:就比如说,现在有两个事务,插入值为 50 和值为 60 的记录,每个事务都使用 插入意向锁 去锁定 (10,100)之间的间隙,这两个事务之间不会相互阻塞!
# 加锁规则【重要】
加锁规则非常重要,要了解 MySQL 会在哪种情况下去加什么锁,避免我们使用不当导致加锁范围很大,影响写操作性能
对于 主键索引 来说:
- 等值条件,命中,则加记录锁
- 等值条件,未命中,则加间隙锁
- 范围条件,命中,对包含 where 条件的临建区间加临键锁
- 范围条件,没有命中,加间隙锁
对于 辅助索引 来说:
- 等值条件,命中,则对命中的记录的
辅助索引项和主键索引项加记录锁,辅助索引项两侧加间隙锁 - 等值条件,未命中,则加间隙锁
- 范围条件,命中,对包含 where 条件的临建区间加临键锁,对命中纪录的 id 索引项加记录锁
- 范围条件,没有命中,加间隙锁
# 行锁变成表锁
锁主要是加在索引上,如果对非索引字段更新,行锁可能会变表锁:
假如 account 表有 3 个字段(id, name, balance),我们在 name、balance 字段上并没有设置索引
session1 执行:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+----+------+---------+
| id | name | balance |
+----+------+---------+
| 1 | zs | 777 |
| 2 | ls | 800 |
| 3 | ww | 777 |
| 4 | abc | 999 |
| 10 | zzz | 2000 |
| 20 | mc | 1500 |
+----+------+---------+
6 rows in set (0.01 sec)
mysql> update account set balance = 666 where name='zs';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
此时 session2 执行(发现执行阻塞,经过一段时间后,返回结果锁等待超时,证明 session1 在没有索引的字段上加锁,导致行锁升级为表锁,因此 session2 无法对表中其他数据做修改):
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set balance = 111 where name='abc';
RROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则会从行锁升级为表锁
# 行锁分析实战【重要】
这里主要对下边这两条 sql 进行分析,判断看到底会添加什么样的行锁:
-- sql1
select * from user where id = 5;
-- sql2
delete from user where id = 5;
而对于 sql1 来说,select 查询是快照读,不会加锁,因此下边主要是对 sql2 进行分析
其实只通过 sql 是没有办法去分析到底会添加什么样的行锁,还需要结合 where 后边的条件,还有索引的字段来综合分析
以下分析基于 可重复读 隔离级别进行分析
情况1:id 列是主键
当 id 列是主键的时候,delete 操作对 id=5 的数据删除,此时根据【加锁规则】,只需要对 id=5 这条记录加上 记录写锁 即可
只对这一条记录加锁,比较简单,这里就不画图了
情况2:id 列是二级唯一索引
如果 id 列是二级唯一索引的话,此时根据【加锁规则】,那么需要对 id=5 这条记录加上 记录写锁,再通过这个二级唯一索引去 主键索引 中找到对应的记录,也加上 记录写锁,添加的锁如下图:
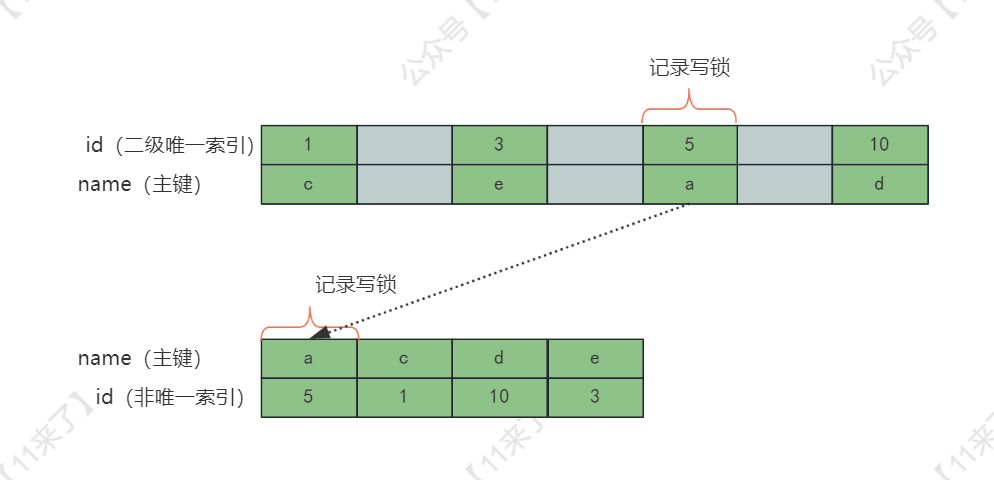
为什么主键索引中也需要加锁呢?
如果另一个并发的 sql 通过主键索引来更新这条记录:update user set id = 11 where name = 'a';,而 delete 没有对主键索引上的记录加锁,就会导致这条 update 语句并不知道 delete 在对这条数据进行操作
情况3:id 列是二级非唯一索引
在 可重复读 隔离级别下,通过间隙锁去避免了幻读的问题,虽然还有可能出现幻读,还是大多数情况下不会出现
如何通过添加 间隙锁 去避免幻读问题呢?
当删除 id = 5 的数据时,由于 id 是二级非唯一索引(辅助索引),由上边的加锁规则可以知道,会对命中的记录的 辅助索引项 和 主键索引项 加 记录锁 ,辅助索引项两侧加 间隙锁,加的锁如下图红色所示:

情况4:id 列上没有索引
如果 id 列上没有索引,那么就只能全表扫描,因此会给整个表都加上写锁,也就是锁上 表的所有记录 和 聚簇索引的所有间隙
那么如果表中有 上千万条数据,那么在这么大的表上,除了不加锁的快照读操作,无法执行其他任何需要加锁的操作,那么在整个表上锁的期间,执行 SQL 的并发度是很低的,导致性能很差
因此,一定要注意,尽量避免在没有索引的字段上进行加锁操作,否则行锁升级为表锁,导致性能大大降低
# 死锁分析
死锁 造成的原因:两个及以上会话的 加锁顺序不当 导致死锁
死锁案例:两个会话都持有一把锁,并且去争用对方的锁,从而导致死锁

如何排查和避免死锁问题:
通过 sql 查询最近一次死锁日志:
show engine innodb status;
MySQL 默认会主动探知死锁,并回滚某一个影响最小的事务,等另一个事务执行完毕后,在重新执行回滚的事务
可以从以下几个方面降低死锁问题出现的概率:
- 尽量减小锁的粒度,保持事务的轻量,可以降低发生死锁的概率
- 尽量避免交叉更新的代码逻辑
- 尽快提交事务,减少锁的持有时间
# MySQL 中的 SQL 优化
这里主要说一下 MySQL 中如何对 SQL 进行优化,其实主要还是根据索引来进行优化的,如果好好了解下边的 SQL 优化,可以对 MySQL 的理解更加深入
接下来的 SQL 优化,以下边这个 employees 表为例进行优化:
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
‐‐ 插入一些示例数据
drop procedure if exists insert_emp;
delimiter ;;
create procedure insert_emp()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into employees(name,age,position) values(CONCAT('zqy',i),i,'dev');
set i=i+1;
end while;
end;;
delimiter ;
call insert_emp();
# order by、group by 优化
下边是 8 种使用 order by 的情况,我们通过分析以下案例,可以判断出如何使用 order by 和 where 进行配合可以走using index condition(索引排序)而不是 using filesort(文件排序)
- case1
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' and position = 'dev' order by age;

分析:查询用到了 name 索引,从 key_len=74 也能看出,age 索引列用在排序过程中,因此 Extra 字段里没有 using filesort
- case2
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' order by position;

分析:从 explain 执行结果来看,key_len = 74,查询使用了 name 索引,由于用了 position 进行排序,跳过了 age,出现了 Using filesort
- case3
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' order by age, position;

分析:查找只用到索引name,age和position用于排序,与联合索引顺序一致,因此无 using filesort。
- case4
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' order by position, age;

分析:因为索引的创建顺序为 name,age,position,但是排序的时候 age 和 position 颠倒位置了,和索引创建顺序不一致,因此出现了 using filesort
- case5
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' and age = 18 order by position, age;

分析:与 case 4 相比,Extra 中并未出现 using filesort,并且查询使用索引 name,age,排序先根据 position 索引排序,索引使用顺序与联合索引顺序一致,因此使用了索引排序
- case6
EXPLAIN SELECT * FROM employees WHERE name = 'zqy' order by age asc, position desc;

分析:虽然排序字段列与联合索引顺序一样,但是这里的 position desc 变成了降序排序,导致与联合索引的排序方式不同,因此产生了 using filesort
- case7
EXPLAIN SELECT * FROM employees WHERE name in ('LiLei', 'zqy') order by age, position;

分析:先使用索引 name 拿到 LiLei,zqy 的数据,之后需要根据 age、position 排序,但是根据 name 所拿到的数据对于 age、position 两个字段来说是无序的,所以需要使用到 filesort。
为什么根据 name in 拿到的数据对于 age、position 来说是无序的:
对于下图来说,如果取出 name in (Bill, LiLei) 的数据,那么对于 age、position 字段显然不是有序的,因此肯定无法使用索引扫描排序

- case8
EXPLAIN SELECT * FROM employees WHERE name > 'a' order by name;

分析:对于上边这条 sql 来说,是 select * 因此 mysql 判断不走索引,直接全表扫描更快,因此出现了 using filesort
EXPLAIN SELECT name FROM employees WHERE name > 'a' order by name;

分析:因此可以使用覆盖索引来优化,只通过索引查询就可以查出我们需要的数据,不需要回表,通过覆盖索引优化,因此没有出现 using filesort
# 优化总结
- MySQL支持两种方式的排序 filesort 和 index,Using index 是指 MySQL 扫描索引本身完成排序。index 效率高,filesort 效率低。
- order by满足两种情况会使用Using index。
- order by语句使用索引最左前列。
- 使用where子句与order by子句条件列组合满足索引最左前列。
- 尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最左前缀法则。
- 如果order by的条件不在索引列上,就会产生Using filesort。
- 能用覆盖索引尽量用覆盖索引
- group by 与 order by 很类似,其实质是先排序后分组,遵照索引创建顺序的最左前缀法则。对于 group by 的优化如果不需要排序的可以加上 order by null 禁止排序。注意,where 高于 having,能写在 where 中的限定条件就不要去 having 限定了。
# 分页查询优化
我们实现分页功能可能会用以下 sql:
select * from employees limit 10000, 10;
该 sql 表示从 employees 表的第 10001 行开始的 10 行数据,虽然只查询了 10 条数据,但是会先去读取 10010 条记录,再抛弃前 10000 条数据,因此如果查询的数据比较靠后,效率非常低
# 1、根据自增且连续的主键排序的分页查询
该优化必须保证主键是自增的,并且主键连续,中间没有断层。
未优化 sql
select * from employees limit 9000, 5;
结果:
执行计划:

因为 id 是连续且自增的,所以可以直接通过 id 判断拿到 id 比 9000 大的 5 条数据,效率更高:
优化后 sql
select * from employees where id > 9000 limit 5;
结果
执行计划:

总结
- 如果主键空缺,则不能使用该优化方法
# 2、根据非主键字段排序的分页查询
未优化 sql
select * from employees order by name limit 9000, 5;
> OK
> 时间: 0.066s
explain select * from employees order by name limit 9000, 5;

根据执行计划得,使用了全表扫描(type=ALL),并且 Extra 列为 using filesort,原因是联合索引为(name,age,position),但是使用了 select * 中有的列并不在联合索引中,如果使用索引还需要回表,因此 mysql 直接进行全表扫描
优化 sql
优化的点在于:让在排序时返回的字段尽量为覆盖索引,这样就会走索引并且还会使用索引排序
先让排序和分页操作查出主键,再根据主键查到对应记录
select * from employees e inner join (select id from employees order by name limit 9000, 5) ed on e.id = ed.id;
> OK
> 时间: 0.032s

explain select * from employees e inner join (select id from employees order by name limit 9000, 5) ed on e.id = ed.id;

