 01.RocketMQ核心内容
01.RocketMQ核心内容
# MQ 之间的对比
三种常用的 MQ 对比,ActiveMQ、Kafka、RocketMQ
性能方面:
- 三种 MQ 吞吐量级别为:万,百万,十万
- 消息发送时延:毫秒,毫秒,微秒
- 可用性:主从,分布式,分布式
扩展性方面:
- 水平伸缩能力:均支持
- 技术栈:Java,Java/Scala,Java
功能维度方面:
- 消息重试能力:均支持
- 消息堆积能力:跟吞吐量成正相关,三种 MQ 分别为:弱,强,强
- 消息过滤:支持,不支持,支持
- 延迟消息:均支持
- 消息回溯(用于消费者宕机恢复后,回溯到宕机前消费的位置):不支持,支持,支持
# RocketMQ 领域模型
Topic:主题,可以理解为类别、分类的概念
MessageQueue:消息队列,存储数据的一个容器(队列索引数据),默认每个 Topic 下有 4 个队列被分配出来存储消息
Message:消息,真正携带信息的载体概念
Producer:生产者,负责发送消息
Consumer:消费者,负责消费消息
ConsumerGroup:众多消费者构成的整体或构成的集群,称之为消费者组
Subscription:订阅关系,消费者得知道自己需要消费哪个 Topic 下的哪个队列的数据
Message Queue:一个 Topic 下可以设置多个消息队列,发送消息的时候,RocketMQ 会轮询该 Topic 下的所有队列将消息发送出去(下图中 Broker 中 Topic 指向的 Q1、Q2、Q3、Q4 就是 MessageQueue)
Tag:对 Topic 的进一步细化
Broker:Broker 是 Rocket MQ 的主要角色,主要管理消息的存储、发送、查询等功能
Name Server:提供轻量级的服务发现,用于存储 Topic 和 Broker 关系信息
主要功能:
- 接收 Broker 的注册,并提供心跳机制去检查 Broker 是否存活
- 路由管理,每个 nameserver 都有整个 Broker 集群的路由信息和客户端的查询队列
# Rocket MQ 单机服务启动
RocketMQ 官方下载地址:https://rocketmq.apache.org/zh/download/
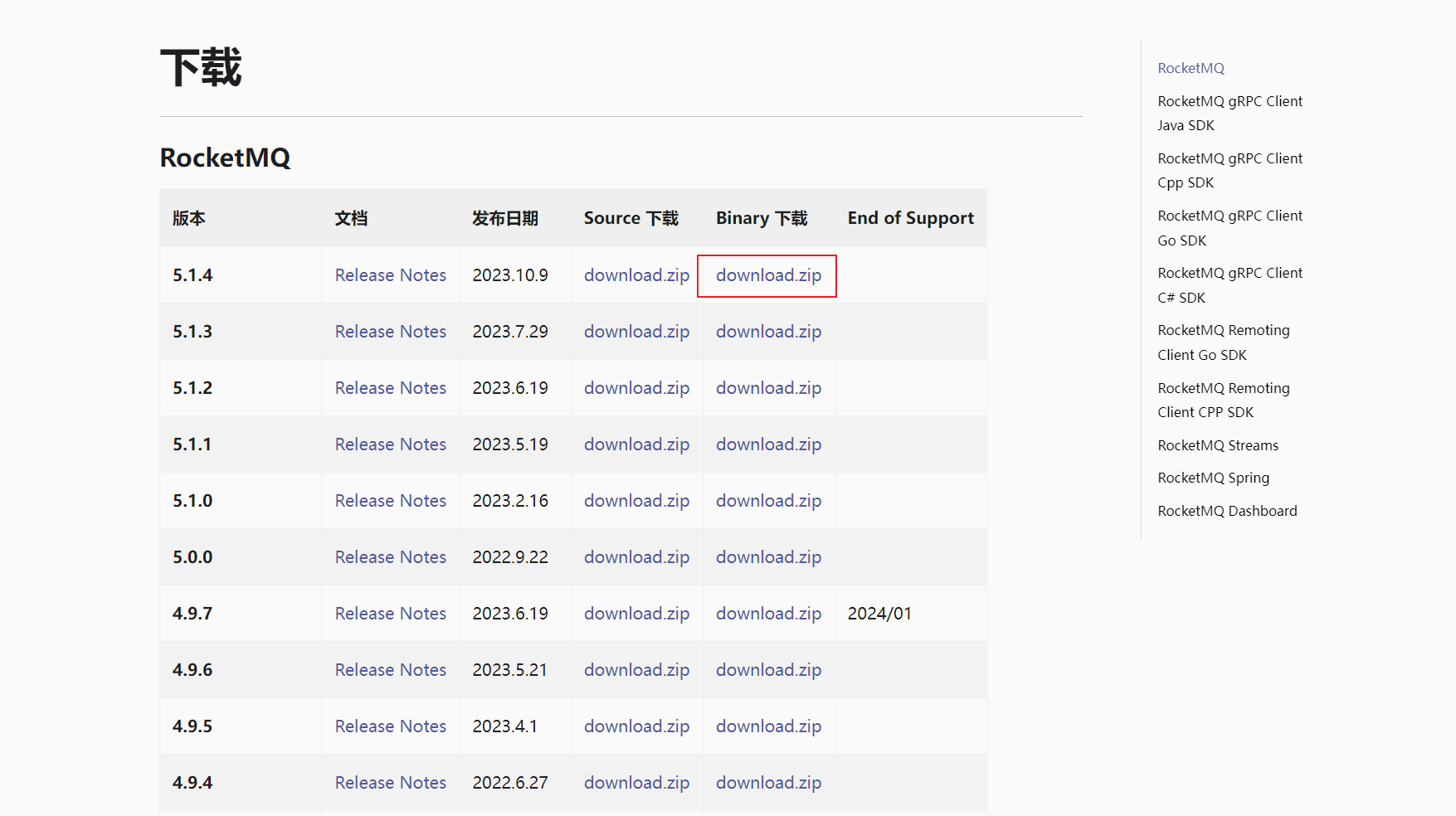
单机服务启动,选择二进制文件进行下载:
将二进制文件上传至服务器,进行解压:
# 安装 unzip 命令
yum install unzip
# 解压
unzip rocketmq-all-5.1.4-bin-release.zip
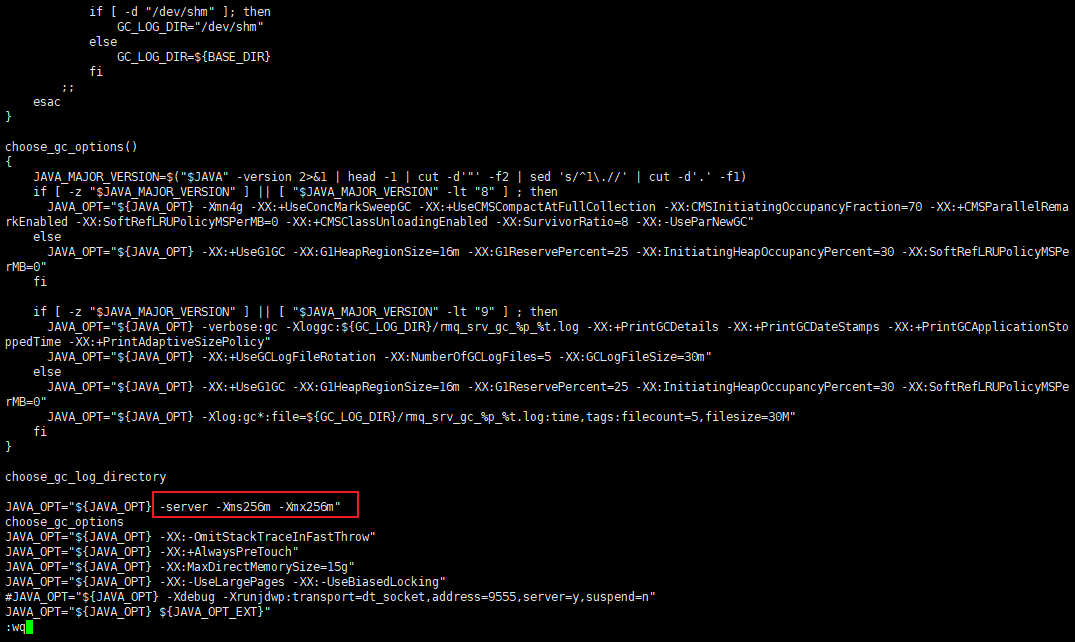
# 修改 RocketMQ 的 JVM 配置
原本分配的 JVM 堆内存太大,如果启动时分配的内存不足就会报错,需要修改 bin 目录下的:runbroker.sh 和 runserver.sh 文件:
runbroker.sh 文件修改后的内容如下图:
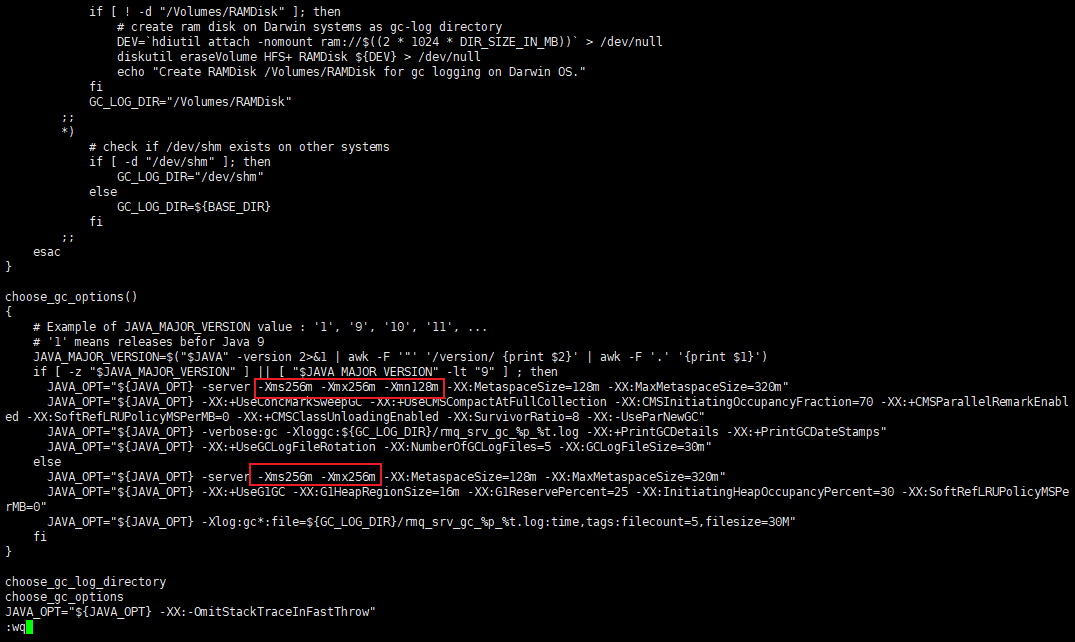
runserver.sh 文件修改后的内容如下图:
# 配置 broker.conf 文件
在 conf/broker.conf 文件中追加如下内容:
brokerIP1=【填服务器的公网 ip 地址】
namesrvAddr=localhost:9876
# linux 安装 jdk 环境
rocketmq 是 java 写的,因此还需要安装 jdk 环境,并且有 JAVA_HOME 环境变量
安装 jdk 流程如下:
# 创建目录
mkdir /usr/lib/jvm
# 解压到 /usr/lib/jvm 目录下
tar -xvf jdk-8u144-linux-x64.tar.gz -C /usr/lib/jvm
# 配置环境变量,Linux 环境变量在 /etc/profile 中配置
vi /etc/profile
# 在结尾添加如下内容
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 激活修改的配置
source /etc/profile
# 检查安装的 jdk
java -version
# 开放防火墙端口
# 开放防火墙 9876 和 10911 端口
firewall-cmd --zone=public --add-port=9876/tcp --permanent
firewall-cmd --zone=public --add-port=10911/tcp --permanent
# 更新防火墙规则
firewall-cmd --reload
# 查看防火墙所有开放的端口
firewall-cmd --list-port
# 启动
# 1.启动 nameserver, nohup 和 & 可以让程序在后台运行
nohup sh bin/mqnamesrv &
# 查看日志,判断是否启动成功
tail ‐f ~/logs/rocketmqlogs/namesrv.log
# 2.启动 broker,-n 是 nameserver 的地址
nohup sh bin/mqbroker -c conf/broker.conf ‐n localhost:9876 &
# 下边这条命令在可以指定配置文件启动
# nohup sh bin/mqbroker -c conf/custom.conf ‐n localhost:9876 & autoCreateTopicEnable=true
# 查看日志,判断是否启动成功
tail ‐f ~/logs/rocketmqlogs/broker.log
启动后,使用 jps 查看是否启动成功:

# 关闭命令
sh bin/mqshutdown broker
sh bin/mqshutdown namesrv
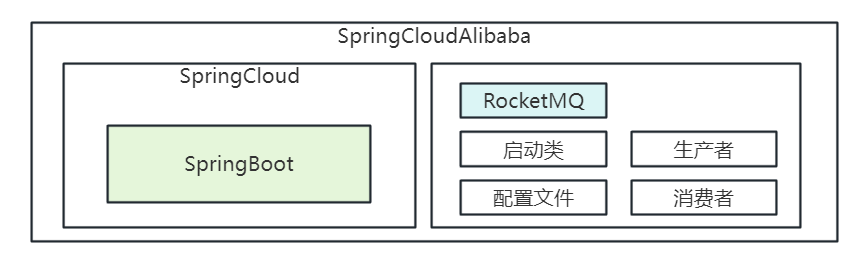
# Spring Cloud Alibaba 集成 RocketMQ 最佳实践
SpringBoot 相对于 SSM 来说已经很大程度上简化了开发,但是使用 SpringBoot 集成一些第三方的框架,还是需要花费一些力气
因此,SpringCloud 出现的宗旨就是简化 SpringBoot 集成第三方框架的过程,SpringCloud 内置集成了很多第三方插件,但是 SpringCloud 前期很重的依赖了 Netflix 组件, 但是 Netflix 组件不再维护了
因此,基于 SpringCloud 又出现了 SpringCloudAlibaba,可以灵活的进行扩展、替换插件,那么通过 SpringCloudAlibaba 集成 RocketMQ 之后,关系图如下:
SpringCloudAlibaba 集成 RocketMQ 官方文档 (opens new window)
# 集成依赖
首先,项目引入 SpringCloud、SpringCloudAlibaba 依赖和 RocketMQ 依赖,之后项目都引入该依赖即可使用 RocketMQ
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.3.12.RELEASE</version>
</parent>
<groupId>com.mq.cloud</groupId>
<artifactId>parent</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>pom</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<com.cloud.version>Hoxton.SR12</com.cloud.version>
<com.alibaba.cloud.version>2.2.8.RELEASE</com.alibaba.cloud.version>
</properties>
<dependencyManagement>
<dependencies>
<!--集成 SpringCloud-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${com.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--集成 SpringCloudAlibaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${com.alibaba.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--引入 RocketMQ 依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rocketmq</artifactId>
</dependency>
</dependencies>
</dependencyManagement>
</project>
# DashBoard
可以通过 dashboard 项目来观测 topic 消费情况,下载源码,在 application.yml 中配置 nameserver 地址启动即可
https://github.com/apache/rocketmq-dashboard
在 localhost:8080 即可访问 Dashboard
# 消息收发实战
项目结构如下:

首先新建一个项目,引入上边依赖
主启动类如下:
@SpringBootApplication
@EnableBinding({ CustomSource.class, CustomSink.class })
public class RocketMQApplication {
public static void main(String[] args) {
SpringApplication.run(RocketMQApplication.class, args);
System.out.println("【【【【【 RocketMQApplication 启动成功!!! 】】】】】");
}
// @StreamListener 声明对应的 Input Binding,这里设置两个通道来接收 topic 信息
@StreamListener("input")
public void receiveInput(String receiveMsg) {
System.out.println("input receive: " + receiveMsg);
}
@StreamListener("input2")
public void receiveInput2(String receiveMsg) {
System.out.println("input2 receive: " + receiveMsg);
}
}
消费者的 stream 默认为 input,生产者默认为 output,我们可以使用自定义的 Source 和 Sink 来扩展 stream 里的消费者配置,自定义 Source 和 Sink 如下(在主启动类通过 @EnableBinding 来绑定):
我们通过自定义 Source 和 Sink 添加了一个通道 input2、output2,那么生产者和消费者就可以收发多个 topic 了
public interface CustomSink extends Sink {
/**
* Input channel name.
*/
String INPUT2 = "input2";
/**
* @return input channel.
*/
@Input(CustomSink.INPUT2)
SubscribableChannel input2();
}
public interface CustomSource extends Source {
/**
* Name of the output channel.
*/
String OUTPUT2 = "output2";
/**
* @return output channel
*/
@Output(CustomSource.OUTPUT2)
MessageChannel output2();
}
application.properties 如下:
spring.application.name=mq_rmqdemo
server.port=9500
# configure the nameserver of rocketmq
spring.cloud.stream.rocketmq.binder.name-server=127.0.0.1:9876
spring.cloud.stream.rocketmq.binder.group=mq_rmqdemo
# configure the output binding named output
# 第一个通道的 topic
spring.cloud.stream.bindings.output.destination=test-topic
spring.cloud.stream.bindings.output.content-type=application/json
# configure the input binding named input
spring.cloud.stream.bindings.input.destination=test-topic
spring.cloud.stream.bindings.input.content-type=application/json
spring.cloud.stream.bindings.input.group=test-group
# configure the output2 binding named output
# 第二个通道的 topic
spring.cloud.stream.bindings.output2.destination=test-topic2
spring.cloud.stream.bindings.output2.content-type=application/json
# configure the input binding named input
spring.cloud.stream.bindings.input2.destination=test-topic2
spring.cloud.stream.bindings.input2.content-type=application/json
spring.cloud.stream.bindings.input2.group=test-group2
接下来写生产者发送两个 topic,在消费者即可看到消息被成功接收:
// 生产者
public class Producer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("producer_group");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
for (int i = 0; i < 3; i++) {
Message msg = new Message(
"test-topic",
"tagStr",
("( " + i + " )message from mq_rmqdemo producer:【test-topic1】").getBytes());
producer.send(msg);
Message msg2 = new Message(
"test-topic2",
"tagStr",
("( " + i + " )message from mq_rmqdemo producer:【test-topic2】").getBytes());
producer.send(msg);
producer.send(msg2);
}
System.out.println("Send Finished.");
}
}
# 顺序消费实战
顺序消费分为两种:
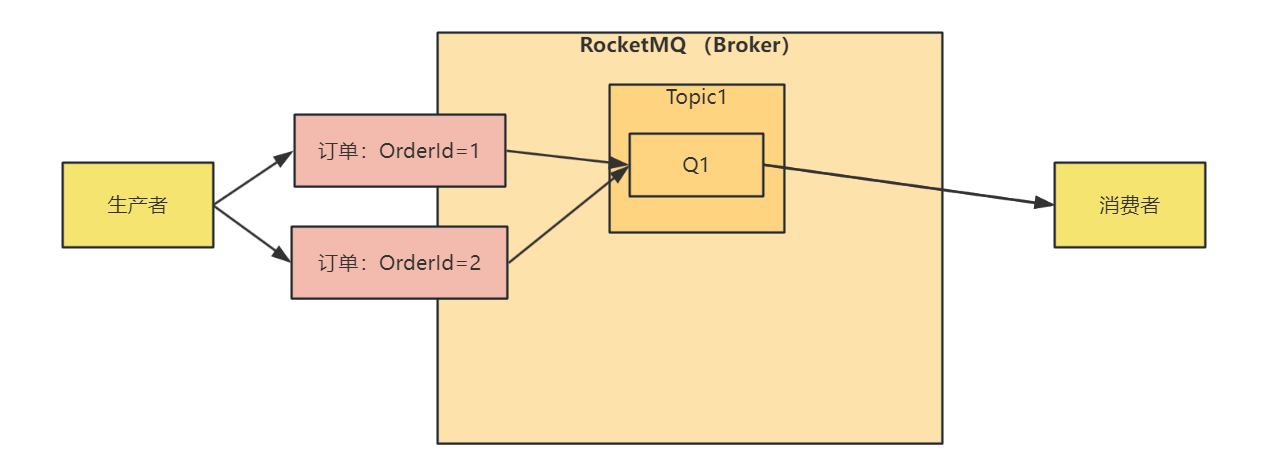
全局有序:适用于并发度不大,并且对消息要求严格一致性的场景下
通过创建一个 topic,并且该 topic 下只有一个队列,那么生产者向着一个队列中发消息,消费者也在这一个队列中消费消息,来保证消息的有序性
局部有序:适用于对性能要求比较高的场景,在设计层面将需要保证有序的消息放在 Topic 下的同一个队列即可保证有序
# 全局有序
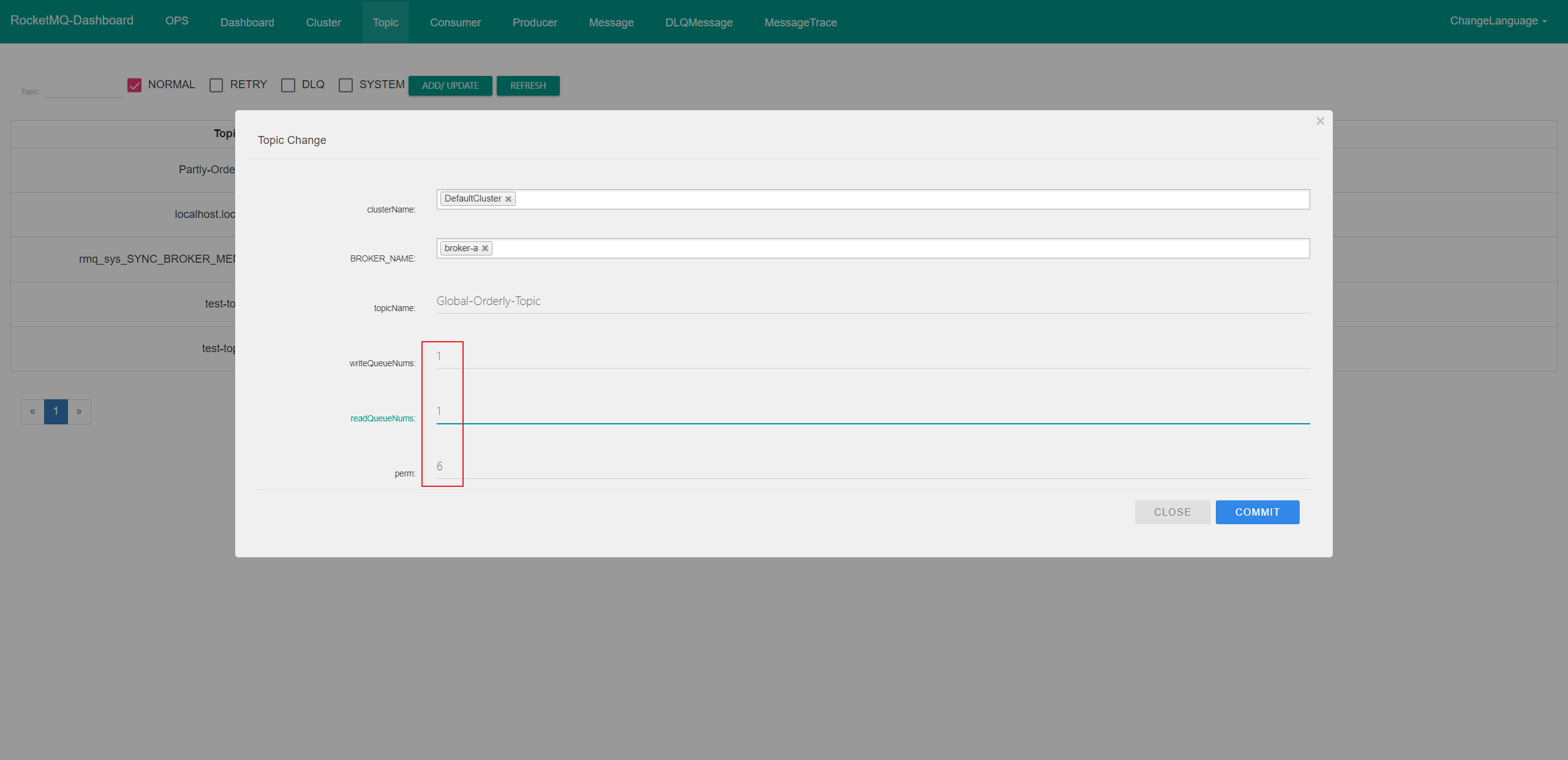
要保证全局有序的话,我们先通过上边启动的 Dashboard 项目,创建一个只有一个队列的 Topic
将 写队列和读队列 都设置为 1 个,perm 设置为6(perm,2:只写; 4-只读; 6-读写;)
全局有序流程图如下:
首先消费者主启动类如下:
@SpringBootApplication
@EnableBinding({CustomSink.class })
public class OrderlyConsumerApplication {
@Value("${server.port}")
private int port;
public static void main(String[] args) {
SpringApplication.run(OrderlyConsumerApplication.class, args);
System.out.println("【【【【【 OrderlyConsumerApplication 启动成功!!! 】】】】】");
}
// 定义两个通道,input 接收全局有序消息,input2 接收局部有序消息
@StreamListener("input")
public void receiveInput(String receiveMsg) {
System.out.println(port + " port, input receive: " + receiveMsg);
}
@StreamListener("input2")
public void receiveInput2(String receiveMsg) {
System.out.println(port + " port, input2 receive: " + receiveMsg);
}
}
自定义 CustomSink 如下:
public interface CustomSink extends Sink {
/**
* Input channel name.
*/
String INPUT2 = "input2";
/**
* @return input channel.
*/
@Input(CustomSink.INPUT2)
SubscribableChannel input2();
}
配置类 application.properties 如下:
spring.application.name=mq_orderly_consumer
server.port=9530
# configure the nameserver of rocketmq
spring.cloud.stream.rocketmq.binder.name-server=127.0.0.1:9876
spring.cloud.stream.rocketmq.binder.group=mq_producer_group
# configure the input binding named input
spring.cloud.stream.bindings.input.destination=Global-Orderly-Topic
spring.cloud.stream.bindings.input.content-type=application/json
spring.cloud.stream.bindings.input.group=Global-Orderly-Topic-group
spring.cloud.stream.rocketmq.bindings.input.consumer.orderly=true
# configure the input binding named input
spring.cloud.stream.bindings.input2.destination=Partly-Orderly-Topic
spring.cloud.stream.bindings.input2.content-type=application/json
spring.cloud.stream.bindings.input2.group=Partly-Orderly-Topic-group
spring.cloud.stream.rocketmq.bindings.input2.consumer.orderly=true
全局有序生产者代码如下:
public class GlobalProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer(
"producer_group",
true);
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
for (int i = 0; i < 12; i++) {
Message msg = new Message(
"Global-Orderly-Topic",
"Global_Orderly_Tag",
("( " + i + " )message from GlobalProducer").getBytes());
msg.setKeys("Global_Orderly_Tag");
producer.send(msg);
}
System.out.println("Send Finished.");
}
}
先启动消费者,再启动生产者,即可看到在消费者端,消息被有序消费
# 局部有序
局部有序的话,我们将需要保证有序的消息放在同一个 Topic 下的队列即可保证有序,这里设计的让 OrderId 相同的消息放在同一个队列中发送,流程图如下:
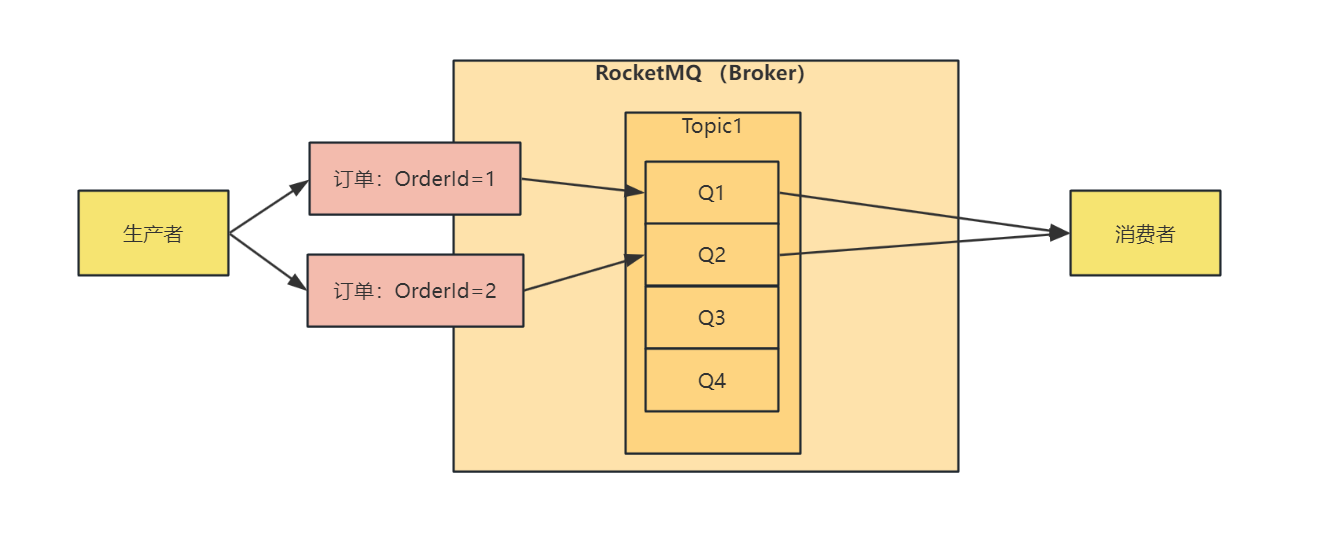
在局部有序中,消费者依然使用全局有序中的消费者,局部生产者代码如下:
public class PartlyProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer(
"producer_group",
true);
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
/**
* orderId = 1 的消息,需要按照 step 的顺序进行消费
* orderId = 2 的消息,需要按照 step 的顺序进行消费
*/
List<Order> list = new ArrayList<>();
for (int i = 1; i <= 3; i ++) {
Order order = new Order();
order.orderId = 1;
order.step = i;
list.add(order);
}
for (int i = 5; i <= 8; i ++) {
Order order = new Order();
order.orderId = 2;
order.step = i;
list.add(order);
}
System.out.println(list);
int size = list.size();
for (int i = 0; i < size; i++) {
Order order = list.get(i);
Message msg = new Message(
"Partly-Orderly-Topic",
"Partly_Orderly_Tag",
(order.toString()).getBytes());
msg.setKeys("Partly_Orderly_Tag");
/**
* 这里发送消息的时候,根据 orderId 来选择对应发送的队列
*/
producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
int orderId = (int)arg;
int idx = orderId % mqs.size();
return mqs.get(idx);
}
}, order.orderId);
}
System.out.println("Send Finished.");
}
public static class Order {
int orderId;
int step;
@Override
public String toString() {
return "Order{" +
"orderId=" + orderId +
", step=" + step +
'}';
}
}
}
# 消息追踪
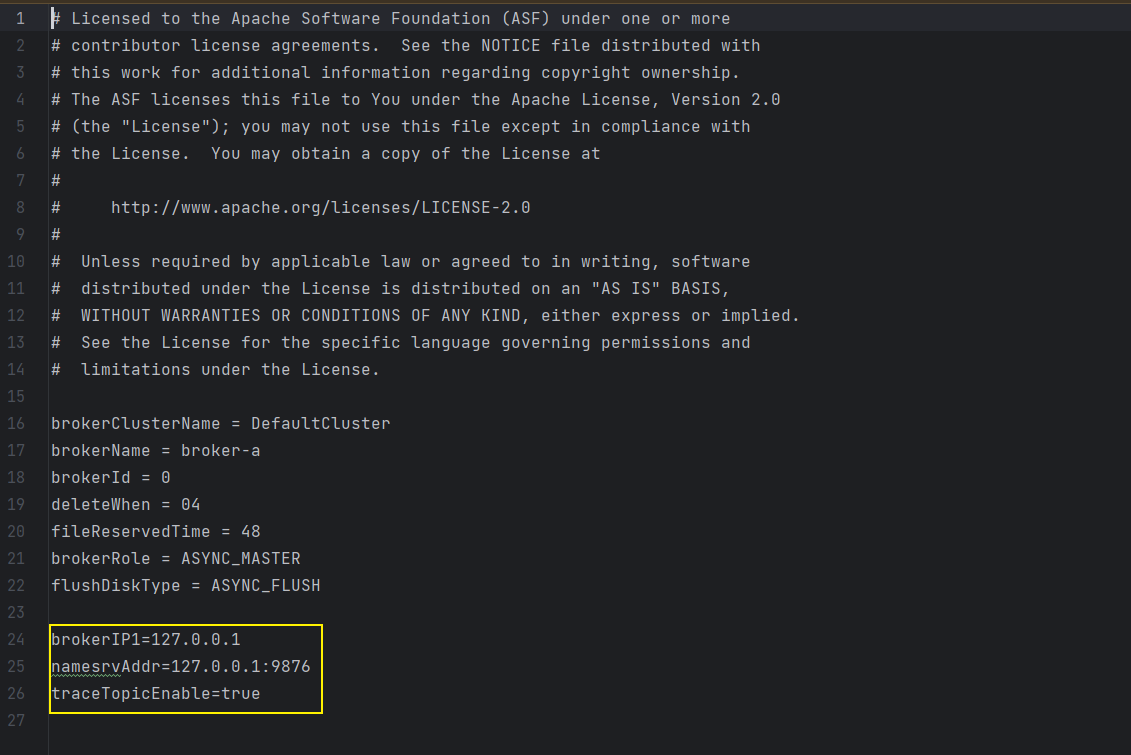
设置消息追踪需要修改 broker 启动的配置文件,添加一行配置:traceTopicEnable=true 即可,操作如下:
# 进入到 rocketmq 的安装目录中
# 先复制一份配置文件
cp broker.conf custom.conf
# 在自定义配置文件中添加一行配置
vi custom.conf
## 添加配置
traceTopicEnable=true
# 杀死原来的 broker 进程,再重新启动即可
# 先查看原来 broker 进程 id
jps
# 杀死 broker
kill -9 [进程id]
# 重新启动 broker,并指定配置文件
nohup sh bin/mqbroker -c conf/custom.conf ‐n localhost:9876 & autoCreateTopicEnable=true
在发送消息的时候,指定消息的 keys 就可以在 DashBoard 中观看到消息的追踪记录了
public class GlobalProducer {
public static void main(String[] args) throws Exception {
// true 即设置允许消息追踪
DefaultMQProducer producer = new DefaultMQProducer(
"producer_group",
true);
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
for (int i = 0; i < 12; i++) {
Message msg = new Message(
"Global-Orderly-Topic",
"Global_Orderly_Tag",
("( " + i + " )message from GlobalProducer").getBytes());
// 设置消息的 keys
msg.setKeys("Global_Orderly_Tag");
producer.send(msg);
}
System.out.println("Send Finished.");
}
}
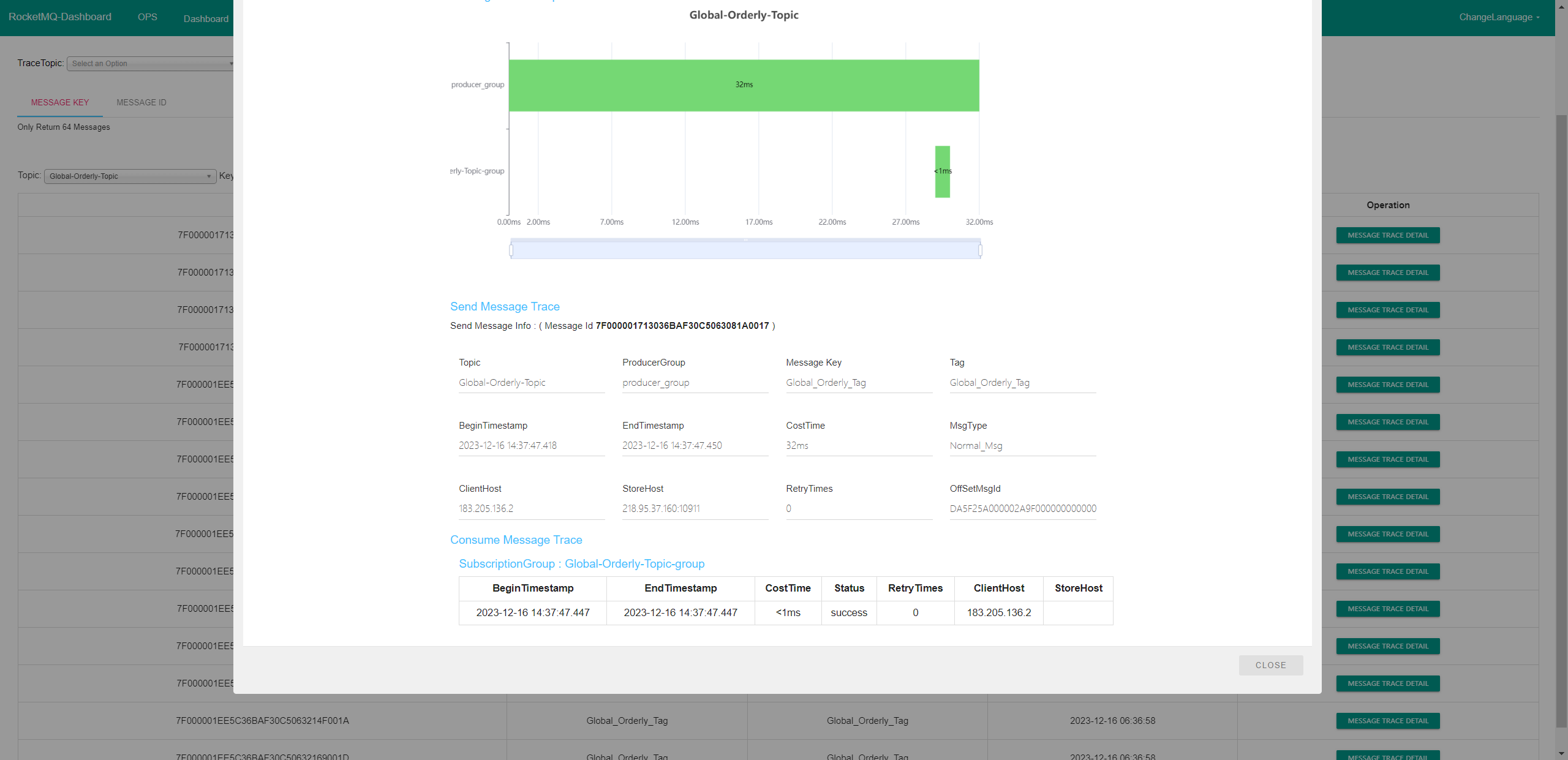
之后就可以在 DashBoard 中查看消息的追踪记录了:

点击进去,查看消息追踪详细信息如下:
# 延时消息实战
上边的案例使用了 SpringCloudStream 的 API 进行消息的收发,这里使用原生 API 进行消息收发实战,通过设置消息的延时时间,可以让消息等待指定时间之后再发送
5.x 之前,只能设置固定时间的延时消息
5.x 之后,可以自定义任意时间的延时消息
由于这里引入的 SpringCloudAlibaba 整合的 RocketMQ 是 4.9.4 版本的,因此只能设置固定时间的延时消息
延时时间有以下几种,通过 Leven 进行定位,如果 delayTimeLevel = 2,就是第二个延时时间 5s
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
消费者代码如下:
public class Consumer {
public static void main(String[] args) throws Exception {
// 1、创建消费者对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("delay_group");
// 2、为消费者对象设置 NameServer 地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 3、订阅主题
consumer.subscribe("custom-delay-topic", "*");
// 4、注册监听消息,并打印消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
String printMsg = new String(msg.getBody()) + ", recvTime: "
+ new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date());
System.out.println(printMsg);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 5、把消费者直接启动起来
consumer.start();
}
}
生产者代码如下:
public class Producer {
public static void main(String[] args) throws Exception {
// 1、创建生产者对象
DefaultMQProducer producer = new DefaultMQProducer("producer_group");
// 2、为生产者对象设置 NameServer 地址
producer.setNamesrvAddr("127.0.0.1:9876");
// 3、把我们的生产者直接启动起来
producer.start();
// 4、创建消息、并发送消息
for (int i = 0; i < 3; i++) {
// public Message(String topic, String tags, String keys, byte[] body) {
Message message = new Message(
"custom-delay-topic",
"delayTag",
"CUSTOM_DELAY",
("("+i+")Hello Message From Delay Producer, " +
"date="+new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date())).getBytes()
);
// 设置定时的逻辑
// "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
message.setDelayTimeLevel(2);
// 利用生产者对象,将消息直接发送出去
producer.send(message);
}
System.out.println("Send Finished.");
}
}
# 批量发送消息
批量发送消息可以减少网络的 IO 开销,让多个消息通过 1 次网络开销就可以发送,提升数据发送的吞吐量

虽然批量发送消息可以减少网络 IO 开销,但是一次也不能发送太多消息
批量消息直接将多个消息放入集合中发送即可,生产者代码如下:
public class Producer {
public static void main(String[] args) throws Exception {
// 1、创建生产者对象
DefaultMQProducer producer = new DefaultMQProducer("producer_group");
// 2、为生产者对象设置 NameServer 地址
producer.setNamesrvAddr("127.0.0.1:9876");
// 3、把我们的生产者直接启动起来
producer.start();
// 4、创建消息、并发送消息
List<Message> reqList = new ArrayList<>(12);
for (int i = 0; i < 12; i++) {
// public Message(String topic, String tags, String keys, byte[] body) {
Message message = new Message(
"custom-batch-topic",
"batchTag",
"CUSTOM_BATCH",
("("+i+")Hello Message From BATCH Producer, " +
"date="+new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date())).getBytes()
);
reqList.add(message);
}
// 利用生产者对象,将消息直接批量发送出去
producer.send(reqList);
System.out.println("Send Finished.");
}
}
消费者代码如下:
public class Consumer {
public static void main(String[] args) throws Exception {
// 1、创建消费者对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("batch_group");
// 2、为消费者对象设置 NameServer 地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 3、订阅主题
consumer.subscribe("custom-batch-topic", "*");
// 4、注册监听消息,并打印消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
String printMsg = new String(msg.getBody()) + ", recvTime: "
+ new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date());
System.out.println(printMsg);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 5、把消费者直接启动起来
consumer.start();
System.out.println("Consumer Started Finished.");
}
}
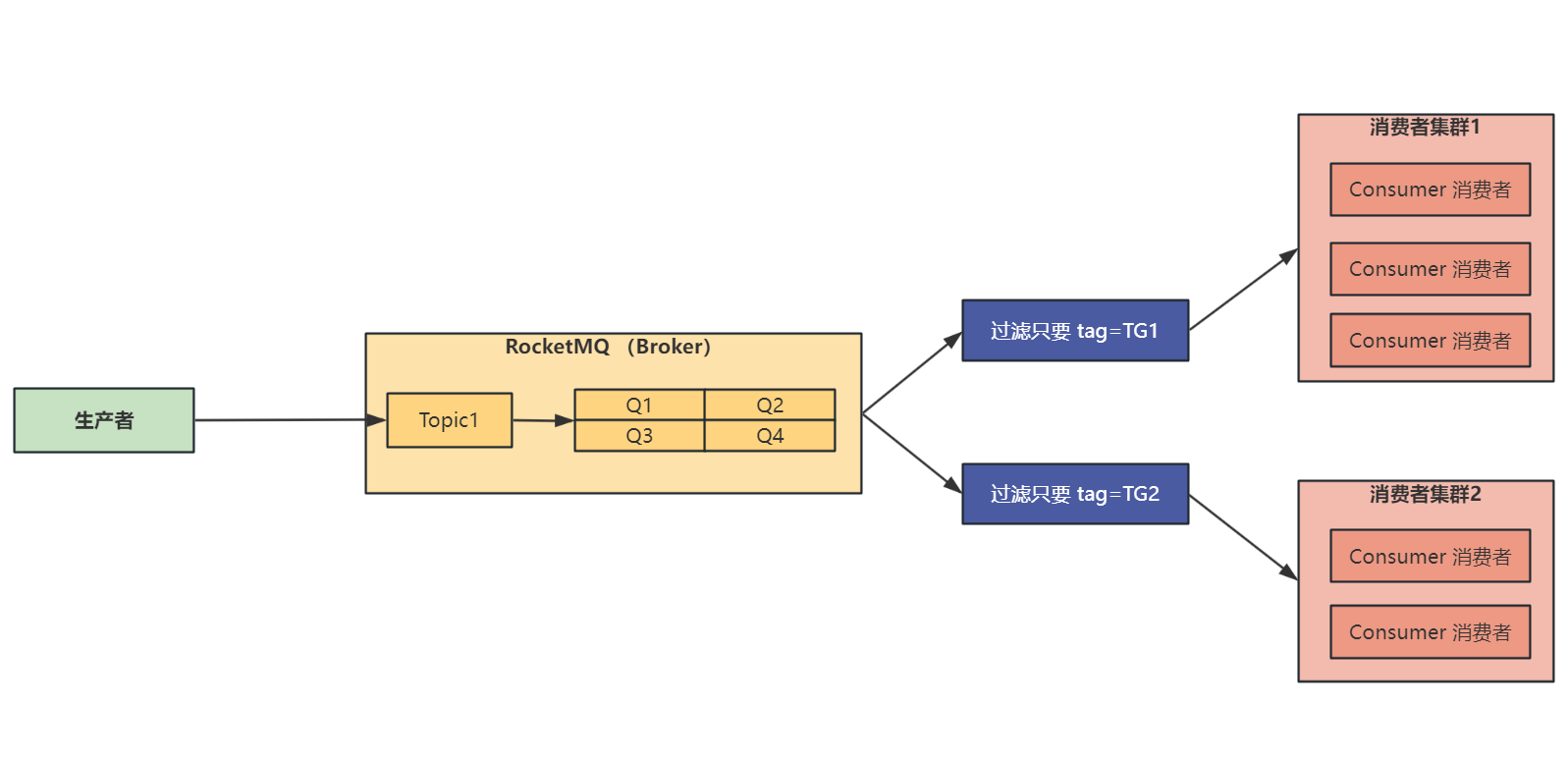
# 消息过滤
消费者组中还可以有过滤操作,对同一个 Topic 下的消息的 Tag 标签进行过滤
但是使用消息过滤时需要 保证同一个消费组中消费的消息的 Tag 相同 ,如果同一个消费者组中的两个消费者订阅了不同的 Tag,比如消费者 A 订阅了 Tag1,消费者 B 订阅了 Tag2,那么可能 B 收到了 Tag1 的数据,发现不是自己想要的,于是将 Tag1 的数据过滤掉了,那么就导致了 A 也收不到 Tag1 的数据,造成数据消失的现象
消息过滤流程图如下:
消息过滤生产者如下:
public class FilterProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer(
"producer_group",
true);
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
List<Order> list = new ArrayList<>();
for (int i = 0; i < 12; i ++) {
Order order = new Order();
order.orderId = i;
order.desc = "desc:" + i;
order.tag = "tag" + i % 3;
list.add(order);
}
for (Order order : list) {
Message msg = new Message(
"Filter-Test-Topic",
order.tag,
(order.toString()).getBytes());
msg.setKeys("Filter_Tag");
msg.putUserProperty("idx", new DecimalFormat("00").format(order.orderId));
// 直接将 msg 发送出去
producer.send(msg);
}
System.out.println("Send Finished.");
}
public static class Order {
int orderId;
String desc;
String tag;
@Override
public String toString() {
return "orderId="+orderId+", desc="+desc+", tag="+tag;
}
}
}
过滤 tag 的几种用法:
过滤消息的 tag 主要修改一行代码:
consumer.subscribe("Filter-Test-Topic", "tag1");,过滤也分几种情况:
过滤所有 tag
consumer.subscribe("Filter-Test-Topic", "*");过滤单个 tag
consumer.subscribe("Filter-Test-Topic", "tag1");过滤多个 tag
consumer.subscribe("Filter-Test-Topic", "TG2 || TG3");订阅 SQL92 方式(需要修改 custom.conf 文件,添加一行配置:enablePropertyFilter=true)
consumer.subscribe("Filter-Test-Topic", MessageSelector.bySql("idx > 10"));这里的 idx > 10 的 idx 是在生产者中通过下边这行代码放入的:
msg.putUserProperty("idx", new DecimalFormat("00").format(order.orderId));
消息过滤消费者代码如下(只过滤出 tag = tag1 的消息):
public class Subscribe02_Single_Consumer {
public static void main(String[] args) throws Exception {
// 1、创建消费者对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("Subscribe02_Single_Consumer");
// 2、为消费者对象设置 NameServer 地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 3、订阅主题
consumer.subscribe("Filter-Test-Topic", "tag1");
// 4、注册监听消息,并打印消息
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
for (MessageExt msg : msgs) {
String printMsg = new String(msg.getBody()) + ", recvTime: "
+ new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date());
System.out.println(printMsg);
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
// 5、把消费者直接启动起来
consumer.start();
System.out.println("Consumer Started Finished.");
}
}
# 事务消息收发
流程如下:
- 发送给 MQ 一条任务操作
- MQ 的 Broker 成功收到后,那么发送方就开始执行原子 db 业务
- 如果执行原子 db 业务失败,并没有将执行成功状态同步给 Broker
- 那么 Broker 会去检查 db 事务是否成功,最后要么事务提交,可以被生产者消费,要么事务回滚,生产者无法消费
事务消息收发流程图如下:

事务消息收发消费者如下:
public class TransactionConsumer {
public static void main(String[] args) throws Exception {
// 1、创建消费者对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("TransactionConsumer");
// 2、为消费者对象设置 NameServer 地址
consumer.setNamesrvAddr("127.0.0.1:9876");
// 3、订阅主题
consumer.subscribe("Transaction-Test-Topic", "*");
// 4、注册监听消息,并打印消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
for (MessageExt msg : list) {
String printMsg = new String(msg.getBody()) + ", recvTime: "
+ new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS").format(new Date());
System.out.println(printMsg);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 5、把消费者直接启动起来
consumer.start();
System.out.println("Consumer Started Finished.");
}
}
这里模拟事务成功执行的生产者,执行该生产者之后,消费者可以收到消息并消费:
public class TransactionProducer {
public static void main(String[] args) throws Exception {
TransactionMQProducer producer = new TransactionMQProducer(
"transaction_producer_group");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
/**
* 这里执行本地事务,如果本地事务执行成功,就返回成功
* 如果本地事务失败,就返回失败
*/
return LocalTransactionState.COMMIT_MESSAGE;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 触发事务的检查,提供给到生产者一个检查事务是否成功提交的机会
return LocalTransactionState.COMMIT_MESSAGE;
}
});
producer.start();
List<Order> list = new ArrayList<>();
for (int i = 0; i < 12; i ++) {
Order order = new Order();
order.orderId = i;
order.desc = "desc:" + i;
order.tag = "tag" + i % 3;
list.add(order);
}
for (Order order : list) {
Message msg = new Message(
"Transaction-Test-Topic",
order.tag,
(order.toString()).getBytes());
msg.setKeys("Transaction_Tag");
msg.putUserProperty("idx", new DecimalFormat("00").format(order.orderId));
// 直接将 msg 发送出去
producer.sendMessageInTransaction(msg, null);
}
System.out.println("Send Finished.");
}
public static class Order {
int orderId;
String desc;
String tag;
@Override
public String toString() {
return "orderId="+orderId+", desc="+desc+", tag="+tag;
}
}
}
这里模拟事务执行失败的生产者,执行该生产者之后,消费者不会收到消息:
public class TransactionProducerFail {
public static void main(String[] args) throws Exception {
TransactionMQProducer producer = new TransactionMQProducer(
"transaction_producer_group_fail");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
/**
* 这里执行本地事务,如果本地事务执行成功,就返回成功
* 如果本地事务失败,就返回失败
*/
return LocalTransactionState.UNKNOW;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 触发事务的检查,提供给到生产者一个检查事务是否成功提交的机会
return LocalTransactionState.ROLLBACK_MESSAGE;
}
});
producer.start();
List<TransactionProducer.Order> list = new ArrayList<>();
for (int i = 0; i < 12; i ++) {
TransactionProducer.Order order = new TransactionProducer.Order();
order.orderId = i;
order.desc = "desc:" + i;
order.tag = "tag" + i % 3;
list.add(order);
}
for (TransactionProducer.Order order : list) {
Message msg = new Message(
"Transaction-Test-Topic",
order.tag,
(order.toString()).getBytes());
msg.setKeys("Transaction_Tag");
msg.putUserProperty("idx", new DecimalFormat("00").format(order.orderId));
// 直接将 msg 发送出去
producer.sendMessageInTransaction(msg, null);
}
System.out.println("Send Finished.");
}
public static class Order {
int orderId;
String desc;
String tag;
@Override
public String toString() {
return "orderId="+orderId+", desc="+desc+", tag="+tag;
}
}
}
# 最大重试消费
重试分为两种:生产者重试、消费者重试
生产者重试设置:
生产者配置重试次数
// 同步 producer.setRetryTimesWhenSendFailed(3) // 异步 producer.setRetryTimesWhenSendAsyncFailed(3); // 如果发送失败,是否尝试发送到其他 Broker 节点 producer.setRetryAnotherBrokerWhenNotStoreOK(true);生产者设置重试的策略
producer.addRetryResponseCode(ResponseCode.FLUSH_DISK_TIMEOUT);
消费者重试设置:
- 消费者有序消费时,如果消费失败,返回
ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT即可 - 消费者并发消费时,如果消费失败,返回
ConsumeConcurrentlyStatus.RECONSUME_LATER即可
生产者代码如下(消费者代码就不贴了,只需要消费时返回需要重试的状态码即可):
public class RetryProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer(
"producer_group",
true);
producer.setNamesrvAddr("127.0.0.1:9876");
// 设置一些重试的策略
producer.addRetryResponseCode(ResponseCode.FLUSH_DISK_TIMEOUT);
// 设置发送失败最大重试次数
producer.setRetryTimesWhenSendFailed(3);
producer.setRetryTimesWhenSendAsyncFailed(3);
producer.start();
List<Order> list = new ArrayList<>();
for (int i = 0; i < 12; i ++) {
Order order = new Order();
order.orderId = i;
order.desc = "desc:" + i;
order.tag = "tag" + i % 3;
list.add(order);
}
for (Order order : list) {
Message msg = new Message(
"Filter-Test-Topic",
order.tag,
(order.toString()).getBytes());
msg.setKeys("Filter_Tag");
msg.putUserProperty("idx", new DecimalFormat("00").format(order.orderId));
// 直接将 msg 发送出去
producer.send(msg);
}
System.out.println("Send Finished.");
}
public static class Order {
int orderId;
String desc;
String tag;
@Override
public String toString() {
return "orderId="+orderId+", desc="+desc+", tag="+tag;
}
}
}
# RocketMQ 原理分析
# 启动 RocketMQ 源码
分析 RocketMQ 之前,先确保可以成功启动起来
# NameServer 启动
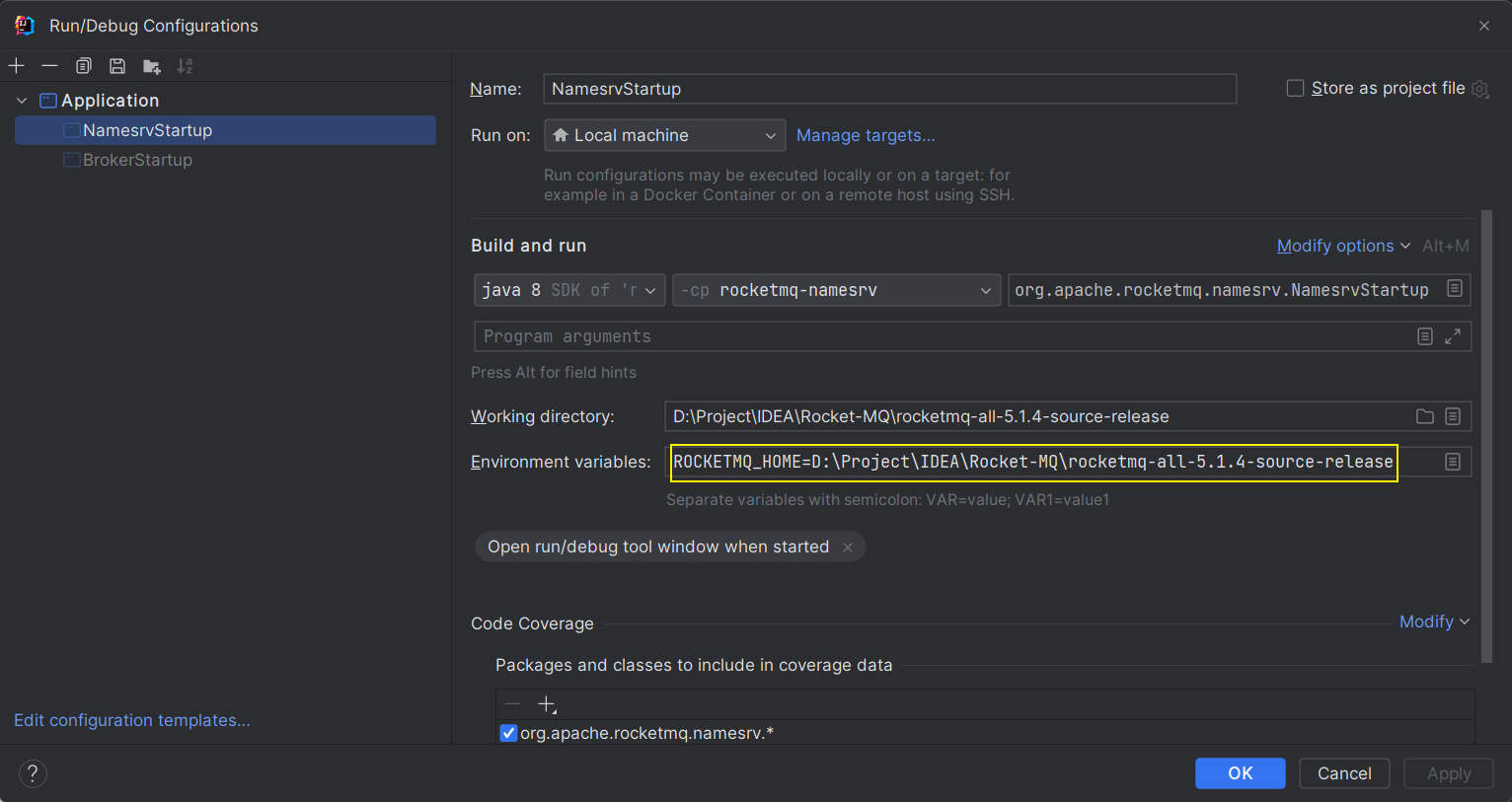
在 Idea 中配置 ROCKETMQ_HOME 环境变量为自己安装 RocketMQ 的位置即可
ROCKETMQ_HOME=D:\Project\IDEA\Rocket-MQ\rocketmq-all-5.1.4-source-release
# Broker 启动
启动 Broker 指定 NameServer 地址以及配置文件地址,以及 ROCKETMQ_HOME 变量即可
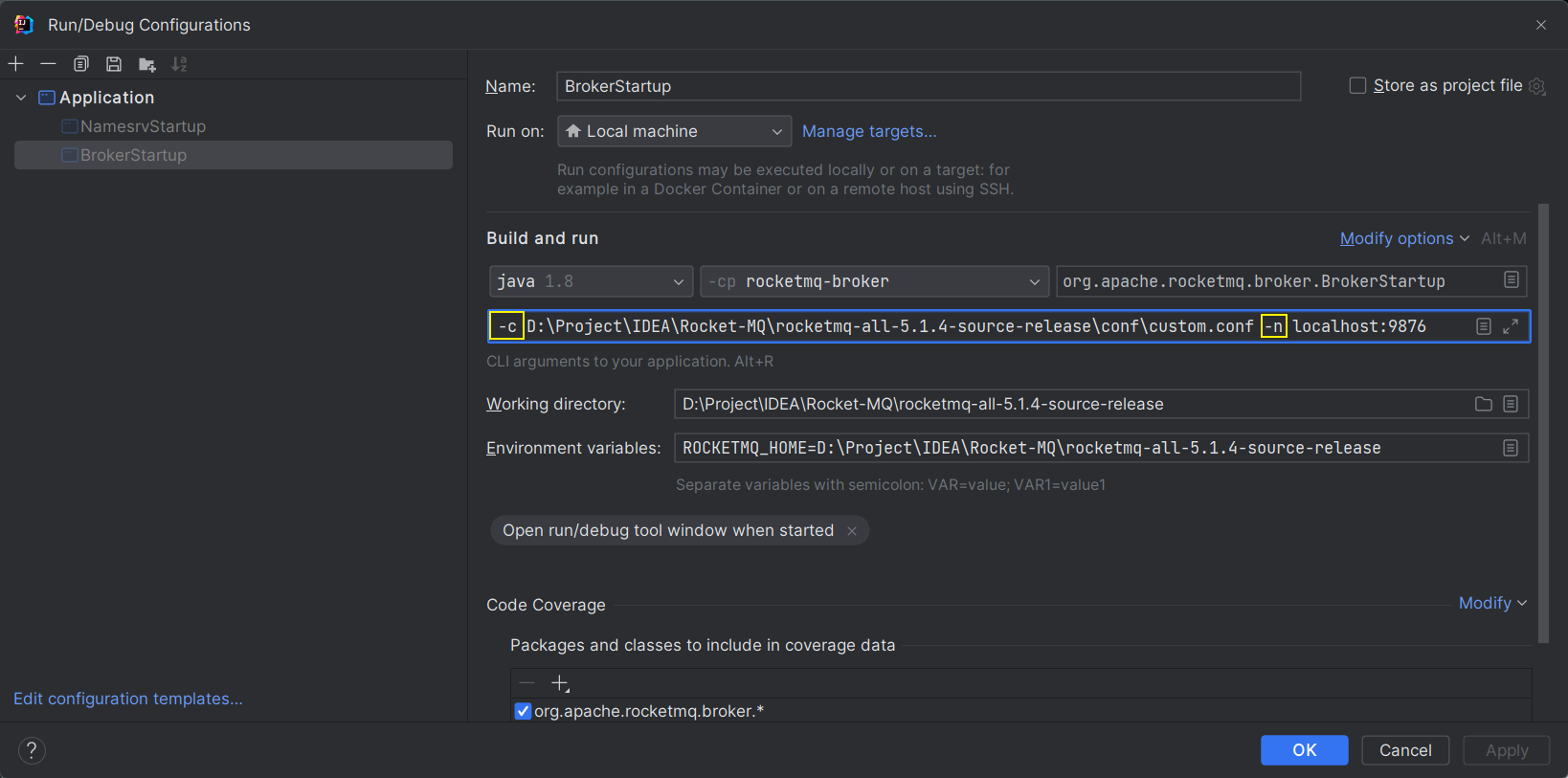
上边的 custom.conf 配置文件就是 broker.conf 多加了 3 行配置,如下:
# Broker 启动流程分析
既然需要分析 Broker 启动流程,先下载 RocketMQ 源码
https://rocketmq.apache.org/download
Broker 启动的入口为 broker 模块的 BrokerStartup 启动类:

Broker 启动有两个方法:
createBrokerController(args):先创建 BrokerController 控制器,BrokerController 控制器对象包含了各种 Config 配置对象以及 Manager 管理对象在该方法中,主要通过
buildBrokerController()方法来创建 BrokerController 控制器创建
四大配置类:- BrokerConfig:Broker 服务自己本身的配置
- NettyServerConfig:Broker 作为服务端,开启端口接收消息的 Netty 服务端配置
- NettyClientConfig:Broker 作为客户端,连接 NameServer 的 Netty 客户端配置
- MessageStoreConfig:消息存储相关的配置
解析
命令行参数:/** * 这里解析命令行或 Idea Arguments 的参数 * 如果自己开发插件需要接收命令启动参数的话,可以参考 * Broker 启动命令为:./mqbroker -n localhost:9876 -c D:/RocketMQ/conf/custom.conf autoCreateTopicEnable=true */ Options options = ServerUtil.buildCommandlineOptions(new Options()); CommandLine commandLine = ServerUtil.parseCmdLine("mqbroker", args, buildCommandlineOptions(options), new DefaultParser());将四大配置类装入 BrokerController:
/** * 将 4 大配置,装进 BrokerController 中 * 在 BrokerController 构造方法还创建了: * 1. 各种 Manager 管理对象 * 2. 各种 Processor 处理对象 * 3. 各种 Queue 队列对象 */ final BrokerController controller = new BrokerController(brokerConfig, nettyServerConfig, nettyClientConfig, messageStoreConfig);
创建完 BrokerController 控制器之后,还会判断是否创建成功,以及注册钩子
判断是否创建成功,如果创建失败,就尝试关闭
BrokerControllerboolean initResult = controller.initialize(); if (!initResult) { controller.shutdown(); System.exit(-3); }注册 JVM 进程关闭的钩子,在进程关闭时,回收一些资源
// 添加 JVM 钩子,在 JVM 关闭时,会触发钩子,做一些回收动作 Runtime.getRuntime().addShutdownHook(new Thread(buildShutdownHook(controller)));
start(brokerController):创建完 BrokerController 后,启动 BrokerController在该方法中,通过
controller.start();来启动 BrokerController调用 NameServer 的通信组件启动
// 调用 NameServer 的通信组件启动 if (this.brokerOuterAPI != null) { this.brokerOuterAPI.start(); }向所有的 NameServer 注册 Broker 自己
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());发送心跳
if (this.brokerConfig.isEnableControllerMode()) { scheduleSendHeartbeat(); }
# NameServer 路由注册机制
在 Broker 启动时,通过 BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister()); 向 NameServer 中注册自己
那么 NameServer 中,注册 Broker 信息的入口在: DefaultRequestProcessor # processRequest
判断请求码,如果是 Broker 注册,则进行注册 Broker 信息
@Override public RemotingCommand processRequest(ChannelHandlerContext ctx, RemotingCommand request) throws RemotingCommandException { if (ctx != null) { log.debug("receive request, {} {} {}", request.getCode(), RemotingHelper.parseChannelRemoteAddr(ctx.channel()), request); } switch (request.getCode()) { // ... 省略 // 如果是 Broker 注册 case RequestCode.REGISTER_BROKER: return this.registerBroker(ctx, request); // ... 省略 } }this.registerBroker真正开始注册 Broker 信息在注册信息之前,会先使用
crc32来检验消息的正确性(安全检查)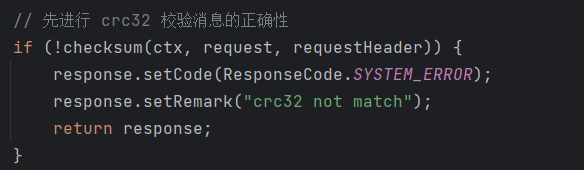
之后会调用
this.namesrvController.getRouteInfoManager().registerBroker()来注册 Broker 的信息,这个 Broker 的信息是 BrokerController 启动时通过 Netty 发送过来的通过
getRouteInfoManager获取 RouteInfoManager,在该类中注册 Broker 信息,那么 RouteInfoManager 肯定是管理了 Broker 的信息可以点进去 RouteInfoManager,可以发现其中管理了很多路由的信息
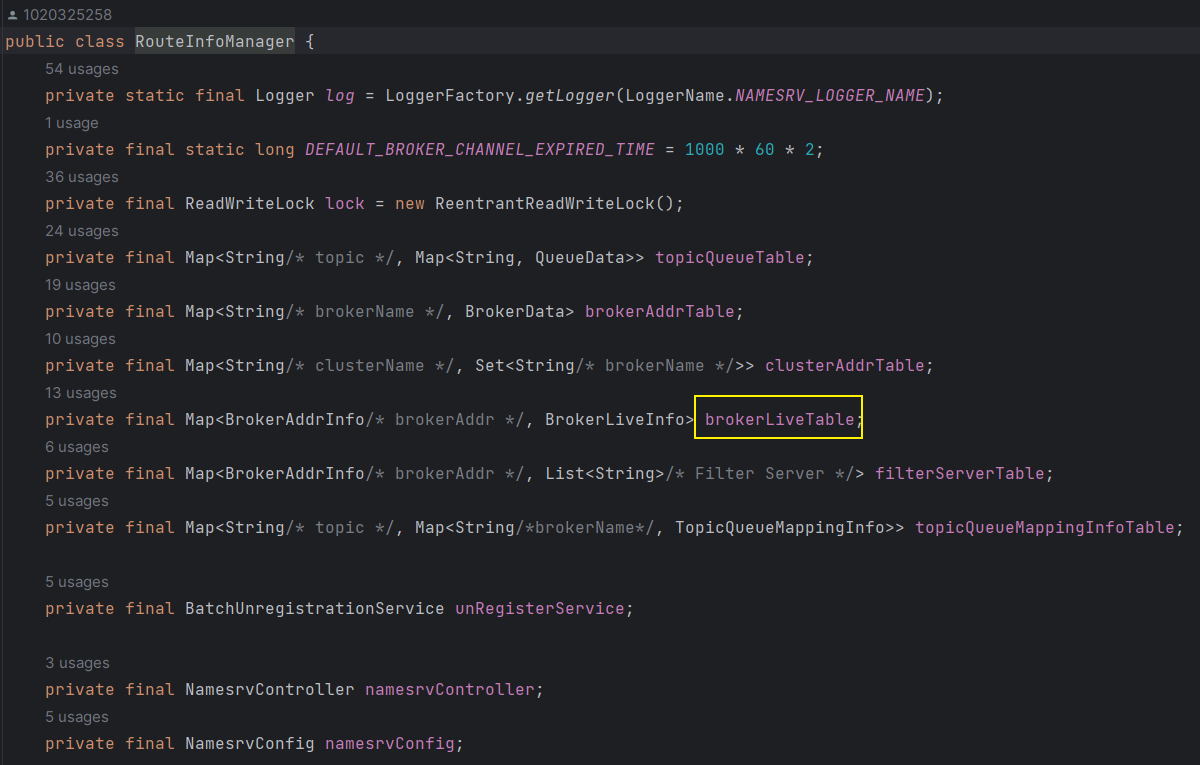
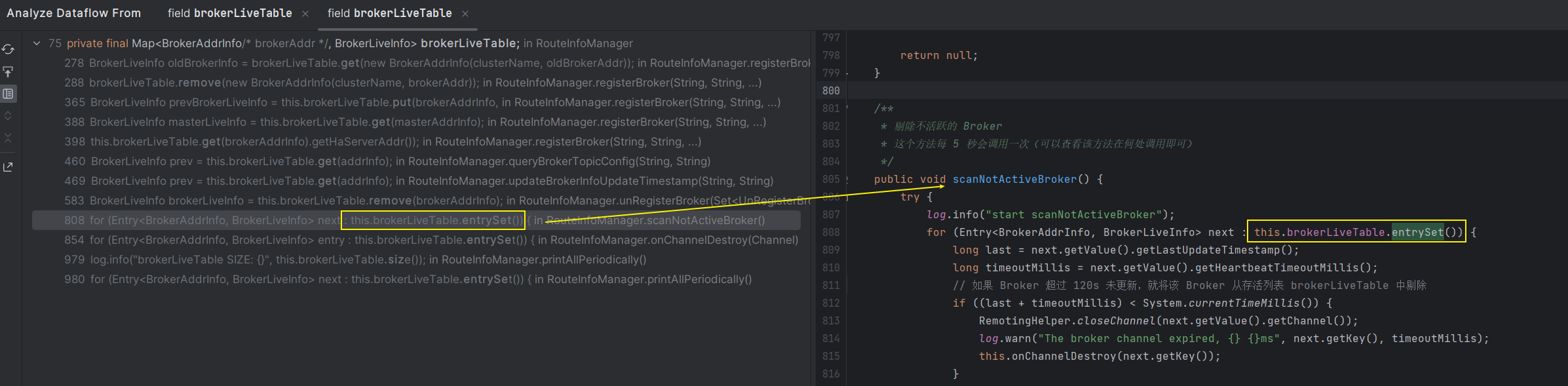
其中 brokerLiveTable 存储的是存活的 Broker 列表,那么可以查看该变量的引用链,来判断 Nameserver 在哪里进行心跳扫描

可以看到在 scanNotActiveBroker 方法中,会将 brokerLiveTable 中不活跃的 Broker 给剔除掉
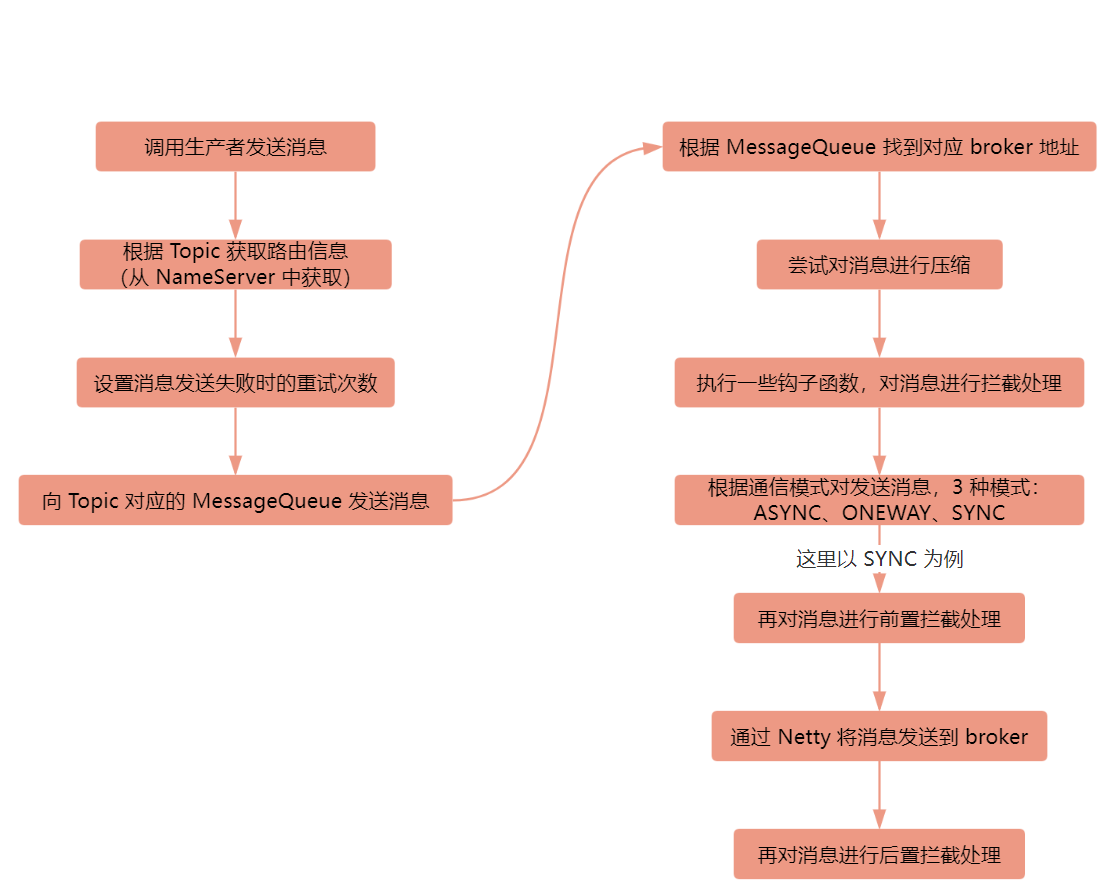
# 生产者的发送消息流程
下面会将整体的一个发送消息的流程图片先展示出来,再通过代码进行一步一步梳理:
既然要看生产者的发送消息流程,就先通过方法的调用作为入口,一步一步探究流程:

那么通过这个 send 方法点进去,入口为:DefaultMQProducer # send(Message msg) 方法,从该方法点击进入,调用链如下:
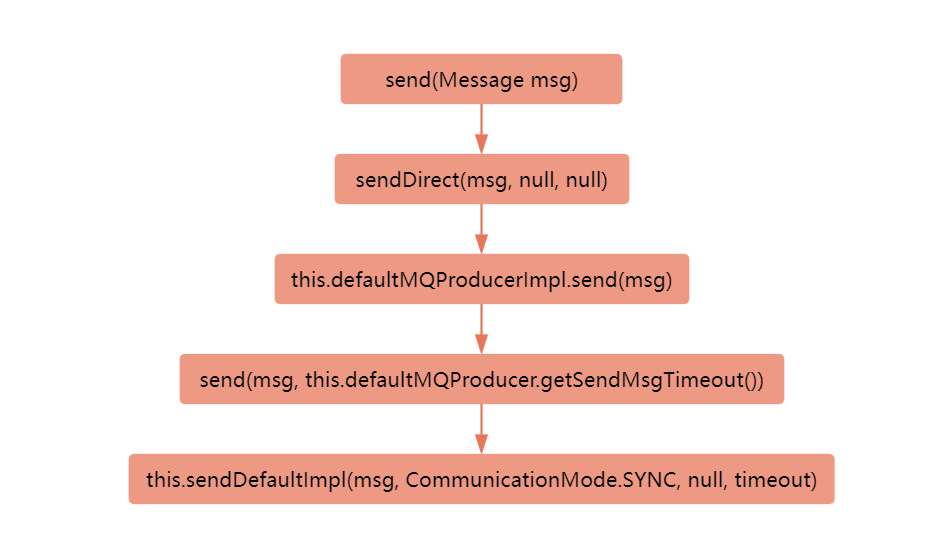
如果你在看源码的话,可以从上边的调用链一步一步点击,最后发送消息的逻辑就在 this.sendDefaultImpl 方法中展开
- 首先,会先根据 Topic 获取对应的路由信息,表示该 Topic 需要向哪个 MessageQueue 中进行发送,这个路由信息会先从本地缓存中取,如果没有取到,会向 NameServer 发送请求来获取 Topic 的路由信息
- 设置消息发送失败的
重试次数,同步情况下重试次数为预设次数 +1,异步情况下默认重试次数为 1 - 接下来就根据
重试次数循环发送消息,为 Topic 选择要发送的队列 MessageQueue 进行消息发送
选择队列之后,就进入到发送消息的核心逻辑:this.sendKernelImpl(msg, mq, communicationMode, sendCallback, topicPublishInfo, timeout - costTime);
- 在该方法中,先通过队列 MessageQueue 找到对应的 brokerAddr
- 之后,会尝试对消息进行压缩
- 判断是否存在一些需要对消息进行
禁止发送或前置拦截的钩子函数,进行一些消息的拦截处理 - 判断通信模式:ASYNC、ONEWAY、SYNC,将消息以对应的方式发送出去,这里以同步
SYNC为例
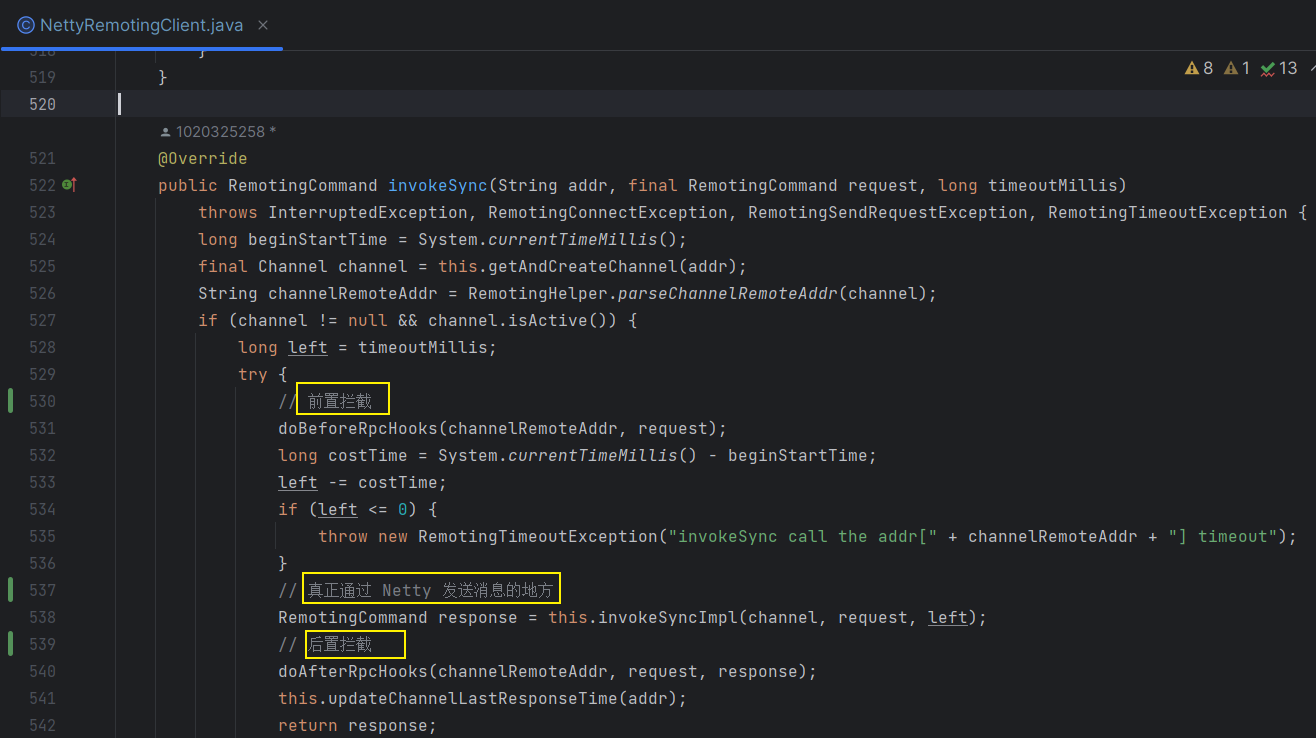
如果是同步的话,会通过 this.mQClientFactory.getMQClientAPIImpl().sendMessage() 方法将消息发送出去,接下来又是层层的调用,最后真正通过 Netty 将消息发送出去的地方在 NettyRemotingClient # invokeSync() 的方法中
在这个方法中,还会对消息进行前置拦截和后置拦截,为开发者的使用提供了很多的扩展点,在这里就 真正通过 Netty 将消息发送出去了
# 消费者的接收消息流程
还是先把消费者接收消息的流程图贴出来,再细说代码流程:
首先先从消费者的业务调用出发
// 创建消费者对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("delay_group");
// ...
// 注册监听消息
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
System.out.println(new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 启动消费者
consumer.start();
那么我们就从 consumer.start() 进入,看一下消费者的启动逻辑,该方法的核心代码也就是:
this.defaultMQPushConsumerImpl.start();
那么进入到这个 start 方法,这里进行了一些配置以及客户端的启动:
- 通过
checkConfig()检查消费组的一些配置:名称是否符合规范、消费者的线程数、消费者的监听等等 - 之后再设置一些属性
- 通过
mQClientFactory.start()启动客户端
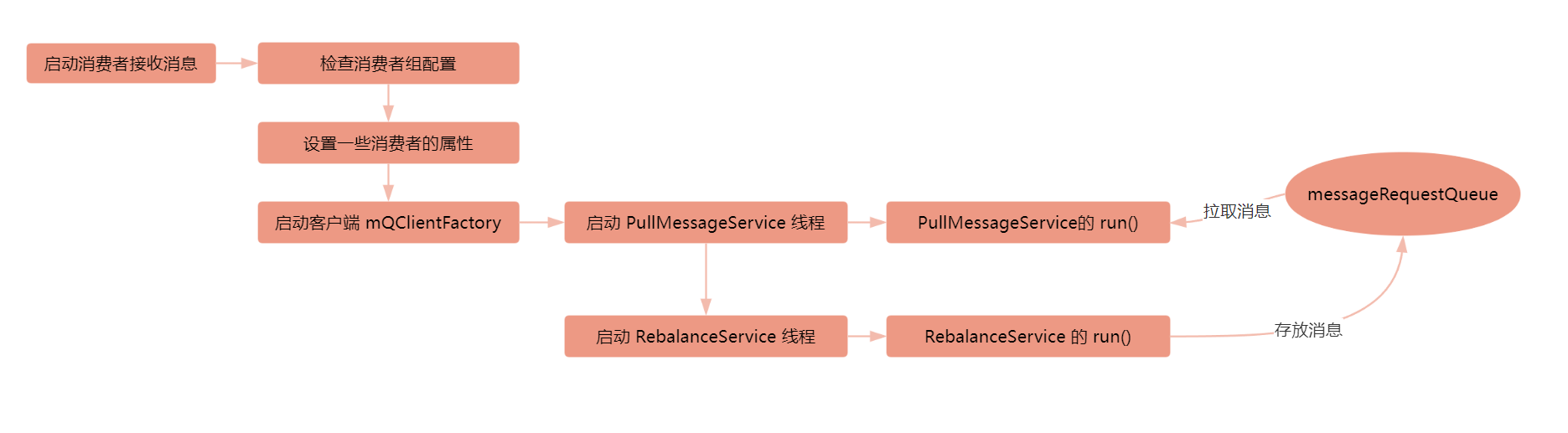
那么我们进入到启动客户端这个逻辑,我们猜测这里 start 之后,可能就可以进行消息的拉取了,那么在 start 这个方法中,看到了有下边这一行:
this.pullMessageService.start();
这不正是拉取消息的服务吗?点进去之后,发现就是启动了一个线程,这个线程呢就是 this,那么我们点进去这个 start 方法是定义在 ServiceThread 类中,这个类并没有定义 run 方法,因此呢,这个 run 方法应该是定义在了子类 PullMessageService 类中,点进去找到 run 方法,可以看到在 run 方法中就会不停地去 messageRequestQueue 中拉取数据:
MessageRequest messageRequest = this.messageRequestQueue.take();
既然在这里拉取数据了,那么数据是什么时候放到 messageRequestQueue 中的呢?
只需要搜一下哪里调用到了 this.messageRequestQueue.put 就可以知道了,找到之后呢,我们在这一行打个断点,再去启动生产者,就可以知道整个调用链了,

那么根据栈调用情况呢,可以发现这一行是通过 RebalanceService 的 run 方法进入的,那么这个 RebalanceService 一定是在哪里作为一个线程被启动了

那么呢,我们之前说了在启动客户端的时候,调用 this.pullMessageService.start() 启动了这个线程,那么在下一行就启动了 rebalanceService 这个线程:

因此呢,就通过 debug 的方式找到了向 messageRequestQueue 中存放消息就是在 RebalanceService 这个线程中做的
# 消息的可靠性如何保证?
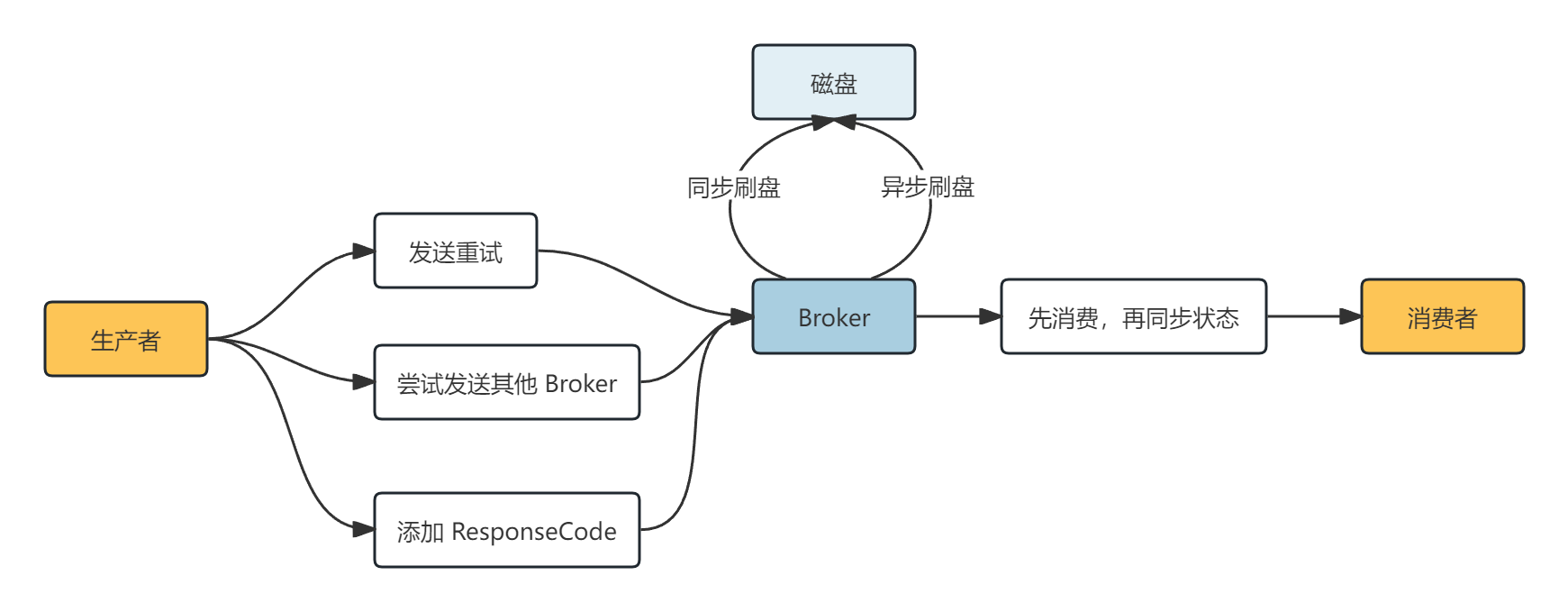
生产者保证消息的可靠性:生产者发送消息分为同步发送、异步发送、单向发送三种方式,那么单向发送是没有消息可靠性的保证的,而在同步和异步发送中,都可以通过添加消息的
重试次数、添加 ResponseCode、添加当前 Broker 不可用时发送到其他 Broker三种策略来保证数据的发送可靠性Broker 保证消息的可靠性:即保证消息发送到 Broker 中,不会因为 Broker 突然宕机而导致数据丢失,那么其实就是保证消息存储在 Broker 的可靠性,肯定是需要将数据存储在磁盘上才可靠,那么数据存储到磁盘上的方式还分为了
同步刷盘和异步刷盘,同步刷盘不会丢失消息,异步刷盘可能会丢失!那么 Broker 可能磁盘还会损坏呢,因此还需要通过备份节点来保证消息的可靠性,因此呢在 Broker 端有两种可靠性保证:
刷盘策略(同步刷盘、异步刷盘)和备份节点消费者保证消息的可靠性:保证数据的消费,通过先消费数据,再提交成功状态来保证,消费者还需要具有一定的
幂等性处理,因为消费者可能会消费多条消息如果消费者最终重试消费消息失败,那么还可以通过去死信队列中消费数据来保底
# 消息的有序性如何保证?
还是从三个方面来保证:发送端、存储端、消费端
发送端保证消息的有序性:要保证有序性,那么必须要将需要保证有序性的消费给放到同一个队列中才可以,因此在 Topic 中设置一个队列就可以保证消息的有序性;如果在 Topic 中设置了多个队列,那么只需要将需要保证有序的消息放在同一个队列中即可,这种方式需要使用下图中的 api 来实现一个队列选择器,让有序消息选择同一个队列发送即可

