 08.腾讯音乐校招Java后端一面
08.腾讯音乐校招Java后端一面
# 题目分析
# 1、手写 LRU
LRU(Least Recently Used) 其实是一种数据淘汰策略,当数据达到容量上限之后,就会去淘汰最久未使用的数据,Redis 中也有 LRU 内存淘汰策略,用于淘汰位于内存中的数据
我们将 LRU 定义为双向链表,这样以 O(1) 的复杂度就可以取出表头的表尾的节点,将最近使用过的数据放在表头,最不常使用的数据放在表尾,并且向链表中放入一个虚拟头节点,避免链表为空,主要有两个核心操作:
1、插入元素:如果插入的元素在链表中已经有了,就更新 value;如果没有的话,就插入到链表头
2、获取元素:如果元素不在链表中,返回 Null;如果元素在链表中,将链表移动到表头,表示这个元素比较常用
接下来给出代码实现:
package com.zzu.utils;
import java.util.HashMap;
import java.util.Map;
public class LRUCache {
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(2);
lruCache.put(1, 1);
lruCache.put(2, 2);
lruCache.printLRUCache();
lruCache.put(3, 3);
System.out.println("淘汰后:");
lruCache.printLRUCache();
}
private static class Node {
int key, value;
Node prev, next;
Node(int k, int v) {
key = k;
value = v;
}
}
private final int capacity;
private final Node dummy = new Node(0, 0); // 虚拟头节点
private final Map<Integer, Node> keyToNode = new HashMap<>();
public LRUCache(int capacity) {
this.capacity = capacity;
dummy.prev = dummy;
dummy.next = dummy;
}
public int get(int key) {
Node node = getNode(key);
return node != null ? node.value : -1;
}
public void put(int key, int value) {
Node node = getNode(key);
if (node != null) {
node.value = value;
return;
}
node = new Node(key, value);
keyToNode.put(key, node);
pushFront(node);
if (keyToNode.size() > capacity) {
Node backNode = dummy.prev;
keyToNode.remove(backNode.key);
remove(backNode);
}
}
// 获取对应节点
private Node getNode(int key) {
if (!keyToNode.containsKey(key)) {
return null;
}
// 将最近用到的节点放到链表头
Node node = keyToNode.get(key);
remove(node);
pushFront(node);
return node;
}
private void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
}
// 将节点移动到链表头
private void pushFront(Node x) {
x.prev = dummy;
x.next = dummy.next;
x.prev.next = x;
x.next.prev = x;
}
// 打印 LRU 中存储的数据情况,方便看出哪些数据被淘汰
public void printLRUCache() {
Node node = dummy.next;
while (node != dummy) {
System.out.print("k=" + node.key + ":v=" + node.value + " ");
node = node.next;
}
System.out.println();
}
}
# 2、HTTPS 客户端校验证书的细节?
HTTPS 客户端校验证书,这里的证书就是 数字证书 ,网站在使用 HTTPS 之前都会去 CA 机构申请一份数字证书,数字证书包含了:持有者信息、公钥等信息
当客户端与服务器进行通信时,服务器将证书传输给浏览器,这个证书中包含了:
- 证书明文数据:这里用 T 表示
- 数字签名:CA 机构拥有非对称加密的私钥和公钥,CA 机构先对证书明文数据 T 进行哈希,对哈希后的值用私钥进行加密,得到数字签名 S
当客户端拿到证书后,对证书验证的流程如下:
- 拿到证书后,得到明文数据 T,数字签名 S
- 使用 CA 机构的公钥对数字签名 S 进行解密,得到 S2
- 使用证书里的 hash 算法对明文数据 T 进行哈希,得到 T2
最后如果 S2 和 T2 相等,那么说明证书可信:

# 3、对称加密和非对称加密的区别?HTTPS 使用的哪个?
HTTPS 使用的 对称加密 + 非对称加密 两者结合的算法
HTTPS 在 HTTPS 握手的时候,使用的是非对称加密,服务器会发送给浏览器数字证书,包含了公钥,浏览器使用公钥加密一个随机生成的 对称密钥 ,发送给服务器
当浏览器和服务器建立通信之后,使用对称密钥来进行数据的加密解密,这个过程使用的对称加密
为什么要使用两种加密算法的结合呢?