根据执行计划得,优化后查询走了索引,并且排序使用了索引排序
总结
- 优化后,sql 语句的执行时间时原 sql 的一半
# in 和 exists 优化
原则:小表驱动大表
in:当 B 表的数据集小于 A 表的数据集时,使用 in
select * from A where id in (select id from B)
exists:当 A 表的数据集小于 B 表的数据集时,使用 exists
将主查询 A 的数据放到子查询 B 中做条件验证,根据验证结果(true 或 false)来决定主查询的数据是否保留
select * from A where exists (select 1 from B where B.id = A.id)
总结
- exists 只返回 true 或 false,因此子查询中的 select * 也可以用 select 1 替换
# count(*)查询优化
‐‐ 临时关闭mysql查询缓存,为了查看sql多次执行的真实时间
set global query_cache_size=0;
set global query_cache_type=0;
EXPLAIN select count(1) from employees;
EXPLAIN select count(id) from employees;
EXPLAIN select count(name) from employees;
EXPLAIN select count(*) from employees;

分析:4 条 sql 语句的执行计划一样,说明这 4 个 sql 的执行效率差不多
总结
当字段有索引,执行效率:
count(*) ≈ count(1) > count(字段) > count(主键id)如果字段有索引,走二级索引,二级索引存储的数据比主键索引少,所以
count(字段)比count(主键id)效率更高当字段无索引,执行效率:
count(*) ≈ count(1) > count(主键id) > count(字段)count(1)和count(*)比较count(1)不需要取出字段统计,使用常量 1 做统计,count(字段)还需要取出字段,所以理论上count(1)比count(字段)快count(*)是例外,mysql 并不会把全部字段取出来,会忽略所有的列直接,效率很高,所以不需要用count(字段)或count(常量)来替代count(*)
为什么对于
count(id),mysql最终选择辅助索引而不是主键聚集索引?因为二级索引相对主键索引存储数据更少,检索性能应该更高,mysql内部做了点优化(在5.7版本才优化)。
# 网络通信面试实战
# Socket 工作原理
Socket 是应用层与 TCP/IP 协议族通信的中间软件抽象层,它是一组接口,其实就是一个门面模式,将底层复杂的通信操作给封装起来对外提供接口。
简单来说就是 Socket 把 TPC/IP 协议给封装了起来,我们的程序进行网络通信都是通过 Socket 来完成的!
也就是说当两台设备进行通信时,是通过 Socket 进行通信的,接下来通过 Java 代码来了解一下如何通过 Socket 进行网络通信:
服务端:
public class Server {
public static void main(String[] args) {
int port = 1234; // 服务器监听的端口号
try (ServerSocket serverSocket = new ServerSocket(port)) {
System.out.println("服务器启动,等待客户端连接...");
// 等待客户端连接
Socket clientSocket = serverSocket.accept();
System.out.println("客户端已连接:" + clientSocket.getInetAddress().getHostAddress());
// 获取输入流
InputStream input = clientSocket.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
// 读取客户端发送的消息
String received = reader.readLine();
System.out.println("接收到消息: " + received);
// 获取输出流
OutputStream output = clientSocket.getOutputStream();
PrintWriter writer = new PrintWriter(output, true);
// 回显客户端发送的消息
writer.println("服务器回显: " + received);
} catch (IOException e) {
e.printStackTrace();
}
}
}
客户端:
public class Client {
public static void main(String[] args) {
String serverAddress = "localhost"; // 服务器地址
int port = 1234; // 服务器监听的端口号
try (Socket socket = new Socket(serverAddress, port)) {
System.out.println("连接到服务器...");
// 获取输出流
OutputStream output = socket.getOutputStream();
PrintWriter writer = new PrintWriter(output, true);
// 向服务器发送消息
writer.println("Hello, Server!");
// 获取输入流
InputStream input = socket.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
// 读取服务器回显的消息
String response = reader.readLine();
System.out.println("接收到服务器的回显: " + response);
} catch (IOException e) {
e.printStackTrace();
}
}
}
# BIO、NIO和AIO
面试中问到网络相关的内容,其中 BIO、NIO 的内容肯定是必问的,AIO 可以了解一下,一定要清楚 BIO 和 NIO 中通信的流程
我也画了两张图,可以记下这两张图
- AIO:
从 Java.1.7 开始,Java 提供了 AIO(异步IO),Java 的 AIO 也被称为 “NIO.2”
Java AIO 采用订阅-通知模式,应用程序向操作系统注册 IO 监听,之后继续做自己的事情,当操作系统发生 IO 事件并且已经准备好数据时,主动通知应用程序,应用程序再进行相关处理
(Linux 平台没有这种异步 IO 技术,而是使用 epoll 对异步 IO 进行模拟)
- BIO:
BIO 即同步阻塞 IO,服务端实现模式为一个连接对应一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理
BIO简单工作流程:
- 服务器端启动一个 ServerSocket,用于接收客户端的连接
- 客户端启动 Socket 与服务器建立连接,默认情况下服务器端需要对每个客户端建立一个线程与之通讯(并且与每一个可u后端有一个对应的 Socket)
- 客户端发出请求后, 先咨询服务器是否有线程响应,如果没有则会等待,或者被拒绝
- 如果服务端有对应线程处理
- 客户端进行读取,则线程会被阻塞直到完成读取
- 客户端进行写入,则线程会被阻塞直到完成写入
使用 BIO 通信的流程图如下:
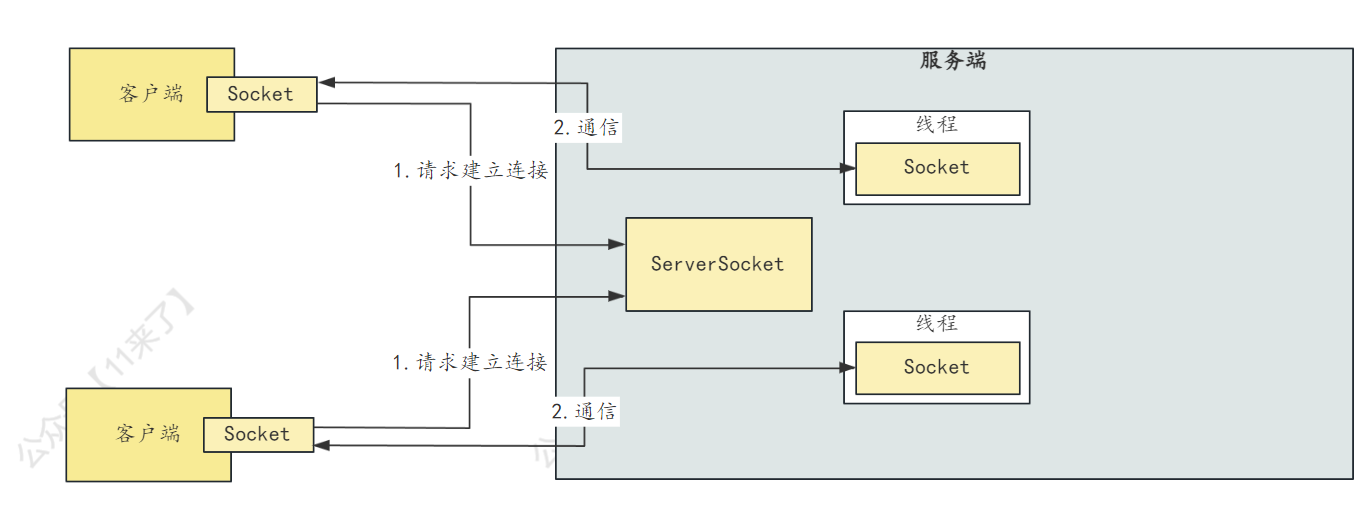
BIO存在问题:
- 当并发量较大时,需要创建大量线程来处理连接,比较占用系统资源
- 连接建立之后,如果当前线程暂时没有数据可读,则线程会阻塞在 Read 操作上,造成线程资源浪费
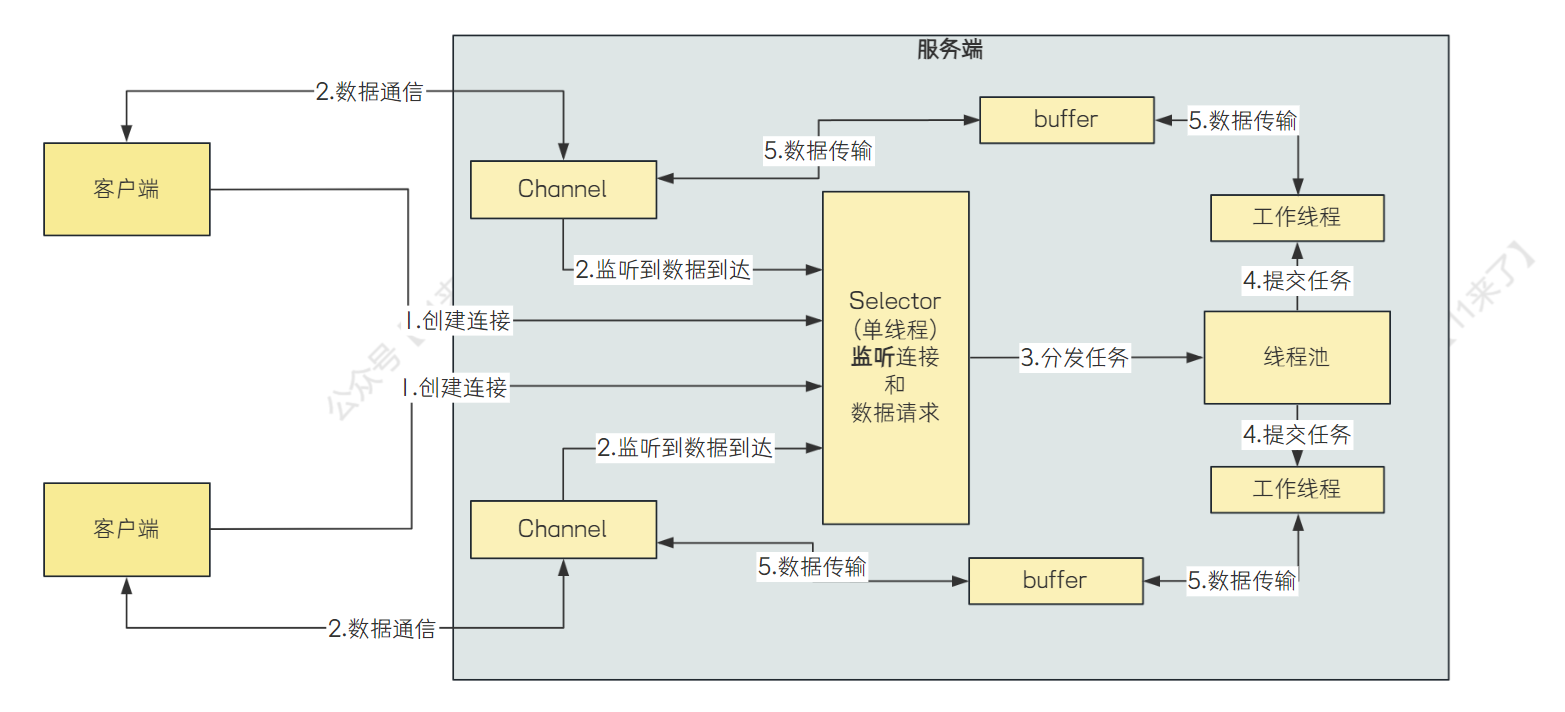
- NIO:
从 Java1.4 开始,Java 提供了 NIO,NIO 即 “Non-blocking IO”(同步非阻塞IO)
NIO 的几个核心概念:
Channel、Buffer:BIO是基于字节流或者字符流的进行操作,而NIO 是基于
缓冲区和通道进行操作的,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中Selector:选择器用于监听多个通道的事件(如,连接打开,数据到达),因此,单个线程可以监听多个数据通道,极大提升了单机的并发能力
当 Channel 上的 IO 事件未到达时,线程会在 select 方法被挂起,让出 CPU 资源,直到监听到 Channel 有 IO 事件发生,才会进行相应的处理
- NIO和BIO有什么区别?
- NIO是以
块的方式处理数据,BIO是以字节流或者字符流的形式去处理数据。 - NIO是通过
缓存区和通道的方式处理数据,BIO是通过InputStream和OutputStream流的方式处理数据。 - NIO的通道是双向的,BIO流的方向只能是单向的。
- NIO采用的多路复用的同步非阻塞IO模型,BIO采用的是普通的同步阻塞IO模型。
- NIO的效率比BIO要高,NIO适用于网络IO,BIO适用于文件IO。
NIO如何实现了同步非阻塞?
通过 Selector 和 Channel 来进行实现,一个线程使用一个 Selector 监听多个 Channel 上的 IO 事件,通过配置监听的通道Channel为非阻塞,那么当Channel上的IO事件还未到达时,线程会在select方法被挂起,让出CPU资源。直到监听到Channel有IO事件发生时,才会进行相应的响应和处理。
使用 NIO 通信的流程图如下:
# 硬件级别可见性问题面试实战
这里为什么要了解一下可见性的底层原理呢?
因为对于可见性这块的内容,他并不是软件层面上的问题,而是硬件层面的问题,是底层的一些机制导致了可见性的问题,了解了底层的相关内容之后,我们的知识会更容易形成一个闭环,而不仅仅是停留于软件层面,对下层一无所知!
所以接下来聊一聊底层中到底是什么原因导致了不同线程之间出现这个可见性的问题
