 01.哔哩哔哩后端面试
01.哔哩哔哩后端面试
# 1、RocketMQ 5.0 SDK 相比 4.x 做了哪些优化,什么区别?
RocketMQ 5.0 在架构上的变化更加倾向于云原生了
RocketMQ 5.0 的优化主要如下:
- 轻量级 API 和多语言 SDK:RocketMQ 5.0 基于 gRPC 支持多语言 SDK,各语言 SDK API 在本地语言层面对齐,API 非常轻量级,更容易被使用和集成(采用云原生的 gRPC 框架作为通信层的实现)
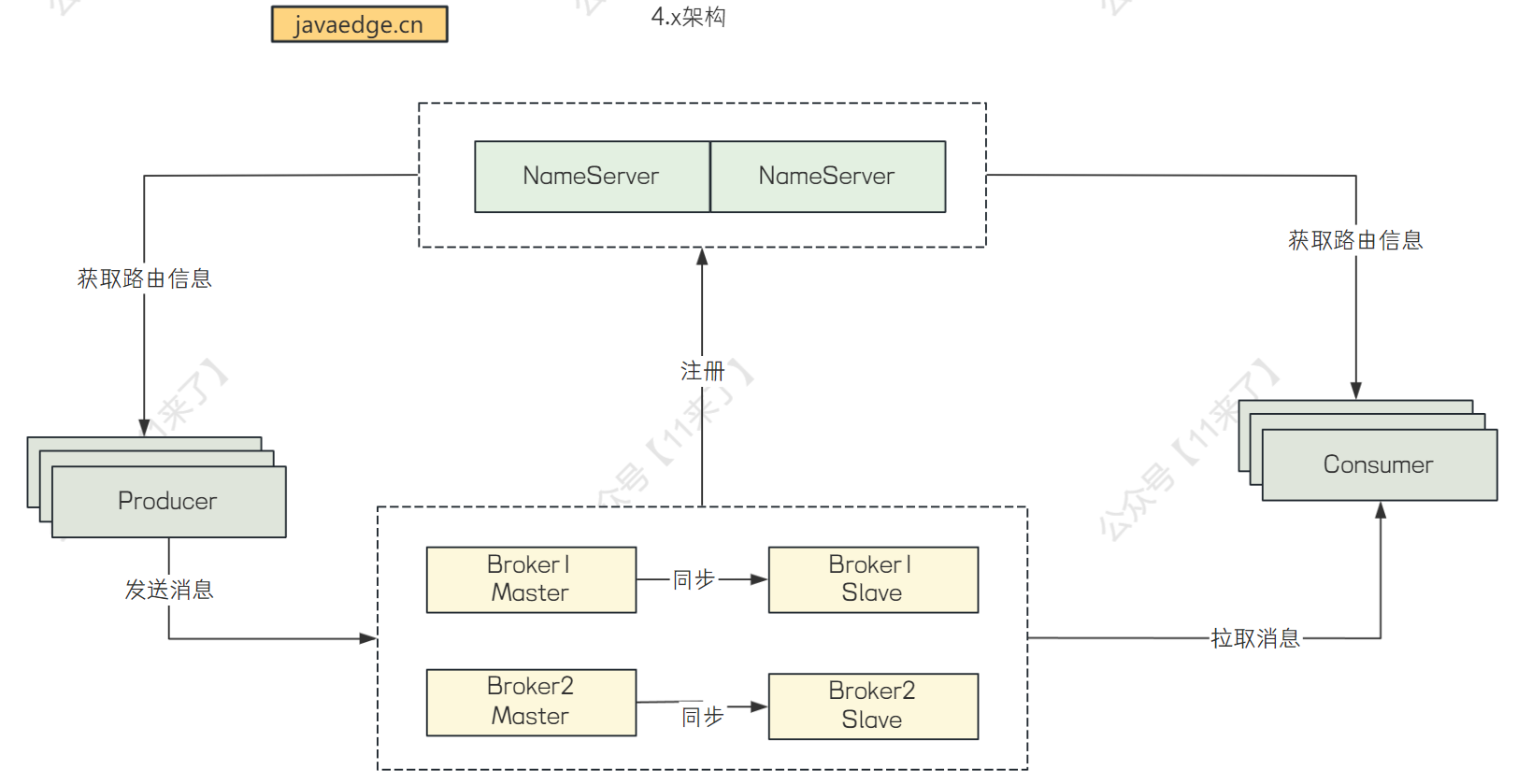
- 实现存储和计算分离:引入了无状态的代理模块(Proxy),将消息管理、权限管理、协议适配等计算功能抽取到 Proxy 模块中,Broker 模块更专注于存储,有利于云原生环境下的资源解耦,架构升级如下:
RocketMQ 4.x 架构:
RocketMQ 5.0 架构:

- 第三点优化:事件、流处理场景的集成,支持消息的流式处理和请计算,全面拥抱 Serverless 和 EDA(这一点有些不太了解,从官网摘抄)
# 2、说说 RocketmMQ 整合 Spring 的过程,为什么要重新整合一套 5.0 的 starter 出来
RocketMQ 整合 Spring 的流程,这里我也没太明白面试官是想要问你自己使用的时候如何整合使用还是 RocketMQ 的 SpringBoot-Starter 中如何整合 RocketMQ 了
(其实 SpringBootStarter 中整合 RocketMQ 也简单,就是 starter 如何创建,以及创建一堆封装好的 Bean,可以给外部直接使用)
这里就说一下使用 RocketMQ 时,如何整合:
- 第一种方式:通过 RocketMQ 提供的原生 Java 客户端库进行整合,这种方式更加灵活,可以自定义消息发送和消费的逻辑
- 第二种方式:通过 SpringBootStarter 整合,这个 starter 中集成了 RocketMQ 的功能,使用起来更加方便
第一种方式整合:
通过引入依赖:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.2</version>
</dependency>
具体的版本根据自己的 RocketMQ 版本来选择
这种方式下,如果要使用 RocketMQ 的功能,需要我们自己去创建对象进行消息的发送和消费,下边给出简单的演示代码:
public class Producer {
public static void main(String[] args) {
// 手动创建对象
DefaultMQProducer producer = new DefaultMQProducer("ExampleProducerGroup");
producer.setNamesrvAddr("localhost:9876");
producer.start();
try {
Message msg = new Message("TopicTest", "TagA", "OrderID001", "Hello world".getBytes());
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.shutdown();
}
}
}
第二种方式整合:
通过引入依赖:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.1.1</version>
</dependency>
这种方式整合的话,可以通过引入 starter 中已经封装好的 RocketMQTemplate 操作类,来操作 RocketMQ:
@SpringBootApplication
public class RocketMQApplication {
public static void main(String[] args) {
SpringApplication.run(RocketMQApplication.class, args);
}