- 对称加密:加密解密过程中使用相同的密钥,速度很快,但是如何让双方都安全的拿到这个密钥比较困难(因此和非对称加密结合,来安全的传输这个对称密钥)
- 非对称加密:加密解密过程中使用一对密钥,即公钥和私钥。公钥是公开的,用于加密;私钥只能自己拿到,用于解密,整个过程相对复杂,比较耗时,一般用于密钥的交换
通过了解这两种算法的区别,也就知道了为什么要使用这两种算法的结合了,HTTPS 既想要对称加密的性能,又想要非对称加密的安全性!
整个 HTTPS 使用非对称加密以及对称加密的流程如下:

# 4、怎么防止下载的文件被劫持和篡改?
这里说一下我自己的思路,其实跟上边的 HTTPS 中校验证书的流程是差不多的
服务器提供文件下载的功能,在服务器端,先对文件数据进行一个加密,生成一个加密后的值称为指纹,这里设为 S,服务器会将指纹 S 公布出来
当用户下载了文件之后,也对文件中的数据以相同方式进行加密,生成一个加密后的值,这里设为 T,如果 T 和 S 相同,那就证明下载的文件没有被劫持和篡改
加密的时候通过散列函数进行加密,通过散列函数加密的结果是不可逆的,所以说每个文件所生成的指纹都是唯一的,如果文件被篡改的话,加密后的值一定和原文件的指纹不同
# 5、HashMap 的 put 流程?
这个算是比较常规的面试题了,当向 HashMap 中 put 元素时,流程如下:
- 先计算 key 的哈希值(这里让 key 的 hashCode 的高 16 位也尽量参与运算,让位置更加平均:
(h = key.hashCode()) ^ (h >>> 16)) - 通过哈希值对数组长度进行取模就可以得到当前节点在数组中存储的下标了
- 如果数组的该位置上没有元素,就直接创建一个节点放到该位置
- 如果数组的该位置上有元素,说明发生了哈希碰撞,判断当前位置上是链表还是红黑树,如果是链表就插入到链表尾,如果是红黑树就以红黑树的方式进行插入
扩展:这里扩展一下为什么 HashMap 中使用红黑树而不是 B+ 树
为什么 HashMap 中使用红黑树而不使用 B+ 树呢?
首先说一下红黑树和 B+ 树有什么区别:
- 红黑树: 是自平衡的二叉搜索树,可以保证树的平衡,确保在最坏情况下将查找、插入、删除的操作控制在 O(logN) 的时间复杂度
- B+ 树: 是多路平衡查找树,多用于数据库系统,B+ 树的特点就是非叶子节点不存储数据,只存储子节点的指针,这样可以减少每个节点的大小,在读取一个磁盘页时可以拿到更多的节点,减少磁盘 IO 次数