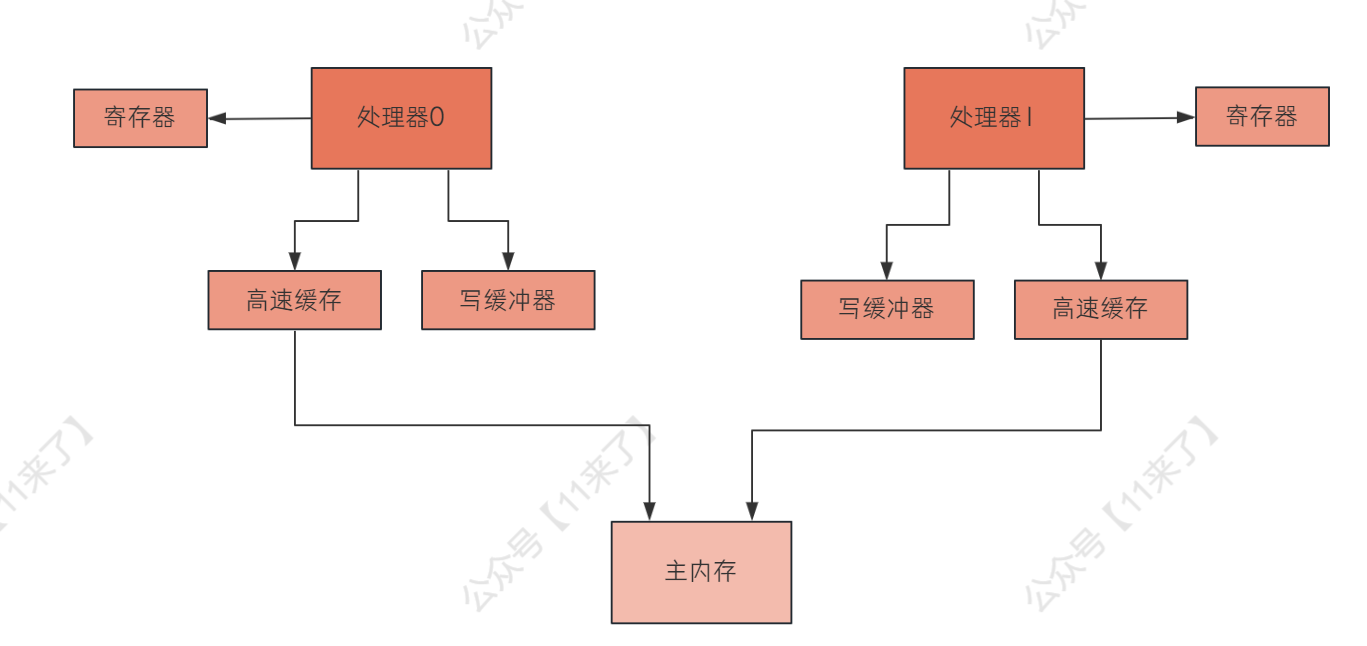
# 可见性硬件级别造成原因
首先,每一个处理器都有自己的寄存器,而线程对变量的读操作都是针对写缓冲进行的,因此这个可见性问题与 寄存器 和 写缓冲 这两个硬件组件是有关联的
这里分别说一下寄存器和写缓冲 如何导致了可见性的问题:
多个处理器都在运行各自的线程的时候,
如果其中一个处理器中的线程将某一个变量更新后的值放在寄存器中,那么其他处理器中的线程是没有办法看到这个更新后的值的,因为这个寄存器是各个处理器私有的,因此,寄存器会导致可见性的问题处理器运行的线程,
对变量的写操作是针对写缓冲进行的,之后才会刷到主内存中,因此如果一个线程更新了变量,如果仅仅写入到了写缓冲充,还没有刷到主内存或高速缓存中,那么其他处理器中的线程是无法感知到这个变量的修改的,此时,导致可见性的问题即使这个写缓冲的数据的更新也同步到了自己的主内存或高速缓存里,并且将这个更新通知给了其他的处理器,但是其他处理器可能把这个更新放到无效队列中,并没有更新自己的高速缓存,此时仍然会导致可见性的问题
如下这个图:
# MESI 协议
那么要实现多个处理器的共享数据的一致性,可以通过 MESI 协议来实现
根据具体底层硬件的不同,MESI 协议的具体实现也是不同的
这里说一种 MESI 协议的实现:通过将其他处理器高速缓存中 更新后的数据 拿到自己的高速缓存中更新一下,这样不同处理器之间的高速缓存中的数据就保持一致了,实现了可见性
在实现 MESI 协议的过程中,需要 两个关键的机制 来确保缓存的一致性:flush 和 refresh
- flush
将自己更新的值刷新到高速缓存里去,让其他处理器在后续可以通过一些机制从自己的高速缓存里读到更新后的值
并且还会给其他处理器发送一个 flush 消息,让其他处理器将对应的缓存行标记为无效,确保其他处理器不会读到这个变量的过时版本
- refresh
处理器中的线程在读取一个变量的值的时候,如果发现其他处理器的线程更新了变量的值,必须从其他处理器的高速缓存(或者是主内存)里,读取这个最新的值,更新到自己的高速缓存中
因此,在底层通过 MESI 协议、flush 处理器缓存和 refresh 处理器缓存来保证可见性的
总结一下就是,flush 是强制将更新后的数据从写缓冲器中刷新到高速缓存中去;refresh 是去感知到其他处理器更新了变量,主动从主内存或其他处理器的高速缓存中加载最新数据
那么举个例子,对于 volatile 变量来说:
volatile boolean flag = true;
当写 volatile 变量时,就会通过执行一个内存屏障,在底层会触发flush处理器缓存的操作,把数据刷到主内存中
当读 volatile 变量时,也会通过执行一个内存屏障,在底层触发refresh操作,从主内存中,读取最新的值
# 指令重排
指令重排的内容我们可以来了解一下,什么时候会发生指令重排
指令重排指的是我们写好的代码,在真正执行的时候,执行顺序可能会被重排序,如果重排序之后,在多线程的执行环境下,可能就会出现一些问题
什么时候会发生指令重排呢?
- 编译期间
Java 中有两种编译器,一种是静态编译器(javac),另一种是动态编译器(JIT)
javac 负责把 .java 文件中的源代码编译为 .class 文件中的字节码,这个一般是程序写好之后进行编译的
JIT 是 JVM 的一部分,负责把 .class 文件中的字节码编译为 JVM 所在操作系统支持的机器码,一般在程序运行过程中进行编译
那么在编译期间,可能编译器为了提高代码的执行效率,会对指令进行重排,JIT 对指令重排还是比较多的
- 处理器执行顺序
编译器编译好的指令,到真正处理器执行的时候,可能还会调整顺序
指令重排有什么规则约束呢?
上边讲过了一个 happens-before 原则,它定义了一些规则,只要符合 happens-before 中的规则的都不会进行指令重排
就比如说,下边代码的第三行不可能重排到上边,因为它的执行结果依赖了上边两行的执行结果,因此不会重排,但是前两行可能会重排:
int a = 1;
int b = 2;
int c = a + b;
# 经典指令重排案例
这里说一个在 JIT 动态编译时,经典的指令重排现象,双端检锁 时发生指令重排可能导致的错误
首先,双端检锁是用于构造单例对象的,如下:
public class Singleton {
private static Singleton INSTANCE;
private Singleton() {
}
public static Singleton getInstance() {
//第一次校验单例对象是否为空
if (INSTANCE == null) {
//同步代码块
synchronized (Singleton.class) {
//第二次校验单例对象是否为空
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
public static void main(String[] args) {
for (int i = 0; i < 20; i++) {
new Thread(() -> System.out.println(Singleton.getInstance().hashCode())).start();
}
}
}
从字节码层面来看上述代码
0 getstatic #2 <com/qy/nettychat/Volatile/Demo1.INSTANCE : Lcom/qy/nettychat/Volatile/Demo1;>
3 ifnonnull 37 (+34)
6 ldc #3 <com/qy/nettychat/Volatile/Demo1>
8 dup
9 astore_0
10 monitorenter
11 getstatic #2 <com/qy/nettychat/Volatile/Demo1.INSTANCE : Lcom/qy/nettychat/Volatile/Demo1;>
14 ifnonnull 27 (+13)
17 new #3 <com/qy/nettychat/Volatile/Demo1>
20 dup
21 invokespecial #4 <com/qy/nettychat/Volatile/Demo1.<init> : ()V>
24 putstatic #2 <com/qy/nettychat/Volatile/Demo1.INSTANCE : Lcom/qy/nettychat/Volatile/Demo1;>
27 aload_0
28 monitorexit
29 goto 37 (+8)
32 astore_1
33 aload_0
34 monitorexit
35 aload_1
36 athrow
37 getstatic #2 <com/qy/nettychat/Volatile/Demo1.INSTANCE : Lcom/qy/nettychat/Volatile/Demo1;>
40 areturn
其中双端检锁(DCL)部分字节码如下
17 new #3 <com/qy/nettychat/Volatile/Demo1>
20 dup
21 invokespecial #4 <com/qy/nettychat/Volatile/Demo1.<init> : ()V>
24 putstatic #2 <com/qy/nettychat/Volatile/Demo1.INSTANCE : Lcom/qy/nettychat/Volatile/Demo1;>
- new 创建一个对象,并将其引用压入栈顶
- dup 复制栈顶数值并将值压入栈顶
- invokespecial 调用Demo1的初始化方法
- putstatic 将该引用赋值给静态变量 INSTANCE
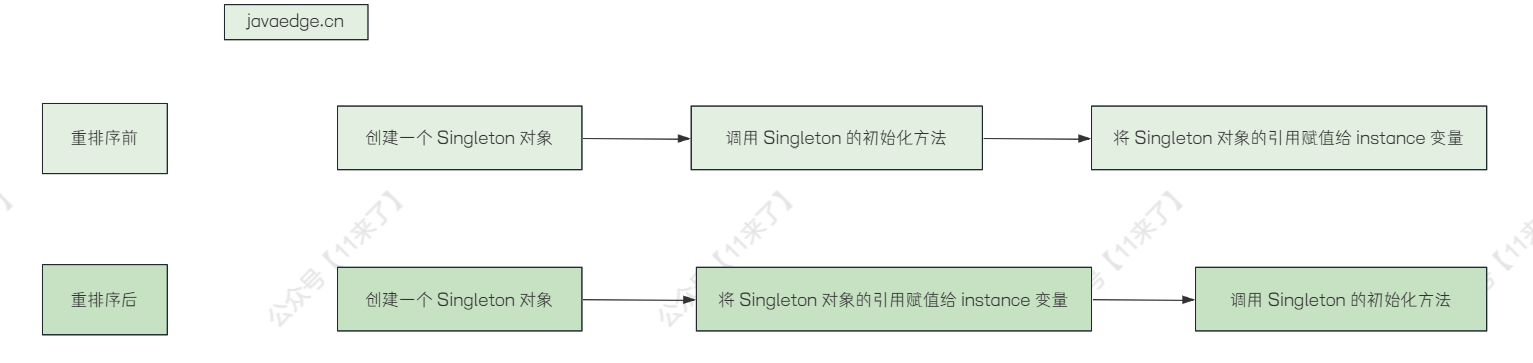
在单线程下 putstatic 和 invokespecial 进行指令重排,可以提高效率;在多线程下,指令重排可能会出现意想不到的结果
- 单线程情况下,JVM 在执行字节码时,会出现指令重排情况:在执行完
dup指令之后,为了加快程序执行效率,跳过构造方法的指令(invokespecial) ,直接执行putstatic指令,然后再将操作数栈上剩下的引用来执行invokespecial。单线程情况下JVM任何打乱invokespecial和putstatic执行顺序并不会影响程序执行的正确性。 - 多线程情况下,如果发生上述指令重排,此时第二个线程执行
getInstance会执行到if(INSTANCE==NULL),此时会拿到一个尚未初始化完成的对象,那么使用未初始化完成的对象时可能会发生错误。
示例图如下:
# 指令乱序机制
这个内容可以作为扩展了解!
指令乱序机制是现代处理器中用于提升性能的一种技术
指令乱序的意思时,处理器 不会按照程序中指令的顺序来严格顺序执行,而是会动态地调整指令地顺序,哪些指令先就绪,就先执行哪些指令,之后将每个指令的执行结果放到一个 重排序处理器 中,重排序处理器把各个指令的结果按照代码顺序应用到主内存或者写缓冲器里
指令乱序机制可能造成数据一致性的问题,因此处理器提供了 内存屏障 和 同步原语(volatile、synchronized 等) 来保证在需要的时候,指令的执行顺序可以被保证同步,防止指令乱序执行
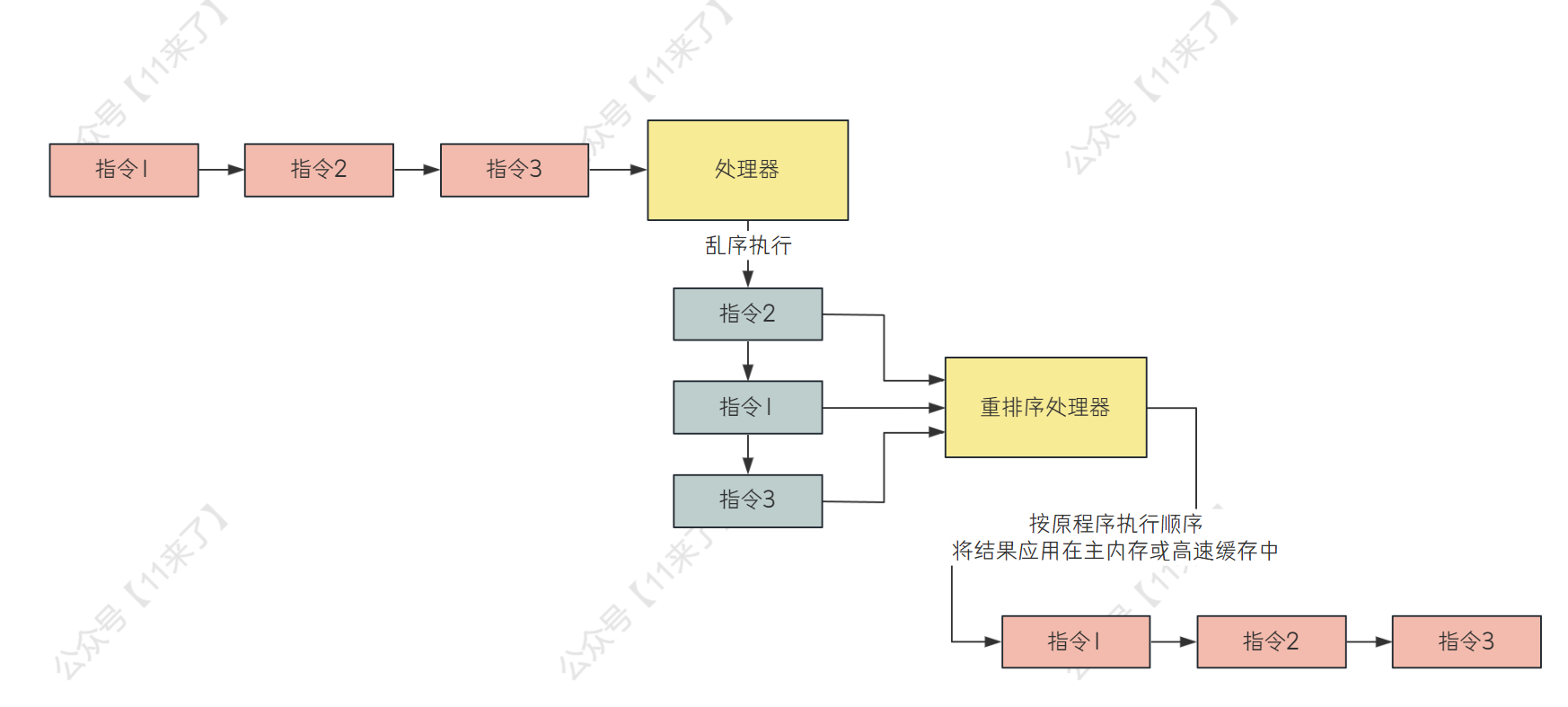
# 高速缓存和写缓冲器的内存重排序造成的视觉假象
这里讲一下高速缓存和写缓冲器的 内存重排序 造成的视觉假象:
处理器会将数据写入到写缓冲器中,这个过程就是 store;从高速缓存里读数据,这个过程就是 load,对于处理器来说,它的重排处理器是按照顺序来 load 和 stroe 的,但是如果在写缓冲器中发生了内存层面的指令重排序,就会导致其他处理器认为当前重排序后的指令顺序发生了变化
举个例子:比如现在有两个写操作 W1 和 W2,处理器先执行了 W1 再执行了 W2,写入到了 写缓冲器 中,而写缓冲可能为了提升性能,先将 W2 操作的数据写入到高速缓存中,再将 W1 操作的数据写入到高速缓存中,这样 W2 操作的结果先写入到 高速缓存 中后,会 先被其他处理器感知到,那么其他处理器就会误认为 W2 操作是先于 W1 操作执行的,这个就是 重排序造成的视觉假象!
整个过程如下图,处理器 1 先执行 W1 再执行 W2,结果写缓冲器重排序后,将 W2 操作排在了前边:

这个内存重排序,有4种可能性:
- LoadLoad重排序:一个处理器先执行一个L1读操作,再执行一个L2读操作;但是另外一个处理器看到的是先L2再L1
- StoreStore重排序:一个处理器先执行一个W1写操作,再执行一个W2写操作;但是另外一个处理器看到的是先W2再W1
- LoadStore重排序:一个处理器先执行一个L1读操作,再执行一个W2写操作;但是另外一个处理器看到的是先W2再L1
- StoreLoad重排序:一个处理器先执行一个W1写操作,再执行一个L2读操作;但是另外一个处理器看到的是先L2再W1
接下来举一个具体的例子:
对于下边的代码,在硬件层面上可能多个线程并行地调度到不同地处理器上执行,通过并行执行来提高性能,假如 处理器 0 和 处理器 1 同时来执行下边代码,如果处理器 0 的写缓冲器为了提高性能,进行了 内存重排序,先将 loaded = true 的结果更新到 高速缓存,再去更新 loadConfig() 的执行结果,那么如果处理器 0 刚更新完 loaded 的值,还没来得及更新 loadConfig 的值,此时 resource 还是 null,处理器 1 发现 loaded 为 true 了,直接调用 resource.execute() 方法,那么就会出现空指针的问题,这就是内存重排序可能会带来的问题:
Config config = null;
Boolean loaded = false;
// 处理器 0
resource = loadConfig();
loaded = true;
// 处理器 1
while (!loaded) {
try {
Thread.sleep(1000);
} catch (Exception e) {
...
}
}
resource.execute();
为了容易理解 指令重排如何造成空指针问题,我这里也画了一张时间线图:

# synchronized 对原子性、可见性和有序性的保证
学习内存屏障注意事项:
对于内存屏障的内容不要太抠细节,因为对于不同的底层硬件,内存屏障的实现也是不同的,所以在学习的时候,有些文章中是加这个屏障,而另外一些文章又是加其他的屏障,这个都无所谓的,我们只
需要学习到内存屏障是如何保证可见性和有序性的就可以了
这里主要聊一聊 synchronized 底层到底是如何保证原子性、可见性和有序性的
原子性的保证
这里保证的原子性就是当一个线程执行到 synchronized 的同步代码块中时,不会在执行过程中被其他线程中断
synchronized 是基于两个 JVM 指令来实现的:monitorenter 和 monitorexit
那么在这两个 JVM 指令中的代码就是被上了锁的,这一段代码就只有当前加锁的线程可以执行,从而保证原子性
可见性的保证
通过添加一些 内存屏障 来保证,在 synchronized 修饰的同步代码块中所做的 所有变量写操作,都会在释放锁的时候,强制执行 flush 操作,来保证可以让其他处理器中的线程可以感知到变量的更新
而在进入 synchronized 的同步代码块时,会先执行 refresh 操作,来保证读取到最新变量
有序性的保证
也是通过加各种 内存屏障 来保证的,避免指令重排的问题
接下来看一下,在 synchronized 同步代码块中,到底会添加哪些 内存屏障:
int b = 0;
int c = 0;
synchronized (this) { --> monitorenter
--> Load 内存屏障
--> Acquire 内存屏障
int a = b;
c = 1;
--> Release 内存屏障
} --> monitorexit
--> Store 内存屏障
这里可能大家对 Acquire 和 Release 内存屏障有点陌生,但是一定知道 LoadLoad、LoadStore、StoreStore、StoreLoad 屏障,下边说一下他们的关系:
Acquire 屏障 = LoadLoad + LoadStore- Acquire 屏障确保一个线程在执行到屏障之后的内存操作之前,能看到其他线程在屏障之前的所有内存操作的结果
Release 屏障 = LoadStore + StoreStore- Release 屏障用于确保一个线程在执行到屏障之后的内存操作之前,其他线程能看到该线程在屏障之前的所有内存操作的结果
那么对于上边 synchronized 的同步代码块,这里解释一下每个屏障的作用:
- 在
monitorenter指令后,添加Load 屏障,执行 refresh 操作,可以去将其他处理器中修改过的最新数据加载到自己的高速缓存种 - Load 屏障之后,添加了
Acquire 屏障,可以保证当前线程可以读到 Acquire 屏障前所有内存操作的结果 - 在
monitorexit指令前,添加Release 屏障,保证一个线程在执行到屏障之后的内存操作之前,其他线程能看到该线程在屏障之前的所有内存操作的结果 - 在
monitorexit指令后,添加了Store 屏障,对自己在同步代码块中修改的变量执行 flush 操作,刷新到高速缓存或者=主内存中,让其他处理器中的线程可以感知到数据的变化
因此通过 Acquire、Release、Load、Store 屏障来保证了有序性
一句话总结
简单总结一下就是,在 synchronized 代码块开始时,加内存屏障,保证可以感知到屏障前所有的内存操作变化,在 synchronized 结束后,加一个内存屏障,保证可以将内存操作的更新情况立即刷新到高速缓存或者主内存中,可以让其他线程感知到!
# volatile 对可见性、有序性的保证
volatile 是不保证原子性的,只保证了可见性和有序性,底层就是基于各种 内存屏障 来实现的
使用 volatile 关键字之后,加入的内存屏障如下:
volatile boolean flag = false;
--> Release 屏障
flag = true; // volatile 写
--> Store 屏障
--> Load 屏障
if (flag) { // volatile 读
--> Acquire 屏障
// ...
}
主要是在 volatile 写操作和读操作前后都添加内存屏障来保证:
在 volatile 写操作之前,加入了 Release 屏障,保证了 volatile 写和 Release 屏障之前的任何读写操作不会发生指令重排在 volatile 写操作之后,加入了 Store 屏障,保证了写完数据之后,立马会执行 flush 操作,让其他处理器的线程感知到数据的更新在 volatile 读操作之前,加入了 Load 屏障,保证可以读取到这个变量的最新数据,如果这个变量被其他处理器中的线程修改了,必须从其他处理器的高速缓存或者主内存中加载到自己本地高速缓存里,保证读到的是最新数据在 volatile 读操作之后,加入了 Acquire 屏障,禁止volatile 读操作之后的任何读写操作和volatile 读操作发生指令重排
# Java 系统架构安全面试实战
这一个模块讲一下在我们研发的系统中,可能会碰到哪些安全问题,黑客会以什么样的方式来对网站进行攻击
为什么我们作为一个 Java 开发人员,还要去了解安全相关的问题呢?
目前大多数技术人员对于项目安全方面的关注度并不是很高,之前在某几个互联网大厂中都发生过一些删库跑路的问题,影响系统的安全性和数据的安全性,并且如果以后作为一个负责人去带领开发一个项目,项目的安全性是很重要的,因此系统的安全在系统架构中处于一个非常重要的地位,如何去避免被黑客攻击导致系统故障以及避免系统的核心数据遭到泄露是非常重要的一个事情,我们作为开发人员,是一定要去了解常见的一些攻击手段,如果一无所知的话,就证明了我们的能力不够全面,可能就会导致面试结果不理想
我们作为开发人员,对安全方面的掌握程度达到 了解程度 就行,在系统中我们做一些简单的防御措施,之后将专业的安全防护问题交给专业的公司去做就可以了!
# XSS 网络攻击
先说一下 XSS(Cross-Site Scripting,跨站脚本攻击)网络攻击,这是一种常见的网络安全漏洞,它允许攻击者将恶意脚本注入到受害者访问的网页中
XSS 攻击的原理就是:
- 注入恶意脚本:攻击者将恶意脚本代码(html+javascript)嵌入到被攻击网站的前端代码中
- 受害者访问:当受害者访问到被攻击的网站时,这个网站会执行恶意的脚本,由于你认为这些脚本是可靠的,会允许执行
- 窃取用户数据:当恶意脚本被执行后,可能就会窃取用户的个人信息、篡改网页信息或者引导你到攻击者自己的网站中