@RestController
public class MessageController {
@Autowired
private RocketMQTemplate rocketMQTemplate;
@GetMapping("/send")
public String sendMessage() {
String result = rocketMQTemplate.convertAndSend("my-topic", MessageBuilder.withPayload("Hello, RocketMQ!").build());
return "Message sent to topic 'my-topic': " + result;
}
}
}
使用 SpringBootStarter 的方式整合 RocketMQ 的话,要注意 RocketMQ 的版本,像上边我引入的 starter 版本是 2.1.1,这个 starter 内部引入的 RocketMQ 客户端的版本是 4.9.2
那么如果你的 RocketMQ 版本使用的是 5.x 的版本,那么你肯定要升级 SpringBootStarter 的版本,来保证和 RocketMQ 版本对应
所以,一般情况下,我们使用第一种方式整合的话,自己控制版本,这样比较清晰一些
这也是为什么要重新整合一套 5.0 的 starter 出来,因为 5.0 中 RocketMQ 发生了变动,很多代码和 4.x 的不兼容,因此要升级迭代
使用 Spring 整合 RocketMQ 客户端工具包:
那么第一种方式,我们总不能每次使用 RocketMQ 都去创建一个新对象吧,可以通过 Spring 来创建一个统一的生产者对象,每次使用的时候,直接注入,而消费者也是同理
- 使用生产者的话:
可以创建一个 DefaultProducer 类,加上 @Component 注解,在构造方法上添加 @Autowired 注解,此时会去 Spring 容器中找到 RocketMQProperties(读取 yaml 中 RocketMQ 的配置),通过 RocketMQ 的配置,创建一个 DefaultProducer 并且注册到 Spring 容器中
@Slf4j
@Component
public class DefaultProducer {
private final TransactionMQProducer producer;
@Autowired
public DefaultProducer(RocketMQProperties rocketMQProperties) {
producer = new TransactionMQProducer(RocketMqConstant.PUSH_DEFAULT_PRODUCER_GROUP);
producer.setCompressMsgBodyOverHowmuch(Integer.MAX_VALUE);
producer.setVipChannelEnabled(true);
producer.setNamesrvAddr(rocketMQProperties.getNameServer());
start();
}
// 启动生产者
public void start() {
try {
this.producer.start();
} catch (MQClientException e) {
log.error("producer start error", e);
}
}
// 关闭生产者
public void shutdown() {
this.producer.shutdown();
}
// 发送消息
public void sendMessage(String topic, String message, String type) {
// ...封装发送信息的操作
}
}
// RocketMQ 配置类
@ConfigurationProperties(prefix = "rocketmq")
public class RocketMQProperties {
// ...