那么 HashMap 是在内存中存放数据的,不存在说磁盘 IO 次数影响性能的问题,所以说直接使用红黑树就可以保证性能了,并且实现起来也相对比较简单
# 6、volatile 和 synchronized 的区别?
volatile 是用于保证变量的可见性并且禁止指令重排,保证了变量的有序性和可见性
synchronized 可以保证方法的同步,通过 synchronized 可以保证有序性、可见性和原子性
如果仅仅需要保证变量的可见性,可以使用 volatile
如果需要控制代码块的同步,可以使用 synchronized
这里可以扩展说一下,他们对于可见性和有序性的保证其实都是基于内存屏障来做的
在读取修饰的变量之前,会加一些内存屏障,这个内存屏障的作用就是让当前线程读取这个变量时可以读取到最新的值
在更新修饰的变量之后,也会加一些内存屏障,作用是可以让更新后的值被其他线程感知到
通过这个内存屏障可以让多个线程可以互相之间感知到对变量的更新,达到了可见性的作用
而有序性也是同理,通过内存屏障,来禁止内存屏障对指令进行重排
# 7、乐观锁如何实现,有哪些缺点?
常见的乐观锁的实现有两种方式:数据库和 CAS
- 通过数据库实现乐观锁:
通过版本号实现乐观锁,如下面 SQL
UPDATE table_name SET column1 = new_value, version = version + 1 WHERE id = some_id AND version = old_version;
如果 version 未被修改,则允许更新;如果 version 已被修改,则拒绝更新操作
- 通过 CAS 实现乐观锁:
CAS 的原理就是,去要写入的内存地址判断,如果这个值等于预期值,那么就在这个位置上写上要写入的值
乐观锁的缺点:
乐观锁适用于并发冲突较少的场景,因为它避免了在读取数据时加锁,从而减少了锁的开销
但是在高并发环境中,如果冲突频繁,乐观锁可能导致大量的重试操作,从而影响性能。在这种情况下,可能需要考虑使用悲观锁或其他并发控制策略
# 8、SpringBoot 的工作机制?
这里问的应该就是 SpringBoot 自动装配的原理了
SpringBoot 项目特殊的地方就在于入口,通过 @SpringBootApplication 注解标注了 main() 方法用于启动项目,那么自动装配就是通过这个注解来实现的,通过自动装配来将一些默认的 Bean 以及第三方 jar 包所提供的一些 Bean 给加载到 Spring 的容器中:
@SpringBootApplication
public class HelloApplication {
public static void main(String[] args) {
SpringApplication.run(HelloApplication.class, args);
}
}
接下来,我们看一看这个 @SpringBootApplication 注解到底包含了什么东西:
// ... 省略非核心注解
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(/*太长,省略部分内容*/)
public @interface SpringBootApplication {
}
其实就是包含了一些子注解,其中有 3 个注解是是比较核心的:@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan
接下来分别说一下这 3 个注解是做什么的
- @ComponentScan
先从最简单的注解说起,这个注解应该都比较熟悉,用于扫描当前类所在的包下的类到 Spring 的容器中去,将类都扫描成 Spring 的 Bean
- @SpringBootConfiguration
// ... 省略非核心注解
@Configuration
public @interface SpringBootConfiguration {
}
这个注解其实就是 @Configuration 包装而成的,表明自己是一个配置类
比如我们平时需要向 Spring 中注入一些 Bean 的话,就定义一个配置类再加上 @Configuration 注解,告诉 Spring 我写的这个类是配置类,需要进行扫描
- @EnableAutoConfiguration
// ... 省略非核心注解
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
}
这个注解的作用就是开启自动配置的功能,也就是帮助我们自动载入程序运行所需要的默认配置,这个注解是由连两个注解组成:@AutoConfigurationPackage、@Import
**@AutoConfigurationPackage:**这个注解内部也是 @Import 注解,通过 @Import 注解导入一个类,Spring 在扫描的时候,会去扫描到 @Import 导入的类,并且执行这个类中的指定方法
那么 @AutoConfigurationPackage 注解中 @Import 的这个类的作用,就是去将 SpringBoot 主启动类所在的包及其子包下的类扫描到 Spring 的容器中去
**@Import:**接下来说一下 @Import 注解导入的类 AutoConfigurationImportSelector 的作用,他的作用就是扫描所有 jar 包下的 META-INF/spring.factories 文件,spring.factories 中的数据是以 key-value 的形式存放的,里边写了需要加载的自动配置类的全路径,通过 @Import 注解将 spring.factories 文件加载进来,并且去加载该文件中配置的自动配置类
在写 SpringBoot Starter 的时候,就需要在 spring.factories 文件中写自动配置类,来让 Spring 扫描到我们写的 starter 中的配置类