XSS 攻击分为两种:反射型攻击 和 存储型攻击:
- 反射型攻击:这种类型的攻击通常通过URL参数传播。攻击者会想办法让你点击一个 URL 链接,这个 URL 链接指向的攻击者自己服务器上的一段恶意脚本,当你点击之后,恶意脚本就会被返回到浏览器中执行,之后就会控制你的浏览器中的行为了,这时恶意脚本有了你的 cookie 信息,会以你的个人身犯去去关注某个人或者发布一些内容等等(可以做任何事情)
- 存储型攻击:这种类型的攻击将恶意脚本存储在服务器上,通常是在数据库中。比如攻击者在网站中发布一条评论,其中包含了恶意脚本(js 脚本),那么当你去浏览攻击者发布的这一条评论后,会导致恶意脚本运行,控制你浏览器中的一切行为
XSS 攻击防护手段:
- 消毒机制:在将用户输入的数据输出到HTML页面之前,对其进行编码,以防止脚本执行。例如,将
<编码为<,>编码为>,"编码为",'编码为'等,将恶意脚本的<html>、<script>编码之后,就不会在浏览器中被执行了 - HttpOnly 方式:HttpOnly 用于设置 Cookie 的属性,表示浏览器只允许通过 HTTP 协议发送 Cookie,而不允许通过客户端脚本(如 JavaScript)访问,那么就算恶意脚本执行了,但是他们也无法读取和修改这些 Cookie,可以保护用户信息
# SQL 注入攻击
SQL 注入攻击是攻击者在应用程序的数据库查询中插入恶意SQL代码,导致数据被恶意修改或丢失等问题
这里举个例子:
假设有一个登录表单,用户输入用户名和密码,然后服务器端的代码将这些信息用于数据库查询,以验证用户身份。如果这个查询没有正确处理用户输入,攻击者就可以利用SQL注入。
假设原始的SQL查询是这样的:
SELECT * FROM users WHERE username = '输入的用户名' AND password = '输入的密码';
在没有防护的情况下,如果攻击者在用户名字段输入 ' OR 1=1 --,那么SQL查询将变成(其中 -- 在 SQL 中是注释,后边的 SQL 语句就失效了):
SELECT * FROM users WHERE username = '' OR 1=1 --' AND password = '输入的密码';
由于 OR 1=1 始终为真,所以这个查询会返回所有用户的记录,而 -- 用于注释掉后面的 AND password 部分,这样攻击者就可以绕过密码验证。
SQL 注入防护措施:
保护数据库表结构:不要让别人知道数据库的表结构,不要将一些异常的 SQL 信息给回显到浏览器中,否则就会通过 SQL 语句被推测出来表结构,之后进行 SQL 注入攻击SQL 预编译:MyBatis 中也有防止 SQL 注入的措施,MyBatis 会将#{}的参数作为预编译语句的一部分进行处理,会对参数进行转义处理,那么传入进来的 SQL 语句就会被当作是参数,而不会作为 SQL 执行了,以此来防止 SQL 注入
<select id="selectUserById" resultType="User">
SELECT * FROM users WHERE id = #{id}
</select>
# CSRF 攻击
CSRF(Cross-Site Request Forgery,跨站请求伪造)是一种网络攻击,攻击者利用用户的登录状态发起未经授权的请求,用于查询用户数据、发起交易等等
攻击者可以利用 XSS 跨站点脚本攻击,获取用户 Cookie,再利用 Postman 发送跨站点伪造请求
CSRF 攻击防护措施:
防止 Cookie 被窃取:将网站的 Cookie 设置 HttpOnly 属性,禁止被恶意的 js 脚本窃取 Cookie 信息随机 Token:每次返回一个页面给用户时,都生成一个随机 token 附加在页面的隐藏元素中,同时在 Redis 中再存储一份,当发送请求时,附加上随机 Token,验证通过才可以发送请求,这样如果伪造请求,不知道随机 Token 是什么,也就无法伪造了验证码:页面提交时,使用图形滑动验证码认证,可以避免伪造请求Referer 请求头:Http 请求里有一个 Referer 请求头,带有这个请求的来源,服务端可以验证一下这个请求是不是从自己的页面里来的,如果是的话才执行,否则就拒绝执行
# 用户上传文件,可能会遭到什么样的黑客攻击
如果我们的网站 允许别人上传文件,那么文件可能是可执行的脚本,可能是病毒文件,其实这个是非常危险的,如果是脚本的话,可能会在服务器执行,搞很多破坏,比如黑客黑掉你的服务器,进行勒索之类的
比如攻击者将自己的文件后缀改为 .jpg、.txt 之后进行上传,但是这个文件其实是病毒文件,通过病毒文件可以连接数据库等等,做许多危害系统的操作
上传文件攻击的防护措施
限制上传文件类型:只能上传指定的文件类型,并且限制文件的大小,还要对文件重命名,不能仅仅靠后缀来判断文件类型,还要通过文件二进制数据开头的magic number(魔数,用于标识文件类型)来判断文件类型比如 JPEG 的魔数为:
FFD8FF,PNG 文件的魔数为:89504E47压缩上传文件:压缩后,可以破坏原来的文件结构,避免文件在服务器执行
# DDoS 攻击
DDoS(Distributed Denial of Service,分布式拒绝服务攻击)是一种网络攻击手段,其目的是通过大量的流量或请求来使目标服务器或网络资源不堪重负,从而导致正常用户无法访问这些资源
简单来说,就是给你的服务器发送大量的请求,导致你的服务器线程资源、网络资源、CPU 资源等等全部被占满,导致其他用户无法正常使用
Dos 攻击是一对一的,攻击者通过一台高性能服务器来拼命地给你的网站发送请求,这个很好解决,通过限制 IP 即可
DDoS 是攻击者控制大量的机器,这些机器都被植入木马给控制了,也就是所谓的 肉鸡,使用大量肉鸡给你的网站发送大量请求,导致网站的服务器瘫痪
DDoS 攻击的防护
个人很难防护,一般都是购买云厂商的安全服务来解决
DDoS 攻击的方式:
基于 SYN Flood 的 DDoS 攻击
主要利用了 TCP 三次握手的特性来攻击,TCP 三次握手流程是(TCP 三次握手详细参考 (opens new window)):
1、客户端发送 SYN 请求建立连接
2、服务器收到 SYN 后,返回客户端 SYN+ACK 表示请求接收,等待客户端再次返回 ACK
3、客户端收到服务端发回的 SYN+ACK,返回一个 ACK 给服务端,连接被成功建立
服务端在返回 SYN+ACK 给客户端之后,会给该客户端预留一部分资源,等待与客户端建立连接,那么攻击者就会通过大量机器去和服务端建立连接,但是并不给服务端发送第三次的 ACK,导致服务端建立了大量的半连接在等待列表中,最终资源耗尽
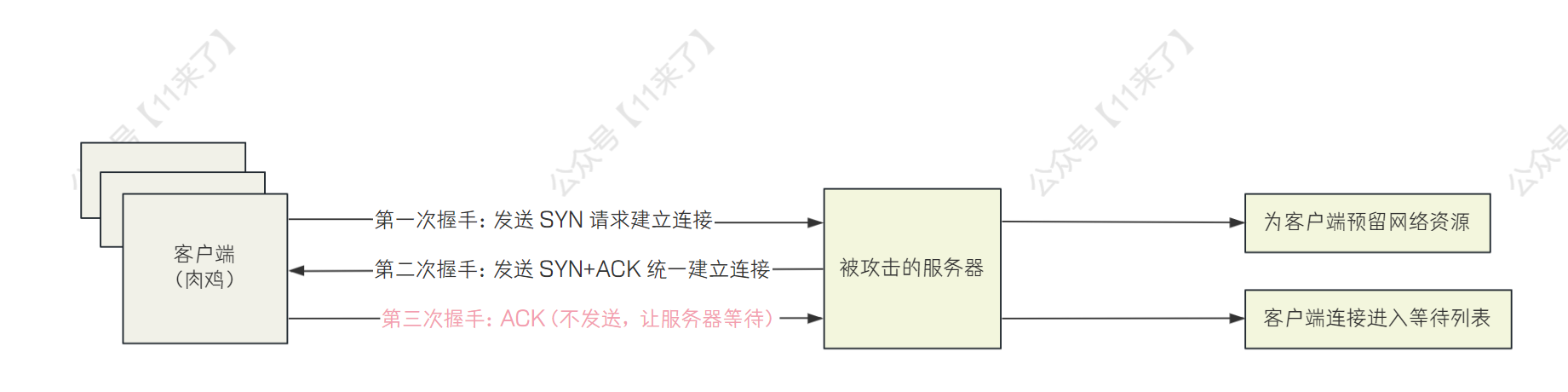
基于 DNS Query Flood 的 DDoS 攻击
这种方式利用DNS(域名系统)服务的特性来消耗目标服务器的资源。这种攻击的基本原理是向目标 DNS 服务器发送大量的 DNS 查询请求,从而占用其带宽和处理能力,导致正常用户无法获得 DNS 解析服务
基于 HTTP Flood 的 DDoS 攻击
这种方式专门针对 Web 服务器的 HTTP 服务。攻击者通过发送大量的 HTTP 请求来消耗服务器的资源,导致正常用户无法访问网站
攻击者通过控制大量肉鸡去给服务器发送大量 HTTP 请求,Web 服务器消耗大量资源对大量 HTTP 请求解析,最终导致 Web 服务器 CPU 过载、内存耗尽、网络带宽打满等情况而瘫痪
比如对于 Nginx 、Tomcat 这两个 Web 服务器来说,都是一个进程启动多个线程来并发处理 HTTP 请求,当 HTTP 请求数量很大,就会导致 Web 服务器瘫痪
# 深挖网络 IO 面试实战
学前须知:
这个模块对网络 IO 这块进行深挖,深入理解了网络 IO 之后,可以跟面试官聊的有来有回,通过深入讨论,你可以展示你对网络 I/O 了解的很深入,以及你如何将这些知识应用到实际的服务器架构和性能优化中,那面试的结果一定是非常不错的
(切记不要对每一块的内容都浅尝辄止,没有技术深度是无法让面试官刮目相看的)
这个模块对网络 IO 这块进行深挖,深入理解了网络 IO 之后,可以跟面试官聊的有来有回,那面试的结果一定是非常不错的
如果每次面试官问一个问题,你都是回答了解一下,那样只会显出你对这块内容的理解太表层!
这个模块对网络 IO 这块进行深挖,深入理解了网络 IO 之后,可以跟面试官聊的有来有回,那面试的结果一定是非常不错的
如果每次面试官问一个问题,你都是回答了解一下,那样只会显出你对这块内容的理解太表层!
只要问到网络 IO 方面,那么一定会去问 Netty 的内容,因为几乎所有的网络通信,只要是用 Java 做的,都是使用 Netty 框架来进行网络通信的,所以 Netty 的东西一定要了解,如果不了解 Netty ,就像你学习 Java 不了解 SpringBoot 一样
# Netty 架构原理图
问到 Netty 了,那么 NIO、BIO、AIO 肯定是要了解的,由于面试突击里之前已经写过这块的内容了,这里就不重复说了
下边说一下 Netty 的架构原理图,从整体架构学习:
Netty 处理流程:
1、BossGroup 和 WorkerGroup 都是线程组,BossGroup 负责接收客户端发送来的连接请求,NioEventLoop 是真正工作的线程,用来响应客户端的 accept 事件
2、当接收到连接建立 Accept 事件,获取到对应的 SocketChannel,封装成 NIOSocketChannel,并注册到 Worker 线程池中的某个 NioEventLoop 线程的 selector 中
3、当 Worker 线程监听到 selector 中发生自己感兴趣的事件后,就由 handler 进行处理