}
- 使用消费者的话:
还是注入 RocketMQ 的配置,再创建消费者,注册到 Spring 的容器中
@Configuration
public class ConsumerBeanConfig {
/**
* 注入 MQ 配置
*/
@Autowired
private RocketMQProperties rocketMQProperties;
/**
* 消费者1
*/
@Bean("consumer1")
public DefaultMQPushConsumer consumer1(ConsumerListener1 consumerListener1) throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer_group_1");
// 设置 nameserver 地址
consumer.setNamesrvAddr(rocketMQProperties.getNameServer());
// 订阅 topic
consumer.subscribe(PLATFORM_COUPON_SEND_TOPIC, "*");
// 注册监听器
consumer.registerMessageListener(consumerListener1);
consumer.start();
return consumer;
}
}
# 3、几种常见消息队列的对比
常见的消息队列有:RocketMQ、Kafka、RabbitMQ、Pulsar
如何选择消息队列呢?
- Kafka:适合于数据量大、吞吐量大的场景,比如日志采集等场景,
- RocketMQ:适合对消息可靠性要求很高、甚至要求支持事务的场景,使用 Java 语言开发,适合用于 Java 项目,如果出现错误,可以在源码级别定位问题
- RabbitMQ:对于中小型公司来说,它使用 erlang 语言本身的并发优势,性能好
- Pulsar:下一代云原生分布式消息流平台,可以集消息、存储、轻量化函数计算为一体
# 4、说说 Raft 算法
Raft 算法是分布式系统中复制日志的一致性算法,保证各个节点日志一致
Raft 算法涉及三种角色:
- Leader:负责处理客户端请求,进行日志复制等操作
- Follower:接收并处理来自 Leader 的消息
- Candidate:向其他节点发送投票请求,通知其他节点来投票,如果赢得了半数以上的选票,就晋升为 Leader
选举 Leader 流程:
1、初始所有节点都是 Follower 状态,并设定一个随机选举超时时间(150ms - 300ms)
2、如果 Follower 在超时时间内都没有收到 Leader 的心跳,则说明 Leader 挂了,则发起选举,将自己的状态改为 Candidate,并向其他 Follower 节点发送请求,让其他节点投自己一票
3、其他节点收到 Candidate 的请求后,将票投给任期最大的 Candidate 节点
4、当 Candidate 接收过半投票,则晋升为 Leader
在 Nacos 中,使用的一致性协议就是 Raft
# 5、有了解其他一致性算法吗?
了解 ZAB 一致性算法,ZooKeeper 中使用的就是 ZAB
ZAB 选举 Leader 流程:
假设 ZooKeeper 集群有 5 台机器,myid(ZooKeeper 服务器的标识) 分别为 1、2、3、4、5
整个选举流程如下:
1、服务器 1 启动,当前只有一台服务器,不会进行 Leader 选举
2、服务器 2 启动,开始 Leader 选举,每个服务器通过 (myid, ZXID) 进行标识,服务器 1 和 2 都投自己一票,然后服务器 1 和 2 交换选票信息,先比较 ZXID,ZXID 比较小的机器将自己的选票信息给 ZXID 比较大的机器,如果 ZXID 相同,就比较 myid,也是 myid 小的机器将选票信息给 myid 大的机器
交换选票信息之后,服务器 1 有 0 票,服务器 2 有 2 票,此时判断服务器 2 是否拥有超过半数的票,服务器 2 拥有 2 票,2(选票数量) <= n/2+1(半数机器) = 2,没有获得超过半数的投票(n/2+1),因此没有产生 Leader
3、服务器 3 启动,开始 Leader 选举,服务器 1、2、3 都投自己一票,由于服务器都是刚启动,ZXID 没有变化,因此交换选票后,发现服务器 3 的 myid 最大,服务器 1、2 将票都给服务器 3,因此服务器 3 有 3 票,3 > n/2+1 = 2,获得了超过半数的投票,因此服务器 3 为 Leader
4、服务器 4 启动,发现已经有 Leader 了,就不需要选举了

# 6、Split-Vote 怎么处理的
Split-Vote 是分裂投票问题,指在分布式系统中,由于网络分区或其他原因,导致集群中的节点无法达成一致,从而可能产生多个 Leader 的情况
在 Raft 中,使用任期编号和日志的完整性来解决分裂投票问题,任期编号更大、日志更完整的 Candidate 会更有可能选举为 Leader
在 ZAB 中,使用 ZXID 和 myid 来解决分裂投票的问题,ZXID 更大的机器会选举成为 Leader,如果 ZXID 相同,则比较 myid
ZXID 表示事务 ID,用户的写请求越多,ZXID(递增) 越大,数据越完整
# 7、JDK 中的集合:ArrayList、LinkedList、HashMap、HashTable、ConcurrentHashMap
这里就是 JDK 源码常见的问题了
这里我就不贴出来了,之前已经写过很多篇相关的内容了,如果需要可以自行搜索一下
主要说一下会问哪些问题:ArrayList、LinkedList 底层原理,一个底层是数组,另一个底层是链表
HashMap 底层数据结构?什么时候会扩容?什么时候链表转为红黑树?线程安全吗?