这里如果不清楚一些细节的东西的话,也不要紧,可以先把整体的流程理清楚,具体细节再慢慢通过学习 Spring 源码深入了解
# 9、缓存雪崩解决方案?
缓存雪崩造成的原因是:大量缓存数据在同一时间过期或者Redis宕机,此时如果有大量的请求无法在 Redis 中处理,会直接访问数据库,从而导致数据库的压力骤增,甚至数据库宕机
缓存过期解决:
- 给过期时间加上一个随机数
- 互斥锁,当缓存失效时,加互斥锁,保证同一时间只有一个请求来构建缓存
- 缓存预热,在系统启动前,提前将热点数据加载到缓存中,避免大量请求同时访问数据库
Redis故障解决:
- 服务熔断或请求限流
- 构建 Redis 缓存高可靠集群
# 10、多级缓存如何保证数据一致性?
这里说一下使用 Redis 缓存 + MySQL 如何保证数据一致性(对于本地缓存 + Redis 缓存也是同理):
那么保证数据一致性就需要保证数据库和缓存同时进行更新,那么就分为两种情况先更新数据库还是先更新缓存,由于更新缓存成本比较高(因为写入数据库的值有时候不是直接写入缓存而是经过一系列计算之后才写入缓存,因此当数据修改时不更新缓存,直接将缓存删除),那么就分为了 先删除缓存再更新数据库 和 先更新数据库,再删除缓存 两种情况:
先删除缓存,再更新数据库(操作简单)这种情况造成的缓存不一致为:线程 A 先删除缓存,再去更新数据库,在线程 A 更新数据库之前,如果线程 B 去读取缓存,发现并不存在,去读取数据库,此时读取的是旧数据,再将旧数据写入缓存,此时缓存存储的就是脏数据了。
使用
更新数据库 + 延时双删可以解决此情况的数据不一致,在延时双删中,会删除两次缓存,分为以下几步:1. 删除缓存 2. 更新数据库 3. 睡眠 Thread.sleep() 4. 再删除缓存即延时双删在线程 A 更新完数据库之后,休眠一段时间,再去删除缓存中可能存在的脏数据。
使用延时双删的话,因为需要隔一段时间再去删除缓存,可能会导致整个操作耗时过长,因此可以将第二次删除缓存的操作异步化
先更新数据库,再删除缓存这种情况可能因为线程 A 没有及时删除缓存或者删除缓存失败而导致线程 B 读取到旧数据
因此当缓存删除失败时,可以使用消息队列来重试,流程如下:
- 先将要删除的缓存值或者是要更新的数据库值暂存到消息队列中