Netty 为什么这么快?
那么 Netty 作为高性能的网络 IO 框架,一定要了解 Netty 在哪些方面保证了高性能:
传输:用什么样的通道将数据发送给对方,BIO、NIO 或者 AIO,IO 模型在很大程度上决定了框架的性能。
IO模型的选择- Netty 使用 NIO 进行网络传输,可以提供非阻塞的 IO 操作,极大提升了性能
协议:采用什么样的通信协议,HTTP 或者内部私有协议。协议的选择不同,性能模型也不同。相比于公有协议,内部私有协议的性能通常可以被设计的更优。
协议的选择- Netty 支持丰富的网络协议,如 TCP、UDP、HTTP、HTTP/2、WebSocket 等,既保证了灵活性,又可以实现高性能
- 并且 Netty 可以定制私有协议,避免传输不必要的数据,进一步提升性能
线程模型:数据报如何读取?读取之后的编解码在哪个线程进行,编解码后的消息如何派发,Reactor 线程模型的不同,对性能的影响也非常大。
线程模型的选择- Netty 使用主从 Reactor 多线程模型,进一步提升性能
零拷贝:Netty 中使用了零拷贝,来提升数据传输速度
# Netty 中的零拷贝了解吗?
Netty 通过零拷贝技术减少数据复制次数,提升性能!
Netty 的 零拷贝 主要在以下三个方面:
Netty 的接收和发送使用堆外内存(直接内存)进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。
Netty 提供 CompositeByteBuf 组合缓冲区类,可以将多个 ByteBuf 合并为一个逻辑上的 ByteBufer,避免了各个 ByteBufer 之间的拷贝,将几个小 buffer 合并成一个大buffer的繁琐操作。
Netty 的文件传输使用了 FileChannel 的 transferTo 方法,该方法底层使用了
sendfile函数(Unix 系统调用函数)实现了 cpu 零拷贝。sendfile函数通过网络发送数据的流程为:(3次拷贝、2次上下文切换,这里上下文切换是在用户空间发起write操作,此时用户态切换为内核态,write调用完毕后又会从内核态切换回用户态)
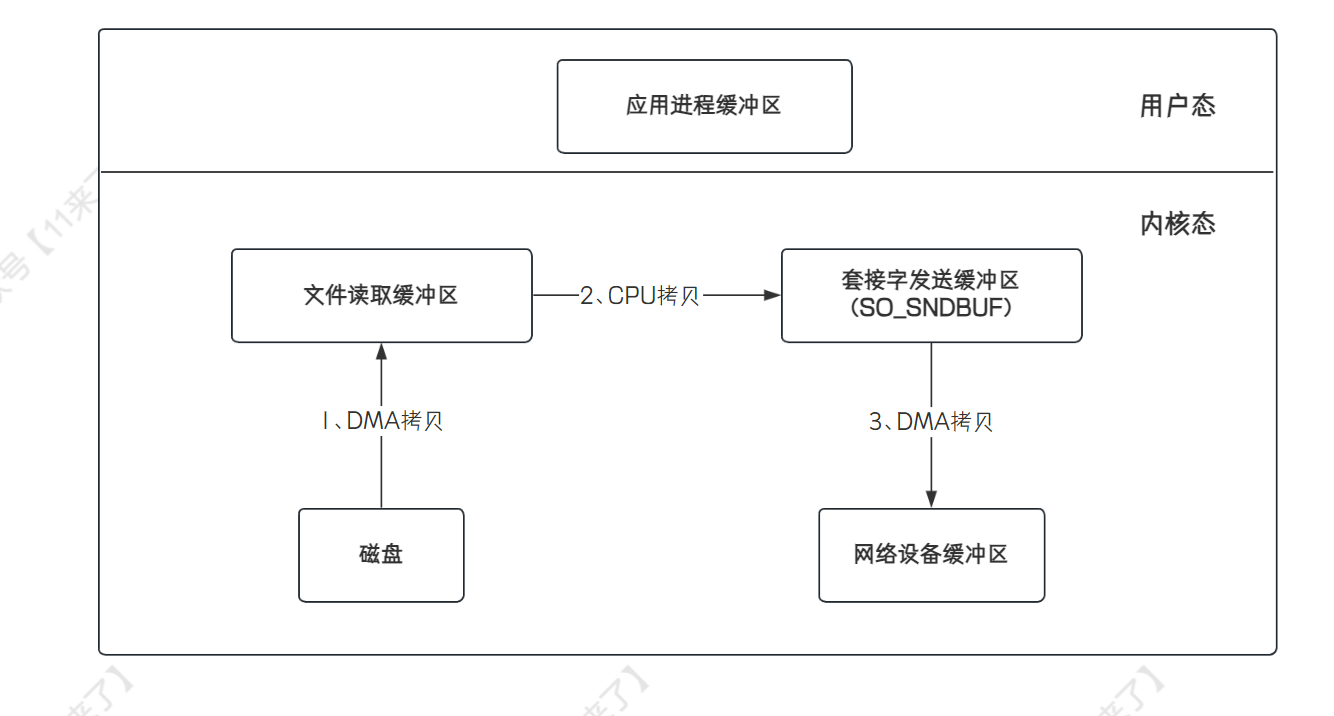
下边画一个直观一些的图片,从
应用程序的角度来看 Netty 的零拷贝: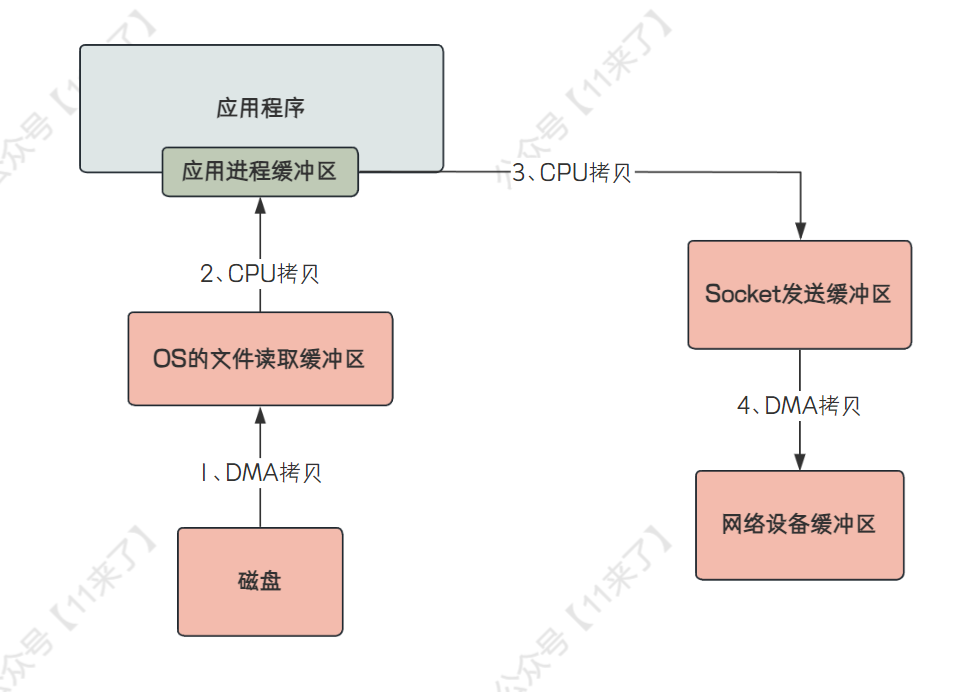
但是不能只了解零拷贝是怎样的,因为技术是过渡的,还要知道不使用零拷贝时,传统 IO 是怎么传输数据的:
- 传统的 IO 操作会有 4 次拷贝,4 次用户态和内核态之间的切换,因此性能是比较低的
- 这里说一下是
哪 4 次内核态的切换- 首先,应用程序去磁盘读取数据进行发送时,此时会从用户态切换到内核态,通过 DMA 拷贝将数据放到文件读取缓冲区中
- 再从内核态切换到用户态,将文件读取缓冲区的数据通过 CPU 拷贝读取到应用进程缓冲区中
- 再从用户态切换到内核态,将数据从应用进程缓冲区通过 CPU 拷贝放到 Socket 发送缓冲区中,之后的数据会从 Socket 发送缓冲区中通过 DMA 拷贝发送到网络设备缓冲区中
- 操作完成之后,再从内核态切换到用户态

# 直接内存了解吗?
直接内存(也称为堆外内存)并不是虚拟机运行时数据区的一部分,直接内存的大小受限于系统的内存
在 JDK1.4 引入了 NIO 类,在 NIO 中可以通过使用 native 函数库直接分配堆外内存,然后通过存储在堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作
使用直接内存,可以避免了 Java 堆和 Native 堆中来回复制数据
在上边提到了 Netty 的零拷贝,其中有一种就是使用了 直接内存来实现零拷贝 的,直接内存的特点就是快,接下来看看为什么使用直接内存更快呢?
直接内存使用场景:
- 有很大的数据需要存储,且数据生命周期长
- 频繁的 IO 操作,如网络并发场景
直接内存与堆内存比较:
- 直接内存申请空间耗费更高的性能,当频繁申请到一定量时尤为明显
- 直接内存IO读写的性能要优于普通的堆内存,在多次读写操作的情况下差异明显
直接内存相比于堆内存,避免了数据的二次拷贝。
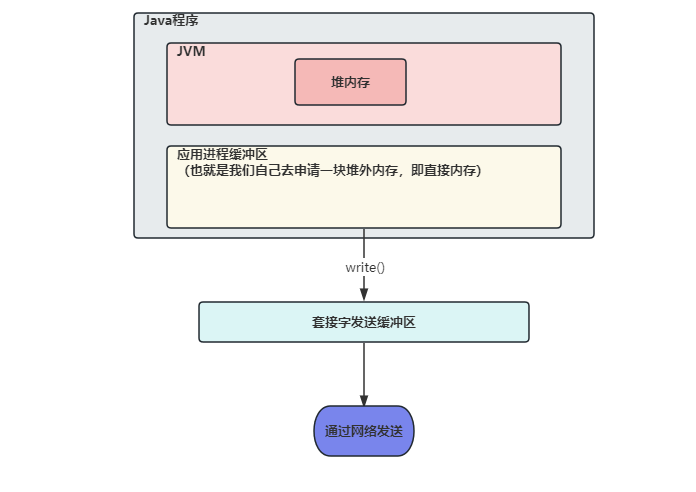
我们先来分析
不使用直接内存的情况,我们在网络发送数据需要将数据先写入 Socket 的缓冲区内,那么如果数据存储在 JVM 的堆内存中的话,会先将堆内存中的数据复制一份到直接内存中,再将直接内存中的数据写入到 Socket 缓冲区中,之后进行数据的发送为什么不能直接将 JVM 堆内存中的数据写入 Socket 缓冲区中呢?在 JVM 堆内存中有 GC 机制,GC 后可能会导致堆内存中数据位置发生变化,那么如果直接将 JVM 堆内存中的数据写入 Socket 缓冲区中,如果写入过程中发生 GC,导致我们需要写入的数据位置发生变化,就会将错误的数据写入 Socket 缓冲区
那么如果使用直接内存的时候,我们将
数据直接存放在直接内存中,在堆内存中只存放了对直接内存中数据的引用,这样在发送数据时,直接将数据从直接内存取出,放入 Socket 缓冲区中即可,减少了一次堆内存到直接内存的拷贝
直接内存与非直接内存性能比较:
public class ByteBufferCompare {
public static void main(String[] args) {
//allocateCompare(); //分配比较
operateCompare(); //读写比较
}
/**
* 直接内存 和 堆内存的 分配空间比较
* 结论: 在数据量提升时,直接内存相比非直接内的申请,有很严重的性能问题
*/
public static void allocateCompare() {
int time = 1000 * 10000; //操作次数,1千万
long st = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
//ByteBuffer.allocate(int capacity) 分配一个新的字节缓冲区。
ByteBuffer buffer = ByteBuffer.allocate(2); //非直接内存分配申请
}
long et = System.currentTimeMillis();
System.out.println("在进行" + time + "次分配操作时,堆内存 分配耗时:" +
(et - st) + "ms");
long st_heap = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
//ByteBuffer.allocateDirect(int capacity) 分配新的直接字节缓冲区。
ByteBuffer buffer = ByteBuffer.allocateDirect(2); //直接内存分配申请
}
long et_direct = System.currentTimeMillis();
System.out.println("在进行" + time + "次分配操作时,直接内存 分配耗时:" +
(et_direct - st_heap) + "ms");
}
/**
* 直接内存 和 堆内存的 读写性能比较
* 结论:直接内存在直接的IO 操作上,在频繁的读写时 会有显著的性能提升
*/
public static void operateCompare() {
int time = 10 * 10000 * 10000; //操作次数,10亿
ByteBuffer buffer = ByteBuffer.allocate(2 * time);
long st = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
// putChar(char value) 用来写入 char 值的相对 put 方法
buffer.putChar('a');
}
buffer.flip();
for (int i = 0; i < time; i++) {
buffer.getChar();
}
long et = System.currentTimeMillis();
System.out.println("在进行" + time + "次读写操作时,非直接内存读写耗时:" +
(et - st) + "ms");
ByteBuffer buffer_d = ByteBuffer.allocateDirect(2 * time);
long st_direct = System.currentTimeMillis();
for (int i = 0; i < time; i++) {
// putChar(char value) 用来写入 char 值的相对 put 方法
buffer_d.putChar('a');
}
buffer_d.flip();
for (int i = 0; i < time; i++) {
buffer_d.getChar();
}
long et_direct = System.currentTimeMillis();
System.out.println("在进行" + time + "次读写操作时,直接内存读写耗时:" +
(et_direct - st_direct) + "ms");
}
}
# 分布式架构面试连环炮
接下来说一下分布式架构中的一些面试连环炮,主要从链路监控、事务提交、这几个方面来说一下
# 分布式系统链路监控
主要说一下分布式系统链路监控实现的原理是什么
分布式系统链路监控主要适用于进行性能监控和故障排查,国内常用的有 CAT(大众点评的) 和 zipkin(Twitter 的)
其实链路监控主要就是做一个框架,包含一个客户端服务端:
- 在需要监控的系统中集成客户端,对一些需要监控的数据,调用链路监控的客户端 API 发送到服务端去
- 服务端将监控数据进行落库以及生成报表
我之前面试的时候,也碰到过一个面试官给我说,让我设计一个分布式系统链路监控的方案,画了一个图如下(这里主要参考了美团点评的 CAT 监控框架,美团技术团队官方文章:[深度剖析开源分布式监控CAT (opens new window)](https://tech.meituan.com/2018/11/01/cat-in-depth-java-application-monitoring.html)):
这里我也简单说一下流程:
- 应用 A 在调用接口时,生成一个唯一的监控 id,这个监控 id 由:请求入口 id + 服务调用 id + 上游服务 id + 调用时间组成,保证 id 的唯一性,并且可以判断这个链路调用方向是如何的
- 之后通过数据监控的客户端将监控数据发送给服务端,可以通过 MQ 发送,也可以自己写一个 Netty 逻辑,通过 Netty 发送
- 服务端收到监控数据后,将数据落库,在 MySQL 和时序数据库中都存放一份,在数据的查询使用时序数据库速度比较快,而时序数据库中不可以修改数据,所以还是要在 MySQL 存储一份(对这里我了解的也不太多,如果感兴趣可以详细了解一下具体数据的存储)
- 之后就是前端生成报表展示了