HashTable 线程安全吗?效率高吗?如何保证线程安全(synchronized)? 这个效率不高,使用的不算多,一般使用 ConcurrentHashMap
ConcurrentHashMap 线程安全如何保证?锁的粒度怎样?
# 8、线程的状态以及线程状态的转换
线程的状态有 6 种:新建 New、就绪 Ready、运行中 Running、阻塞 Blocker、超时等待 Timed Waiting、退出 Terminated
接下来说一下各个状态之间如何转变:

接下来说一下上边出现的几个方法的含义:
- wait() 和 sleep():
wait() 来自 Object 类,会释放锁
sleep() 来自 Thread 类,不会释放锁
- interrupt()
用于停止线程,给线程发出一个中断信号,但是并不会立即中断,会设置线程的中断标志位为 true
一般停止线程都会使用 interrupt() 方法,但是这个方法并不会立即中断正在运行的线程,想要立即停止线程,可以使用 sleep() 和 interrupt() 搭配使用:
从下边输出可以看到,当子线程 sleep() 时,我们在 main 线程中调用了子线程的 interrupt(),那么子线程就会抛出 InterruptedException(只要 sleep() 和 interrupt() 方法碰到一起,就一定会抛出异常,我们可以使用抛出异常的方法,来优雅的停止线程的执行)
public static void main(String[] args) {
try {
Thread thread = new Thread(()->{
try {
// 让子线程先 sleep
System.out.println("run begin");
Thread.sleep(2000);
System.out.println("run end");
} catch (InterruptedException e) {
System.out.println("子线程 sleep 过程中被 interrupt,导致抛出 InterruptedException");
e.printStackTrace();
}
});
thread.start();
// 让主线程等子线程启动起来
Thread.sleep(200);
// 调用子线程的 interrupt()
thread.interrupt();
} catch (InterruptedException e) {
System.out.println("主线程捕获中断异常");
}
System.out.println("end");
}
// 程序输出
run begin
end
子线程 sleep 过程中被 interrupt,导致抛出 InterruptedException
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at com.alibaba.craftsman.command.PaperMetricAddCmdExe.lambda$main$0(PaperMetricAddCmdExe.java:42)
at java.lang.Thread.run(Thread.java:748)
- yield()
让当前线程放弃对 cpu 的占用,放弃的时间不确定,有可能刚刚放弃,马上又获得了 cpu 的时间片
- join()
用于阻塞等待另一个线程执行完毕
public static void main(String[] args) {
try {
MyThread thread = new MyThread();
thread.start();
// 主线程等待子线程运行完毕
thread.join();
System.out.println("主线程等待子线程运行完毕,再执行后来的操作");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
- LockSupport.park()/unpark()
用于阻塞当前线程,可以通过另一个线程调用 LockSupport.unpark() 方法来唤醒它
# 9、Future 获得结果怎么处理
Future 可以用于获取异步计算的结果,Future 的使用比较简单,主要有以下四个方法:
// 检查任务是否完成
boolean isTaskDone = future.isDone();
// 等待任务完成
Object result = future.get();
// 带超时的等待
Object result = future.get(1, TimeUnit.SECONDS);
// 取消任务
boolean isCancelled = future.cancel(true);
使用 Future 时,需要正确处理抛出的异常:
InterruptedException表示在等待过程中线程被中断ExecutionException表示任务执行过程中抛出了异常
try {
Object result = future.get();