- 当程序没有成功删除缓存值或者更新数据库值时,从消息队列中读取这些值,再次进行删除或更新
- 如果成功删除缓存或者更新数据库,要将这些值从消息队列中取出,以免重复操作
上边两种保证数据一致性的方法,操作上比较简单,性能也比较好,但是整个缓存删除的操作和业务代码耦合度比较高并且不能保证严格的一致性,如果需要更严格的一致性保障可以选择通过 Canal + MQ 的组合来保证,但相对应的就是会提升系统的复杂性,可以根据具体需求来进行选择
Canal + MQ 方式保证数据一致性::通过 Canal + RocketMQ 实现缓存数据库的一致性
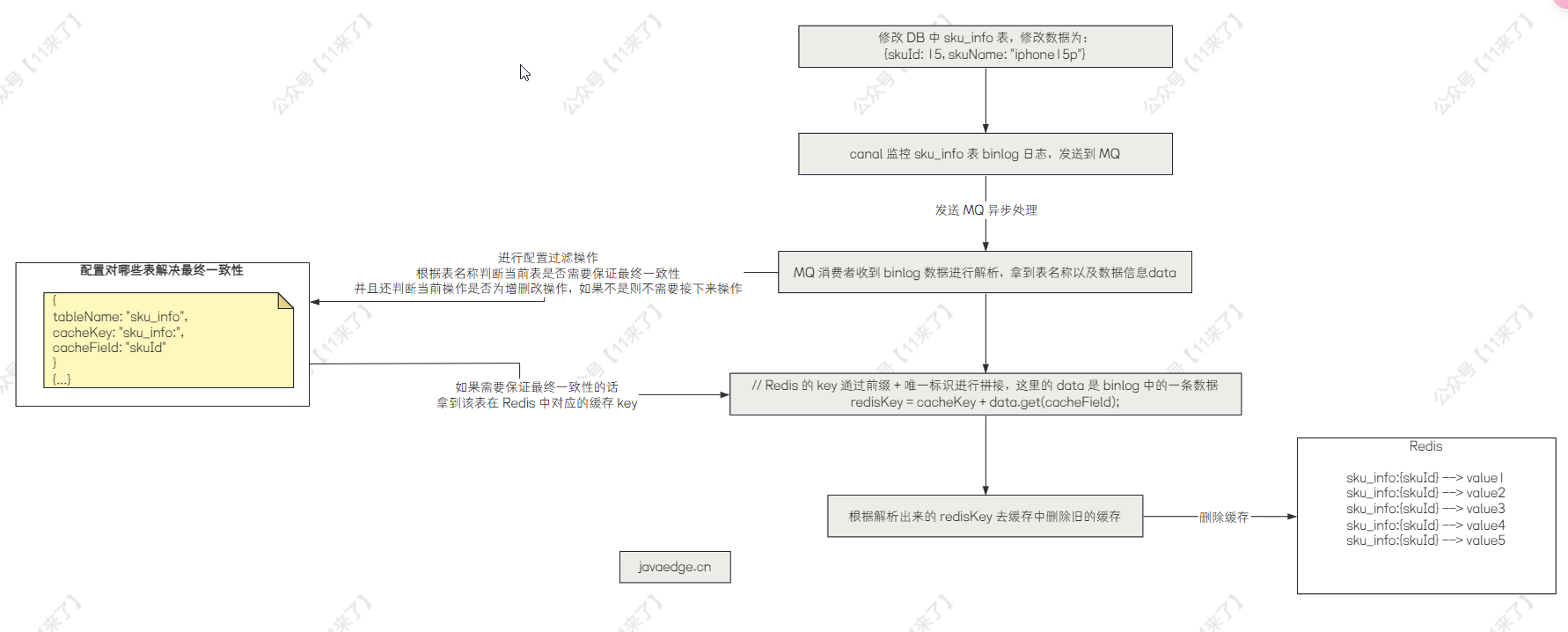
通过 canal + RocketMQ 来实现数据库与缓存的最终一致性,对于数据直接更新 DB 的情况,通过 canal 监控 MySQL 的 binlog 日志,并且发送到 RocketMQ 中,MQ 的消费者对数据进行消费并解析 binlog,过滤掉非增删改的 binlog,那么解析 binlog 数据之后,就可以知道对 MySQL 中的哪张表进行 增删改 操作了,那么接下来我们只需要拿到这张表在 Redis 中存储的 key,再从 Redis 中删除旧的缓存即可,那么怎么取到这张表在 Redis 中存储的 key 呢?
可以我们自己来进行配置,比如说监控 sku_info 表的 binlog,那么在 MQ 的消费端解析 binlog 之后,就知道是对 sku_info 表进行了增删改的操作,那么假如 Redis 中存储了 sku 的详情信息,key 为 sku_info:{skuId},那么我们就可以在一个地方对这个信息进行配置:
// 配置下边这三个信息
tableName = "sku_info"; // 表示对哪个表进行最终一致性
cacheKey = "sku_info:"; // 表示缓存前缀
cacheField = "skuId"; // 缓存前缀后拼接的唯一标识
// data 是解析 binlog 日志后拿到的 key-value 值,data.get("skuId") 就是获取这一条数据的 skuId 属性值
// 如下就是最后拿到的 Redis 的 key
redisKey = cacheKey + data.get(cacheField)
那么整体的流程图如下:
# 11、MySQL 索引失效的几种情况?
接下来说一下 MySQL 在哪些情况下索引会失效,在实际使用的时候,要尽量避免索引失效:
- 使用左模糊查询
select id,name,age,salary from table_name where name like '%lucs';
在进行 SQL 查询时,要尽量避免左模糊查询,因为索引进行排序的话,是从左到右进行排序的,如果左边都模糊的话,就不遵守排序的规则了,自然也无法走索引
可以改为右模糊查询,在右模糊查询的情况下一般都会走索引
select id,name,age,salary from table_name where name like 'lucs%';
- 不符合最左前缀原则的查询
对于联合索引(a,b,c),来说,不能直接用 b 和 c 作为查询条件而直接跳过 a,这样就不会走索引了
如果查询条件使用 a,c,跳过了 b,那么只会用到 a 的索引
- 联合索引的第一个字段使用范围查询
比如联合索引为:(name,age,position)
select * from employees where name > 'LiLei' and age = 22 and position ='manager';
如上,联合索引的第一个字段 name 使用范围查询,那么 InnoDB 存储引擎可能认为结果集会比较大,如果走索引的话,再回表查速度太慢,所以干脆不走索引了,直接全表扫描比较快一些
可以将范围查询放在联合索引的最后一个字段
- 对索引列进行了计算或函数操作
当你在索引列上进行计算或者使用函数,MySQL 无法有效地使用索引进行查询,索引在这种情况下也会失效,如下:
select * from employees where LEFT(name,3) = 'abc';
应该尽量避免在查询条件中对索引字段使用函数或者计算。
- 使用了 or 条件
当使用 or 条件时,只要 or 前后的任何一个条件列不是索引列,那么索引就会失效
select * from emp where id = 10010 or name = 'abcd';
如上,假如 name 列不是索引列,即使 id 列上有索引,这个查询语句也不会走索引
- 索引列上有 Null 值
select * from emp where name is null;
如上,name 字段存在 null 值,索引会失效
应该尽量避免索引列的值为 null,可以在创建表的时候设置默认值或者将 null 替换为其他特殊值。
# 12、算法:接雨水
这个算法题也是比较常见的了
题目的意思是给了 n 个柱子的高度,每个柱子的宽度都为 1,问下雨之后能接到多少的雨水,如下图:

其中黑色的表示柱子,蓝色的表示接到的雨水
对于每一个柱子来说,只有两边都存在比他高的柱子,那么在这块柱子上边才可以接到雨水,具体在这块柱子上可以接到多少雨水取决于两边都比他高的柱子的最小高度
如上图,对于第 2 块柱子来说,左边第 1 块柱子比他高,右边的话第 7 块柱子比他高,所以在第2 块柱子上一定是可以接到雨水的,能接到多少雨水就取决于两边柱子较低的那一个,也就是左边的第 1 块柱子高度为 1,所以对于第 2 块柱子来说,可以接到的雨水就是 1
所以对每块柱子都计算出来左边和右边比他高的最高的柱子,再逐个计算就可以了,下边给出代码,在 LeetCode 上可以直接运行
class Solution {
public int trap(int[] h) {
int n = h.length;
int[] l_max = new int[n];
int[] r_max = new int[n];
int last = 0;
for (int i = 0; i < n; i ++) {
l_max[i] = Math.max(last, h[i]);
last = Math.max(last, h[i]);
}
last = 0;
for (int i = n-1; i >= 0; i --) {
r_max[i] = Math.max(last, h[i]);
last = Math.max(last, h[i]);
}
int res = 0;
for (int i = 0; i < n; i ++) {
int h_min = Math.min(l_max[i], r_max[i]);
if (h_min - h[i] > 0) {
res += h_min - h[i];
}
}
return res;
}
}