# 分布式事务中的两阶段提交和三阶段提交
分布式事务的两阶段提交(Two-phase Commit,简称2PC)是分布式系统中用于确保事务原子性的协议。它由两个主要阶段组成:
准备阶段(Prepare Phase):
- 事务协调者(Transaction Coordinator)向所有参与者(Participants)发送准备请求(Prepare Request),询问它们是否准备好提交事务。
- 参与者执行事务操作,但不提交事务。它们将操作结果记录在本地日志中,以便在需要时可以回滚。
- 参与者向协调者发送准备响应(Prepare Response),告知它们是否准备好提交事务。
提交阶段(Commit Phase):
- 如果所有参与者都报告准备就绪(Prepared),协调者向所有参与者发送提交请求(Commit Request),指示它们提交事务。
- 如果有任何一个参与者报告未准备好(Not Prepared),协调者向所有参与者发送回滚请求(Rollback Request),指示它们回滚事务。
- 参与者根据协调者的指令执行提交或回滚操作,并将结果(Commit Acknowledgment 或 Rollback Acknowledgment)发送回协调者。
- 协调者收到所有参与者的确认后,事务提交或回滚过程完成。
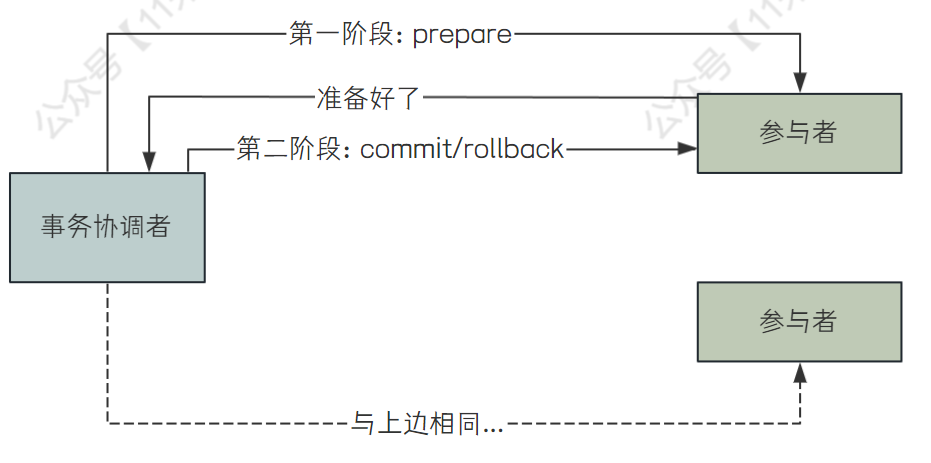
两阶段提交协议的目的是确保分布式事务的一致性。在分布式系统中,事务可能涉及多个节点,每个节点上的操作必须同时成功或同时失败,以保持数据的完整性和一致性。
然而,两阶段提交协议也存在一些问题,主要包括:
- 同步阻塞:在准备阶段,所有参与者必须等待协调者的提交或回滚指令,这可能导致资源锁定和系统响应延迟。
- 单点故障:如果协调者在提交阶段失败,而没有发送提交指令,那么所有参与者将无法提交事务,可能导致数据不一致。
- 协调者过载:协调者需要处理所有事务的提交和回滚请求,这可能导致协调者成为性能瓶颈。
- 超时和网络分区:在网络不稳定的环境中,协调者和参与者之间的通信可能会超时,导致事务无法完成。
为了解决这些问题,有些系统可能会采用改进的两阶段提交协议,或者使用其他分布式事务处理机制,如三阶段提交(3PC)、补偿事务(Compensating Transactions)或最终一致性(Eventual Consistency)等。
分布式协调框架 ZooKeeper 使用的就是 2PC,由于 2PC 是同步阻塞的,因此 zk 适合小集群部署
分布式事务的三阶段提交(Three-phase Commit,简称3PC)是一种用于确保分布式系统中事务的原子性和一致性的协议。它在两阶段提交(Two-phase Commit,简称2PC)的基础上增加了一个额外的阶段,以解决2PC中可能存在的同步问题。三阶段提交包括以下三个阶段:
准备阶段(CanCommit Phase):
- 事务协调者(Coordinator)向所有参与者(Participants)发送
CanCommit消息,询问是否可以执行事务提交操作。 - 参与者收到
CanCommit消息后,会执行事务操作,并将操作结果记录在本地日志中,但不提交事务。 - 参与者会将操作结果(可以提交或不能提交)反馈给协调者。
- 事务协调者(Coordinator)向所有参与者(Participants)发送
预提交阶段(PreCommit Phase):
- 如果协调者收到了所有参与者的
CanCommit响应,并且所有参与者都表示可以提交,协调者会发送PreCommit消息给所有参与者。 - 参与者收到
PreCommit消息后,会执行事务的预提交操作,并将结果(成功或失败)记录在本地日志中,然后向协调者发送Ack消息。 - 如果协调者收到了所有参与者的
Ack消息,或者在超时时间内没有收到任何Ack消息,协调者会认为事务可以提交。
- 如果协调者收到了所有参与者的
提交阶段(DoCommit Phase):
- 协调者向所有参与者发送
DoCommit消息,指示它们提交事务。 - 参与者收到
DoCommit消息后,会正式提交事务,并将提交结果记录在本地日志中。 - 参与者提交事务后,会向协调者发送
Ack消息。 - 协调者收到所有参与者的
Ack消息后,事务提交过程完成。
- 协调者向所有参与者发送