} catch (InterruptedException e) {
// 处理中断异常
Thread.currentThread().interrupt(); // 重新设置中断状态
} catch (ExecutionException e) {
// 处理执行异常,这通常意味着任务抛出了异常
} catch (TimeoutException e) {
// 如果设置了超时时间,但没有在规定时间内完成任务
}
# 10、JUC 工具类用过哪些?
上边既然说到了 Future,接下来可以说一下 CompletableFuture,因为 CompletableFuture 使用的还是比较多的,通过 CompletableFuture 大大加快任务的计算速度
其实 CompletableFuture 用起来也比较简单,将一些比较耗时的操作,比如 IO 操作等结果放到 CompletableFuture 中去,当需要用的时候,再从 CompletableFuture 中取出来即可
当然在实际使用中还有一些问题需要注意:
第一点:使用自定义的线程池,避免核心业务和非核心业务竞争同一个池中的线程
如果在使用中,没有传入自定义线程池,将使用默认线程池 ForkJoinPool 中的共用线程池 CommonPool(CommonPool的大小是CPU核数-1,如果是IO密集的应用,线程数可能成为瓶颈)
如果执行两个任务时,传入了自定义的线程池,使用 thenRun 和 thenRunAsync 还有一点小区别;
- 当使用
thenRun执行第二个任务时,将会使用和第一个任务相同的线程池 - 当使用
thenRunAsync执行第二个任务时,那么第一个任务会使用自己传入的线程池,而第二个任务则会使用ForkJoin线程池。(thenAccept、thenApply同理)
在实际使用时,建议使用自定义的线程池,并且根据实际情况进行线程池隔离。避免核心业务与非核心业务竞争同一个池中的线程,减少不同业务之间相互干扰
第二点:线程池循环引用导致死锁
public Object doGet() {
// 创建一个有 10 个核心线程的线程池
ExecutorService threadPool1 = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(100));
CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
//do sth
return CompletableFuture.supplyAsync(() -> {
System.out.println("child");
return "child";
}, threadPool1).join();//子任务
}, threadPool1);
return cf1.join();
}
对于上边代码,如果同一时刻有 10 个请求到达,threadPool1 被打满,而 cf1 的 子任务也需要使用到 threadPool1 的线程,从而导致子任务无法执行,而且父任务依赖于子任务,也无法结束,导致死锁
而像其他一些 JUC 的工具类也要了解:
- Semaphore:信号量,用于控制访问特定资源的线程数量
- CountDownLatch:可以阻塞线程,等待指定数量的线程执行完毕之后再放行,直到所有的线程都执行完毕之后,才可以将所有线程放行。比如需要读取 6 个文件的数据,最后合并 6 个文件的数据,那么就可以创建 6 个线程读取,并且使用 CountDownLatch 让主线程阻塞等待子线程读取完毕塞,当所有子线程都读取完毕之后,再放行
# 11、JVM 实战过吗,了解命令吗?
这里说一下 JVM 相关的命令吧,先不说 JVM 调优的内容了,说起来太多了
- jps:查看 Java 进程,主要用于获取 Java 进程的 pid
- jstat:查看运行时堆的相关情况
# 进程 ID 515460 ,采样间隔 250 ms,采样数 4
jstat -gc 515460 250 4
- jinfo:查看正在运行的 Java 程序的扩展参数
# 打印虚拟机参数
jinfo -flags <pid>
- jmap:查看堆内存的使用情况
# 生成堆转储快照 dump 文件,如果堆内存较大,该命令比较耗时,并且该命令执行过程中会暂停应用,线程系统慎用
jmap -dump:format=b,file=heapdump.hprof 13736
- jhat:hat 命令会解析 Java 堆转储文件,并且启动一个 web server,再用浏览器就可以查看 dump 出来的 heap 二进制文件
jhat ./heapdump.hprof
- jstack:用于生成 Java 虚拟机当前时刻的线程快照,生成线程快照的主要目的是定位线程出现长时间停顿的原因
这里扩展一个使用 jstack 打印线程快照信息,来解决 CPU 占用 100% 问题的解决方案:
# 显示 cpu 使用率,执行完该命令后,输入 P,按照 cpu 使用率排序
top -c
# 找到 cpu 使用率最高的那个 java 进程,记下进程 id
# 显示这个进程中所有【线程】的详细信息,包括每个线程的 CPU 使用率、内存使用情况、线程状态
top -Hp <进程id>
# 找到占用 cpu 使用率最高的线程,记下线程 id
# 将线程 id 通过下边这行命令转成 16 进制
printf "%x\n" <线程id>
# 定位哪段代码导致的 cpu 使用率过高:jstack 43987 | grep '0x41e8' -C5--color'
# jstack 生成该进程的堆栈信息,通过线程的 16 进制线程 id 过滤出指定线程的信息
# -C5 表示显示匹配行的 5 行上下文
# --color:高亮显示,方便阅读
jstack <进程id> | grep '<16进制线程id>' -C5--color