三阶段提交协议的目的是为了解决两阶段提交协议中的同步问题,特别是在网络分区(Network Partition)或协调者故障的情况下。在2PC中,如果协调者在发送Commit消息后崩溃,而参与者没有收到Commit消息,那么参与者将无法提交事务,这可能导致数据不一致。通过引入预提交阶段,3PC允许参与者在提交之前确认他们已经准备好,从而减少了这种不一致性的风险。
然而,三阶段提交协议并没有完全解决2PC的所有问题,它仍然可能面临一些同步问题,例如,如果协调者在发送PreCommit消息后崩溃,而参与者在没有收到DoCommit消息的情况下也崩溃,那么参与者可能会在重启后尝试提交事务,这可能导致数据不一致。因此,在实际应用中,需要根据系统的特定需求和可用资源来选择最合适的事务处理策略。
总结一下:2PC 由于只有两个阶段,性能是比 3PC 要好的,而 3PC 通过增加了一个阶段,提供了更好的故障恢复能力
# 唯一 ID 生成机制中的 Snowflake 算法的时钟回拨问题如何解决?
Snowflake 算法是由Twitter开发的一个分布式ID生成算法,用于在分布式系统中生成唯一且有序的ID。它的核心思想是将一个64位的长整型数字分割成不同的部分,每个部分代表不同的信息,从而确保ID的唯一性和有序性。Snowflake算法的ID结构通常如下:
- 第1位:符号位,始终为0,表示正数。
- 第2-41位:时间戳,使用41位来表示当前时间与预设的起始时间(如1970年1月1日)之间的毫秒差。这样可以支持大约69年的时间范围。
- 第42-52位:数据中心ID,用于区分不同的数据中心。通常使用5位或10位,可以支持最多32个数据中心。
- 第53-62位:机器ID,用于区分不同的机器。同样使用5位或10位,可以支持最多1024台机器。
- 第63-64位:序列号,用于在同一个毫秒内生成多个ID。通常使用12位,可以支持4096个序列号。
在使用 Snowflake 生成的唯一 ID 有 41 位是时间戳,那么假如系统时钟回拨,系统时间比上次生成唯一 ID 的时间小,那么可能会生成重复的 ID
为什么会发送时钟回拨呢?
当前的机器的会跟一台基准时间服务器进行时间校准,如果你的机器的时间跑的稍微快了一点,此时跟基准时间服务器进行了校准,你的时间被校准后就倒退回去了
怎么解决呢?
如果发生了时钟回拨,此时你看看时钟回到了之前的哪一毫秒里去,直接接着在那一毫秒里的最大的 ID 继续自增就可以了
# 性能优化面试实战
# 优化数据库连接池
高并发场景下的数据库连接池应该如何进行优化?
数据库连接池中存放的就是数据库的连接,要对连接池优化,可以从建立连接的超时时间、连接池中的连接数量限制来考虑
简单来说,就是如果建立连接或者发送请求失败,不要一直阻塞等待,设置超时时间,失败了就断开重连就好了!
- maxWait 设置
maxWait参数表示从连接池中获取连接时的最大等待时间,单位是毫秒
推荐设置值为 1000,表示等待 1s 之后还没有获取链接,就算等待超时
如果 maxWait 设置为 -1,那么在高并发场景下,瞬间连接池中的连接都被占用了,大量的请求拿不到连接,无限等待,最终导致 Tomcat 服务器中的线程耗尽,无法对外继续提供服务
- connectionProperties 设置
可以放 connectionTimeout 和 socketTimeout 属性,表示 建立TCP连接的超时时间 和 发送请求后等待响应的超时时间
推荐设置值为:
- connectionTimeout = 1200
- socketTimeout = 3000
不设置这两个值的话,如果高并发场景下,万一碰到了网络问题,导致和数据库的 Socket 连接异常无法通信,那么服务端的 Socket 一直阻塞等待响应,其他请求就无法获取这个连接处理自己的任务
通过设置这两个值,保证在一定时间没有处理完,就算超时,断开连接重连
- maxActive 设置
最大连接池数量,一般建议是设置个20就够了
如果确实有高并发场景,可以适当增加到 3~5 倍,但是不要太多,其实一般这个数字在几十到 100 就很大了,因为这仅仅是你一个服务连接数据库的数量,还有其他的服务,而且数据库整体能承受的连接数量是有限的
连接越多不是越好,数据库连接太多了,会导致 CPU 负载很高,可能反而会导致性能降低的,所以这个参数你一般设置个 20,最多再加几十个就差不多了
# 优化系统 TPS
如果压测的时候发现系统的 TPS 不达标,此时应该如何优化系统?
这里说一下优化系统的思路,首先,TPS 不达标,一定要去检查 SQL,比如存不存在比较慢的 SQL,比如一个 SQL 执行 500ms 或者 1s,那你线程再多,也处理不了多少的请求,所以要先检查慢 SQL,第一步:对数据库建立索引进行优化
接下来检查有没有耗时较长的接口,比如一个接口耗时 500ms 甚至 1s,不过接口耗时太长一般都是 SQL 太慢,如果 SQL 优化过之后,接口耗时还是很长,第二步:可以考虑异步化或多线程进行优化
还可以对 Tomcat 进行优化,通过修改 Tomcat 的参数,Tomcat 默认最大线程数是 200 个,那么可以扩大至 500 个或者 800 个,并且加大 Tomcat 中等待队列的长度以及连接建立数量的限制,主要是 3 个参数:maxThreads、acceptCount、maxConnections,第三步:对 Tomcat 进行优化
代码方面优化做完了,接下来就可以对机器方面进行优化,比如一台服务单机抗 800 个请求,你需要抗 3000 个请求,那么就再扩充 3 台机器,总共 4 台机器,每秒就可以抗 3200 个请求,第四步:扩充机器
# Tomcat 调优
为什么对 SpringBoot 嵌入式的 Web 服务器 Tomcat 进行调优?
Tomcat三大配置maxThreads、acceptCount、maxConnections
最大线程数maxThreads
决定了Web服务器最大同时可以处理多少个请求任务数量
线程池最大线程数,默认值200
最大等待数accept-count
是指队列能够接受的最大等待数,如果等待队列超了请求会被拒绝
默认值100
最大连接数MaxConnections
是指在同一时间,Tomcat能够接受的最大连接数,如果设置为-1,则不限制连接数
最大连接数和最大等待数关系:当连接数达到最大连接数后还会继续接请求,但不能超过最大等待数,否则拒绝连接
最大线程数的值应该设置多少合适呢?
- 需要基于业务系统的监控结果来定:RT(响应时间)均值很低不用设置,RT均值很高考虑加线程数
- 接口响应时间低于100毫秒,足以产生足够的TPS
- 如果没有证据表明系统瓶颈是线程数,则不建议设置最大线程数
- 个人经验值:1C2G线程数200,4C8G线程数800
调优结论:在高负载场景下,TPS提升近1倍,RT大幅降低,异常占比降低
注意:配置修改需确认配置生效,否则再苦再累也白搭!
Tomcat 调优配置
- 修改配置
在 SpringBoot 项目中的 yml 文件中,对嵌入的 Tomcat 进行如下配置:
# Tomcat的maxConnections、maxThreads、acceptCount三大配置,分别表示最大连接数,最大线程数、最大的等待数,可以通过application.yml配置文件来改变这个三个值,一个标准的示例如下:
server.tomcat.uri-encoding: UTF-8
# 思考问题:一台服务器配置多少线程合适?
server.tomcat.accept-count: 1000 # 等待队列最多允许1000个请求在队列中等待
server.tomcat.max-connections: 20000 # 最大允许20000个链接被建立
## 最大工作线程数,默认200, 4核8g内存,线程数经验值800
server.tomcat.threads.max: 800 # 并发处理创建的最大的线程数量
server.tomcat.threads.min-spare: 100 # 最大空闲连接数,防止突发流量
修改之后,我们使用 SpringBoot Actuator 来管理和监听应用程序
- 集成 Actuator
官方文档:https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html#actuator.enabling
- 引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
- 配置文件暴露监控点
# 暴露所有的监控点
management.endpoints.web.exposure.include: '*'
# 定义Actuator访问路径
management.endpoints.web.base-path: /actuator
# 开启endpoint 关闭服务功能
management.endpoint.shutdown.enabled: true
# 暴露的数据中添加application label
management.metrics.tags.application: hero_mall
访问 http://localhost:8081/actuator 可以查看所有配置

找到configprops,访问链接,搜索tomcat查看是否配置成功

# Web 容器优化
将Tomcat容器升级为Undertow
Undertow是一个用Java编写的灵活的高性能Web服务器,提供基于NIO的阻塞和非阻塞API。
- 支持Http协议
- 支持Http2协议
- 支持Web Socket
- 最高支持到Servlet4.0
- 支持嵌入式
SpringBoot的web环境中默认使用Tomcat作为内置服务器,其实SpringBoot提供了另外2种内置的服务器供我们选择,我们可以很方便的进行切换。
- Undertow红帽公司开发的一款基于 NIO 的高性能 Web 嵌入式服务器 。轻量级Servlet服务器,比Tomcat更轻量级没有可视化操作界面,没有其他的类似jsp的功能,只专注于服务器部署,因此undertow服务器性能略好于Tomcat服务器;
- Jetty开源的Servlet容器,它是Java的web容器。为JSP和servlet提供运行环境。Jetty也是使用Java语言编写的。
配置Undertow
- 在spring-boot-starter-web排除tomcat
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
- 导入其他容器的starter
<!--导入undertow容器依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-undertow</artifactId>
</dependency>
- 配置
# 设置IO线程数, 它主要执行非阻塞的任务,它们会负责多个连接
server.undertow.threads.io: 800
# 阻塞任务线程池, 当执行类似servlet请求阻塞IO操作, undertow会从这个线程池中取得线
程
# 默认值是IO线程数*8
server.undertow.threads.worker: 8000
# 以下的配置会影响buffer,这些buffer会用于服务器连接的IO操作,有点类似netty的池化内
存管理
# 每块buffer的空间大小越小,空间就被利用的越充分,不要设置太大,以免影响其他应用,合
适即可
server.undertow.buffer-size: 1024
# 每个区分配的buffer数量 , 所以pool的大小是buffer-size * buffers-per-region
# 是否分配的直接内存(NIO直接分配的堆外内存)
server.undertow.direct-buffers: true
小结:
- 更换了服务容器之后,RT更加平稳,TPS的增长趋势更平稳,异常数(超时3s)几乎为0。
- 在低延时情况下,接口通吐量不及Tomcat。
- 稳定压倒一切,如果只是写json接口,且对接口响应稳定性要求高,可以选用Undertow
# 微信亿级朋友圈的社交系统设计
先来说一下业务需求吧:
- 每个用户可以发朋友圈,可以点赞,评论
- 可以设置权限,不看某些人朋友圈、不让某些人看你的朋友圈
- 可以刷朋友圈中其他人的动态
对于这样的系统设计,主要从业务来考虑如何设计,比如不能让用户等太久,那么从哪些方面可以优化速度,这些思想在所有的系统设计中都是
通用的
# 发送朋友圈的流程
一般发送朋友圈是一段文字 + 几张图片或者视频,那么如果视频和图片较大,上传是比较慢的,如果等上传到服务器之后再返回用户成功,那用户可能要等 2-3 秒,界面一直在转圈,用户肯定会感到很难受哈
因此点击发送朋友圈的操作,要设计成异步的,点击发送之后,先将数据保存在本地缓存里,再通过异步操作将数据上传服务器,保存在本地成功后,就可以返回用户发布成功了,再异步的向服务器上传即可
那么如果不保存在本地,也可以将视频和图片就近上传到 CDN 中(当然也可以先保存在本地,再上传到 CDN 中),传到 CDN 的话也是很快的,之后再将发送请求到服务端,包括图片的 CDN 地址、视频的 CDN 地址、文字内容,并且将朋友圈的权限给写到朋友圈的发布表中去
之后,再通过离线的批处理(后台处理)将你刚刚发布的朋友圈给写入到好友的时间线表中,让好友也可以刷到你发布的朋友圈

那么还有朋友圈的权限设置,比如不让某人看,或者不看某些人,这些权限肯定是要缓存在本地的,而且权限的数据符合写少读多的特性的,用缓存来做很合适,如果你的好友的朋友圈权限设置发生了变化,那么可以发送一个通知,将你和好友的本地缓存都更新成新的数据
那么每次你刷新朋友圈,会根据你和好友的朋友圈的权限结合起来进行判断,看你是否有权限看到这条朋友圈
# 高并发的朋友圈点赞系统架构
点赞功能:可以点赞,可以取消点赞
基于 Redis 来设计点赞系统就可以,微信的朋友圈点赞和评论只有好友之间才可以看到的
每个朋友圈动态都在 Redis 中通过 set 集合来存放谁来给你点赞了,这样点赞的人和数量都可以从 redis 中直接获取,使用 smembers 和 scard 命令
那么你的朋友圈被 A 点赞了,B和你俩也是好朋友,那么 B 刷到你的朋友圈时,对你和 B 的共同好友通过 sismember A 来判断 A 是否给这条朋友圈点赞了,将共同好友的点赞给展示出来
对于评论的话,存在表中,也是将共同好友的评论给展示出来即可
如果是重复点赞其实也没有关系,在 Redis 的 set 中本来就会去重,因此不会出现重复点赞的情况
# 生产环境面试实战
# CPU 占用率 100% 该怎么解决
这属于是生产环境中的问题了,主要考察有没有 linux 中排查问题的经验,以及对 linux 排查问题的命令是否熟悉
1、首先查看 cpu 使用率
显示 cpu 使用率,执行完该命令后,输入 P,按照 cpu 使用率排序
使用 top -c 命令,找到占用 cpu 最多的进程 id(找 java 项目的)
2、查看占用 cpu 最多的进程中每个线程的资源消耗
通过 top -Hp <进程id> 命令,显示这个进程中所有【线程】的详细信息,包括每个线程的 CPU 使用率、内存使用情况、线程状态
找到 cpu 使用率最高的那个 java 进程,记下进程 id
3、将占用 cpu 最高的线程的线程 id 转成 16 进制
通过 printf "%x\n" <线程id> 命令输出这个线程 id 的 16 进制
4、定位哪段代码导致的 cpu 使用率过高:jstack 43987 | grep '0x41e8' -C5--color'
通过命令 jstack <进程id> | grep '<16进制线程id>' -C5--color 定位到占用 cpu 过高的代码
jstack 生成该进程的堆栈信息,通过线程的 16 进制线程 id 过滤出指定线程的信息
-C5 表示显示匹配行的 5 行上下文
--color:高亮显示,方便阅读
# 线上机器的进程用 kill 命令杀不死怎么办?
这也是生产环境的问题,还是考察对 linux 命令了不了解,可以看一下,扩展一下思路
这种情况下,一般是因为你使用 kill 命令杀的这个进程是一个子进程,这是因为子进程释放了资源,但是没有得到父进程的确认,就导致这个子进程变成了 僵尸进程,也就是 zombie 状态
这种情况,一般将这个僵尸进程的父进程给 kill 掉即可
- 先找到这个僵尸进程
使用命令 ps aux,找到 STAT 这一栏为 Z 的进程,就是僵尸进程,记下进程 id
- 找到僵尸进程的父进程 id
使用命令 ps -ef | grep <僵尸进程id>
- 杀死父进程 id
通过 kill 命令杀死父进程即可
# 如果线上机器磁盘快要写满了,该怎么办?
其实线上机器的磁盘写满,基本上都是日志导致磁盘写满了,这里考察的就是 linux 中查看磁盘占用的命令
- 查看磁盘使用情况
使用命令 df -h 查看磁盘的使用情况
- 清楚比较老的日志
找到系统部署的位置,找一下日志在哪里存储,删除掉一些日期比较旧的日志即可
- 预防
可以写一个 shell 脚本,定时删除 7 天之前的日志数据
快捷查找:
可以通过命令
find / -size +100M | xargs ls -lh
快速找到在根目录下,大于 100M 大小的文件
也可以使用命令
du -h > fs_du.log
会扫描当前执行命令的目录以及子目录中磁盘的使用情况,并将结果输出到 fs_du.log 文件中
也可以执行扫描目录,例如扫描 /path 目录下
du -h /path > fs_du.log