存储端保证消息的有序性:通过 CommitLog + MessageQueue + IndexFile 来保证消息在 MessageQueue 中有序存储即可
消费端保证消息的有序性:可以为消费者注册有序消费的监听器即可
MessageListenerOrderly
如果想要保证在多个队列中消息的有序性,可以使用
全局的时间戳,在消费端记录已经消费消息的最小时间戳即可保证消费的有序性!
# Broker 接收消息的处理流程?
既然要分析 Broker 接收消息,那么如何找到 Broker 接收消息并进行处理的程序入口呢?
那么消息既然是从生产者开始发送,消息是有单条消息和批量消息之分的,那么消息肯定是有一个标识,当 Broker 接收到消息之后,肯定是需要通过判断消息的标识来区分单条消息和批量消息,那么只需要找到发送消息的标识,再全局搜索,就可以找到这个标识在哪里被处理,被处理的地方一定就是 Broker 接收消息处理的位置了!
那么还是先找到发送消息的位置:DefaultMQProducer # send(Message msg) ,通过层层调用(这里在生产者发送消息流程中讲了)到达了 DefaultMQProducerImpl # this.sendKernelImpl()
在这个方法中就调用到了 MQ 客户端的发送消息的方法 this.mQClientFactory.getMQClientAPIImpl().sendMessage()
在这里真正的通过 Netty 去发送消息到 Broker 中去:
通过判断消息的类型构造一个 RemotiongCommand 类型的 request 参数
这里有 4 个构造 request 参数的方法,如下图会走到第三个方法中,那么这里的请求标识为
RequestCode.SEND_MESSAGE_V2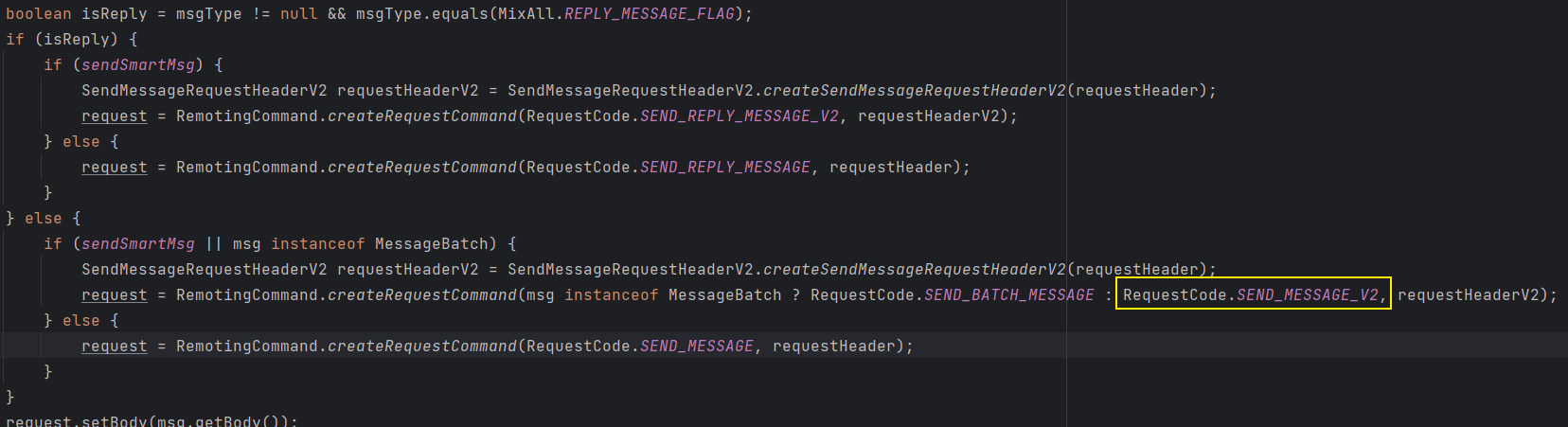
在
this.sendMessageSync(addr, brokerName, msg, timeoutMillis - costTimeSync, request)方法中通过 Netty 将消息发送出去,那么这个方法需要传入一个 request 参数
在上边构造了 request 并且通过 Netty 发送出去,request 的标识为 RequestCode.SEND_MESSAGE_V2 ,那么我们只需要找到处理该标识的 request 的位置,那就是 Broker 处理消息的位置,在 IDEA 中通过 Ctrl+Shift+F 全局搜索这个标识即可:
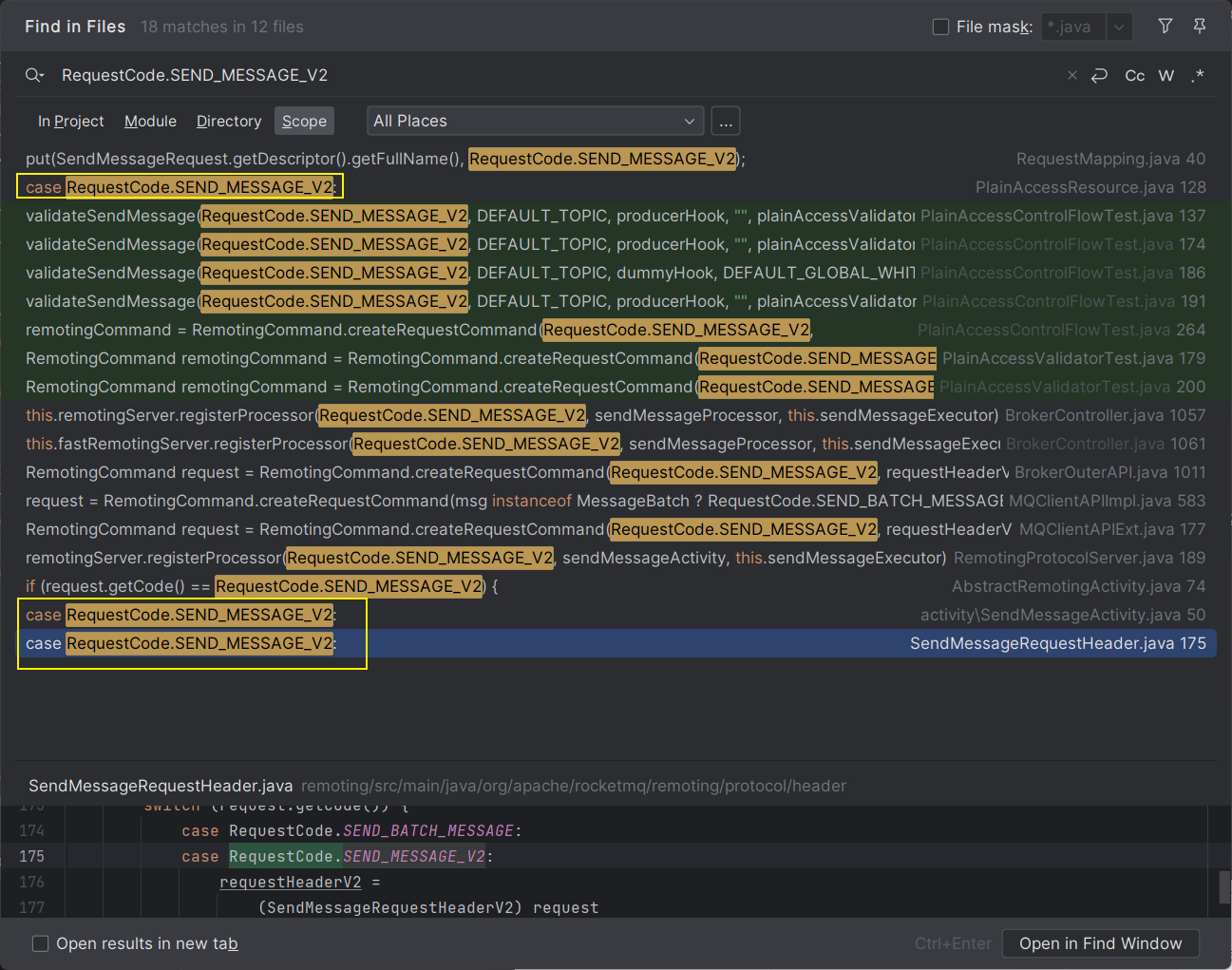
可以发现有三个进行 case 判断的地方:
- 第一个在
PlainAccessResource类中 - 第二个在
SendMessageActivity类中 - 第三个在
SendMessageRequestHeader类中
这里第三个 case 判断的地方就是 Broker 处理消息的位置(可以在三个 case 中都 debug,看断点走到哪里就知道了)
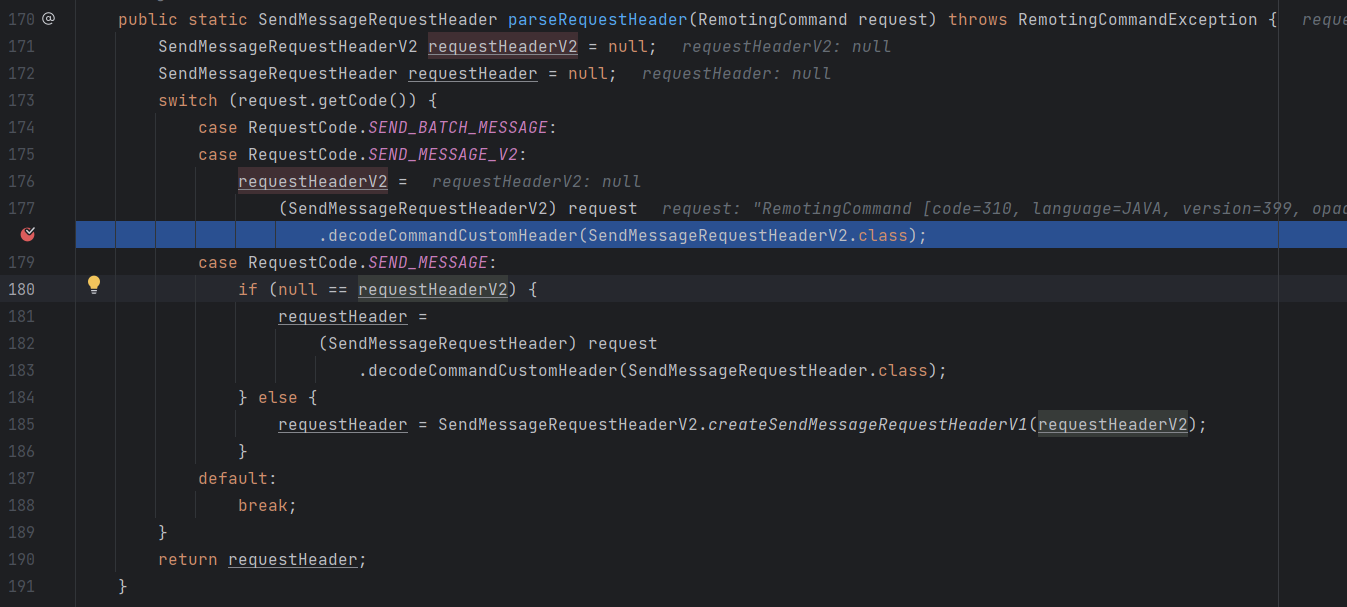
那么我们就在第三个 case 判断的位置打上断点
接下来启动 NameServer,再以 Debug 的方式启动 Broker,再启动生产者,根据调用堆栈信息来找到 Broker 处理消息的整个调用链:

根据这个堆栈信息,可以发现,调用链是从 NettyServerHandler 的 channelRead0 转移过来的,那么也就是再 NettyServerHandler 这个 Netty 的服务端接收到消息并进行处理,那么我们就在这个堆栈信息中找 Broker 是在哪里对消息进行处理了呢?
就是在 SendMessageProcessor # processRequest 方法中(也就是堆栈顶第3个方法),在这个方法中:
- 通过
parseRequestHeader(request)先对请求头进行解码,也就是根据请求头RequestCode.SEND_MESSAGE_V2的类型做一些相应的处理 - 接下来通过
buildMsgContext(ctx, requestHeader, request)创建消息的上下文对象 this.executeSendMessageHookBefore(sendMessageContext)执行一些消息发送前的钩子(扩展点)- 核心:
this.sendMessage()真正去发送消息
那么在 this.sendMessage() 中就是真正发送消息的逻辑了:
首先是
preSend(ctx, request, requestHeader)进行预发送,这里其实就是对发送的消息进行一些检查(Topic 是否合法?Topic 是否与系统默认 Topic 冲突?Topic 的一些配置是否存在?等等信息)如果
queueIdInt < 0是 true 的话,表明生产者没有指定要发送到哪个队列,那么就通过99999999 % 队列个数来选择一个队列发送将超过最大重试次数的消息发送到 DLQ 死信队列中去
if (!handleRetryAndDLQ(requestHeader, response, request, msgInner, topicConfig, oriProps)) { return response; }接下来判断 Broker 是否开启了
异步模式,如果开启的话,通过asyncPutMessage()处理如果没有开启
异步模式,通过putMessage()处理,这里其实还是调用了asyncPutMessage(),只不过通过get()阻塞等待结果(复用代码)
那么在发送消息的时候,无论是否异步,都会进入到 DefaultMessageStore # asyncPutMessage() 方法中,我们就点进去看看进行了哪些处理:
执行一些钩子函数,作为扩展点:
putMessageHook.executeBeforePutMessage(msg)提交文件的写请求:
CompletableFuture<PutMessageResult> putResultFuture = this.commitLog.asyncPutMessage(msg)在这个写文件的方法中,主要做一些文件的写操作,以及将文件写入到磁盘中
- 获取文件对象:
this.mappedFileQueue.getLastMappedFile() - 追加写文件的操作:
mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext) - 最后进行刷盘以及高可用的一些处理:
handleDiskFlushAndHA(putMessageResult, msg, needAckNums, needHandleHA)
- 获取文件对象:
打印写文件消耗的时间
this.getSystemClock().now() - beginTime
那么 Broker 总体的接收消息的处理流程就是上边将的这么多了,当然还有一些边边角角的内容没有细说,先了解整体的处理流程,不要提前去学习太多的细节!
# RocketMQ 高级特性
# 消息存储在 Broker 的文件布局
RocketMQ 的混合存储
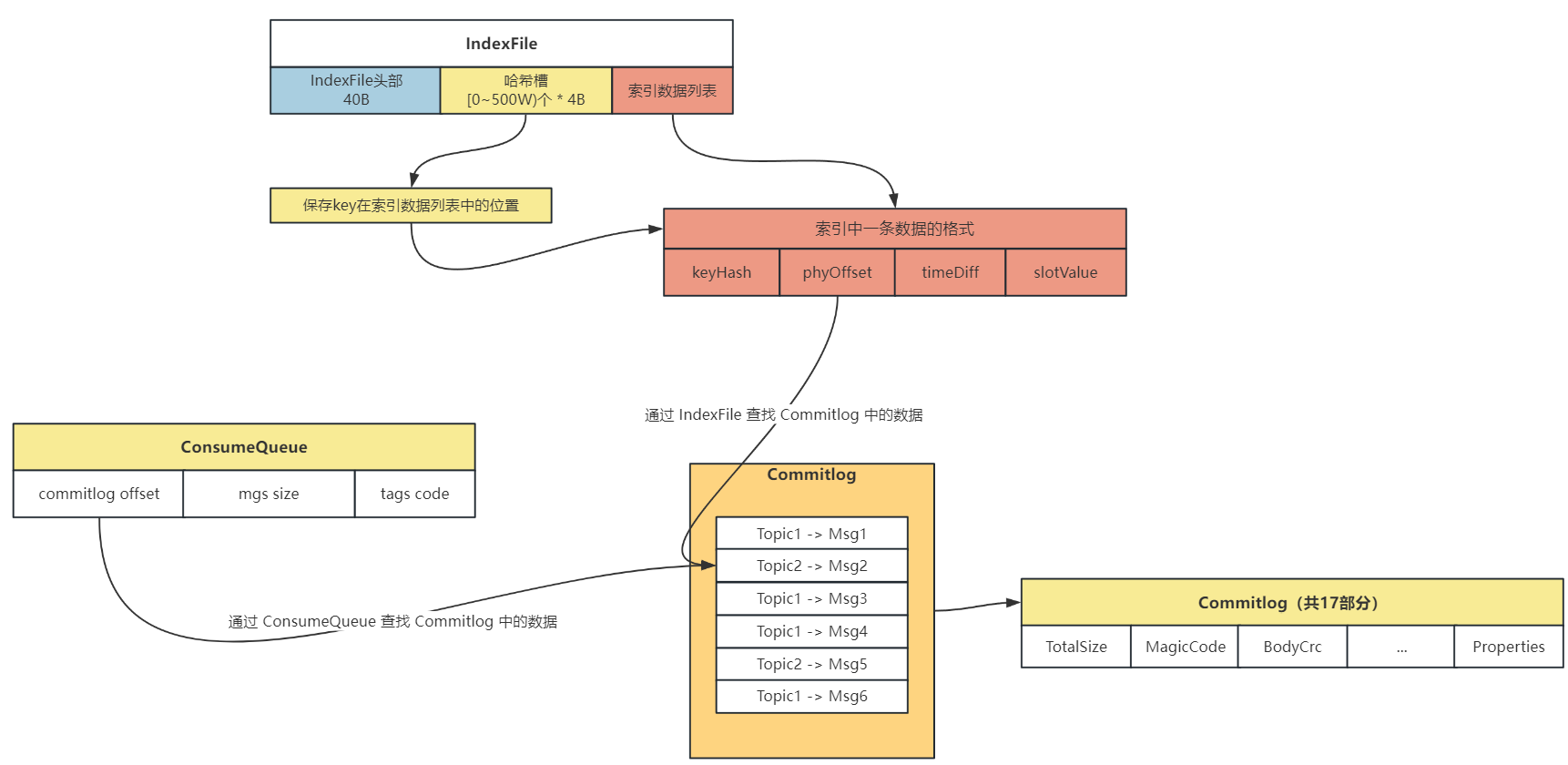
在 RocketMQ 存储架构中,采用混合存储,其中有 3 个重要的存储文件:Commitlog、ConsumeQueue、IndexFile
- Topic 的消息实体存储在
Commitlog中,顺序进行写入 ConsumeQueue可以看作是基于 Topic 的 Commitlog 的索引文件,在 ConsumeQueue 中记录了消息在 Commitlog 中的偏移量、消息大小的信息,用于进行消费IndexFile提供了可以通过 key 来查询消息的功能,key 是由topic + msgId组成的,可以很方便地根据 key 查询具体的消息
消费者去 Broker 中消费数据流程如下:
- 先读取 ConsumeQueue,拿到具体消息在 Commitlog 中的偏移量
- 通过偏移量在 Commitlog 读取具体 Topic 的信息
消费者去寻找 Commitlog 中的数据流程图如下:
那么先来看一下 Commitlog 文件在哪里进行写入
从 SendMessageProcessor # processRequest 作为入口,
经过层层调用 this.sendMessage() -> this.brokerController.getMessageStore().putMessage(msgInner) -> DefaultMessageStore # asyncPutMessage ,最终到达 asyncPutMessage() 方法中,在这里会进行消息的磁盘写的操作:
创建消息存储所对应的 ByteBuffer:
putMessageThreadLocal.getEncoder().encode(msg)在这个方法中,会对 Commitlog 文件进行写入:
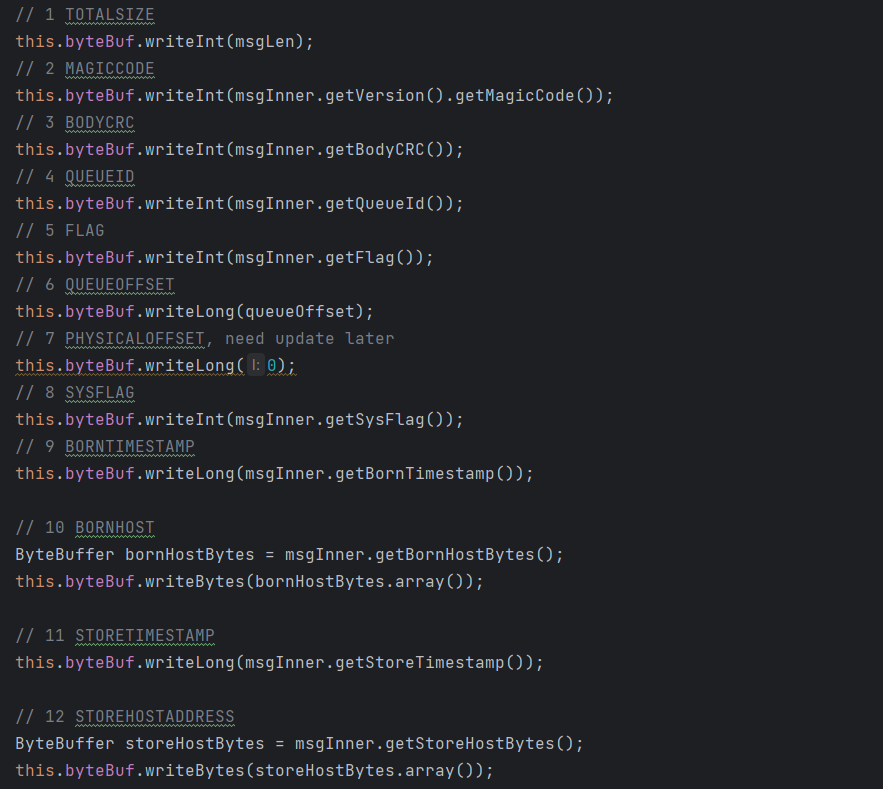
这里的 byteBuffer 也就是 Commitlog 文件的结构如下:

将创建的 ByteBuffer 设置到 msg 中去:
msg.setEncodedBuff(putMessageThreadLocal.getEncoder().getEncoderBuffer())开始向文件中追加消息:
result = mappedFile.appendMessage(msg, this.appendMessageCallback, putMessageContext)
在 appendMessage 方法中主要是写入消息之后,Commitlog 中一些数据会发生变化,因此需要进行修改,还是经过层层调用 appendMessage()-> appendMessagesInner()-> cb.doAppend(),最终到达 doAppend 方法,接下来看这个方法都做了些什么:
首先取出来在上边创建消息对应的 ByteBuffer:
ByteBuffer preEncodeBuffer = msgInner.getEncodedBuff()接下来修改这个 ByteBuffer 中的一些数据:
这个 ByteBuffer 在创建的时候已经将一些默认信息设置好了,这里只需要对写入消息后会变化的信息进行修改!
- 先修改 QueueOffset (偏移量为 20 字节):
preEncodeBuffer.putLong(20, queueOffset) - 再修改 PhysiclOffset (偏移量为 28 字节):
preEncodeBuffer.putLong(28, fileFromOffset + byteBuffer.position()) - 再修改 SysFlag、BornTimeStamp、BornHost 等等信息,都是通过偏移量在 ByteBuffer 中进行定位,再修改
- 先修改 QueueOffset (偏移量为 20 字节):
那么通过上边就 完成了对 Commitlog 文件的追加操作 ,ReputMessageService 线程中的 run 方法,会每隔 1ms 就会去 Commitlog 中取出数据,写入到 ConsumeQueue 和 IndexFile 中
那么接下来寻找写 ConsumerQueue 的地方,也是通过调用链直接找到核心方法:
DefaultMessageStore # ReputMessageService # run-> this.doReput()-> DefaultMessageStore.this.doDispatch(dispatchRequest)-> dispatcher.dispatch(req)-> 这里进入到构建 ConsumeQueue 类的 dispatch 方法中:CommitLogDispatcherBuildConsumeQueue # dispatch()-> DefaultMessageStore.this.putMessagePositionInfo(request)-> this.consumeQueueStore.putMessagePositionInfoWrapper(dispatchRequest)-> this.putMessagePositionInfoWrapper(cq, dispatchRequest)-> consumeQueue.putMessagePositionInfoWrapper(request)-> this.putMessagePositionInfo()
这个调用链比较长,如果不想一步一步点的话,直接找到 ConsumeQueue # this.putMessagePositionInfo() 这个方法即可,在这个方法中向 byteBufferIndex 中放了 3 个数据,就是ConsumeQueue 的组成 = Offset + Size + TagsCode
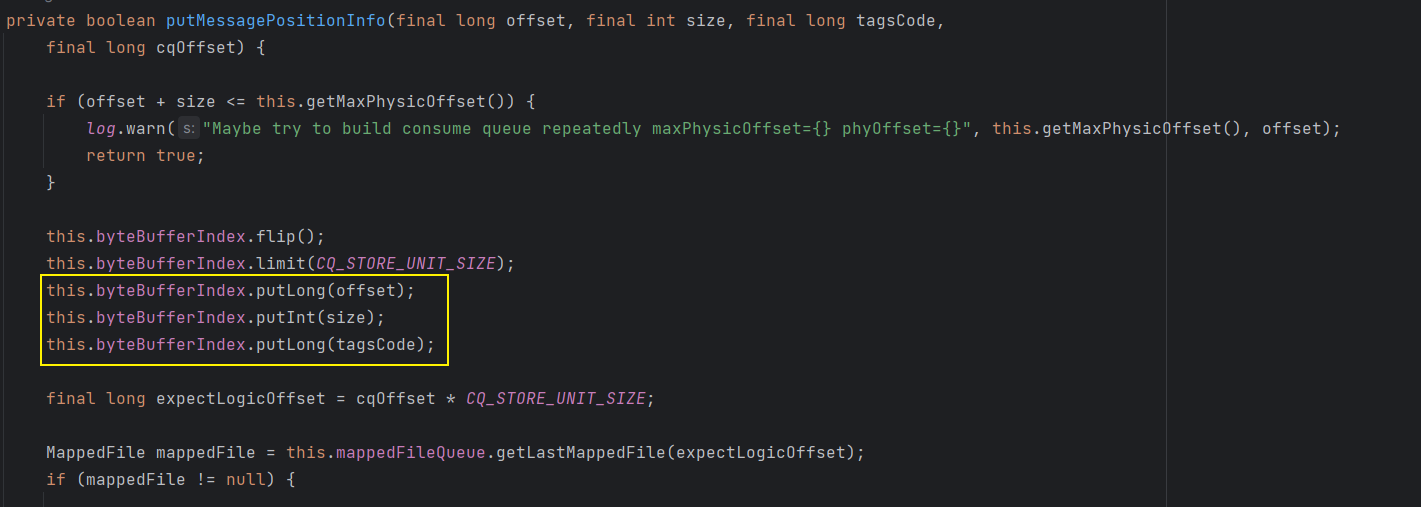
那么 ConsumeQueue 的组成结构就如下所示,通过 ConsumeQueue 主要用于寻找 Topic 下的消息在 Commitlog 中的位置:

IndexFile 主要是通过 Key(Topic+msgId) 来寻找消息在 Commitlog 中的位置
接下来看一下 IndexFile 结构是怎样的,在上边寻找 ConsumeQueue 的调用链中,有一个 dispatcher.dispatch() 方法,这次我们进入到构建 IndexFile 的实现类的 dispatch 方法中,即:CommitLogDispatcherBuildIndex # dispatch(),那么接下来还是经过调用链到达核心方法:
CommitLogDispatcherBuildIndex # dispatch()-> DefaultMessageStore.this.indexService.buildIndex(request)-> indexFile = putKey(indexFile, msg, buildKey(topic, req.getUniqKey()))-> indexFile.putKey(idxKey, msg.getCommitLogOffset(), msg.getStoreTimestamp())
那么核心方法就在 IndexFile # putKey() 中:
首先根据 key 计算出哈希值,key 也就是
Topic + 消息的 msgId再通过哈希值对哈希槽的数量取模,计算出在哈希槽中的相对位置:
slotPos = keyHash % this.hashSlotNum计算 key 在 IndexFile 中的绝对位置,通过
哈希槽的位置 * 每个哈希槽的大小(4B) + IndexFile 头部的大小(40B)代码即:
absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize计算索引在 IndexFile 中的绝对位置,通过
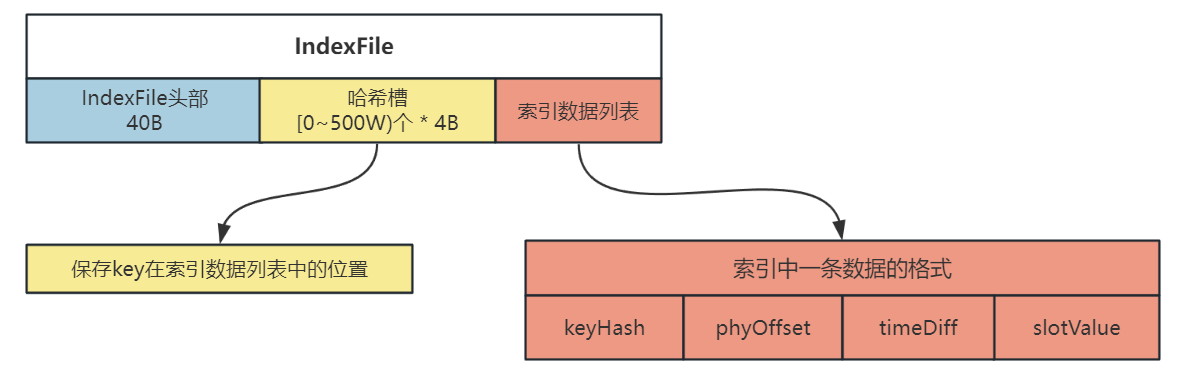
absIndexPos = IndexFile 头部大小(40B) + 哈希槽位置 * 哈希槽大小(4B) + 消息的数量 * 消息索引的大小(20B)int absIndexPos = IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize + this.indexHeader.getIndexCount() * indexSize;向 IndexFile 的第三部分(索引列表)中放入数据的索引,索引包含 4 部分,共 20B:
keyHash、phyOffset、timeDiff、slotValue
向 IndexFile 的第二部分(哈希槽)中放入数据

IndexFile 的结构如下图所示:

# 消息存储的高效与刷盘策略
RocketMQ 是通过文件进行存储消息的,那 RocketMQ 是如何保证存储的高效性的呢?
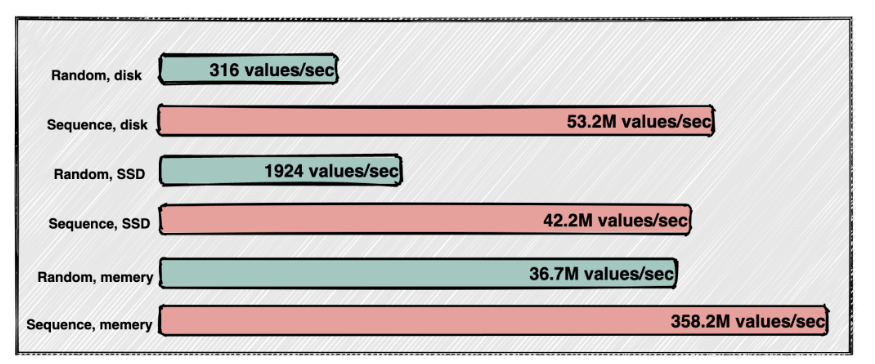
首先是通过对磁盘进行
顺序写可以保证高性能的文件存储:- 随机写速度 10KB/s
- 顺序写速度 600MB/s
(图片来源于网络)
文件拷贝利用了
零拷贝以及内存映射技术(MMP)通过使用零拷贝减少数据拷贝次数
利用内存映射技术(MMP)可以像读写磁盘一样读写内存,可以获得很大的 IO 提升,但是写到 MMP 中的数据并没有被真正写到磁盘中,操作系统会在程序主动调用 flush 的时候才把数据真正的写入到磁盘
刷盘策略:分为同步刷盘和异步刷盘同步刷盘会造成阻塞,需要等待刷盘完成,降低吞吐量
异步刷盘不会阻塞,提升吞吐量,但是会丢失部分数据
# Broker 快速读取消息机制
首先还是通过 DashBoard 项目的页面进行查看,发现检索消息有两种方式:
Topic + Key

Topic + MessageId
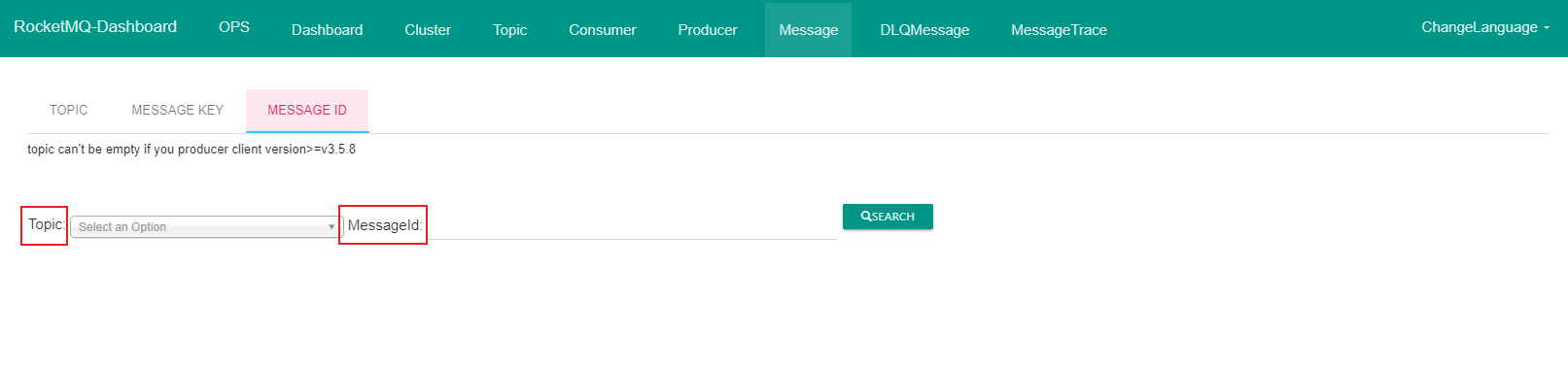
那么这两种检索的方式其实就是通过上边我们讲的 Broker 中文件的布局
不知道大家还记不记得 IndexFile # putKey() 这个方法,就是将一个 Key 放到 IndexFile 中作为索引,那么这里我们通过生产者发送一条消息,其实是会在 Broker 中调用两次 putKey() 这个方法,只不过两个 Key 是不同的,分别是: Topic + Key、 Topic + MessageId,这样当然就可以通过这两种方式来检索消息了!
而 IndexFile 既然存储了这两个 Key 所对应消息的索引,也就是在 Commitlog 中的物理偏移量,这个类就一定还提供了根据 Key 查询消息在 Commitlog 中物理偏移量的方法,也就是 IndexFile # selectPhyOffset,在这个方法中,会通过传入的 Key 在 IndexFile 中查询到对应的索引,从索引中取出对应的物理偏移量 phyOffset,流程如下:
- 根据 Key 拿到哈希值,并且对哈希槽数量取模,得到这个 Key 在哈希槽中的相对位置
- 去哈希槽中取到这个 Key 在索引数据列表中的位置,在索引数据列表中拿到这个 Key 的索引,就可以取出这个索引的在 Commitlog 中的物理偏移量
phyOffset
# 文件恢复与 CheckPoint 机制
文件恢复的目的:
让 Broker 重新启动之后,可以完成对 flushedPosition、commitedWhere 指针位置的设置,让程序可以知道上次写的位置,可以继续接收消息在上次写的位置之后继续写数据!
如何检测是否正常:
首先检查 Broker 是否正常退出的标准就是:
abort文件是否存在,如果存在表示 Broker 异常退出abort 文件是 Broker 启动时会创建的一个临时文件,当 Broker 正常退出时,通过注册的 JVM 钩子函数就会将 abort 文件删除掉;如果异常关闭,则 abort 文件被保留,代表 Broker 异常退出
检查 Commitlog、ConsumeQueue、IndexFile 文件是否正常的标准就是: checkpoint 文件
checkpoint 会记录三个偏移量,在这三个偏移量之前的数据都是正常的:
- physicMsgTimestamp:物理偏移量,记录 CommitLog 上一次刷盘的时点
- logicsMsgTimestamp:逻辑偏移量,记录 ConsumeQueue 的刷盘时点
- indexMsgTimestamp:索引偏移量,记录 IndexFile 的刷盘时点
查找执行文件恢复方法的入口:
Broker 文件恢复入口在 DefaultMessageStore # load(),那么是从哪里调用这个恢复的入口呢?(在 Broker 启动的时候)
BrokerStartup的main()主启动类中,调用了createBrokerController()方法BrokerStartup的createBrokerController()中调用了initialize()方法BrokerController的initialize()方法中,调用了recoverAndInitService()方法BrokerController的recoverAndInitService()方法中,调用了 load() 方法:result = this.messageStore.load()
文件恢复的流程:
首先文件恢复总体的流程如下:

那么文件恢复的入口就是在 DefaultMessageStore # load() 方法中:
- 首先判断 abort 文件是否存在:
boolean lastExitOK = !this.isTempFileExist() - 加载 Commitlog 文件,调用
result = this.commitLog.load()- 去存储 Commitlog 文件的目录下,加载所有 Commitlog 文件,并将 Commitlog 文件构建为 MappedFile 逻辑对象
- 将构建好的 MappedFile 逻辑对象的三个变量值设置为初始值:将 WrotePosition、FlushedPosition、CommitedPosition 的值先初始化为文件大小
- 加载 ConsumeQueue 文件,调用
result = result && this.consumeQueueStore.load()- 在这里会去存储 consume files 文件的目录下,加载所有文件并且创建 ConsumeQueue 逻辑对象
- 构建 topic、queueId、consumeQueue 三者的关系:
<topic : <queueId : consumeQueue>>
- 数据恢复主要是在
this.recover(lastExitOK)方法
那么接下来进入到 recover(lastExitOK) 方法中,看数据恢复的逻辑是怎样的:
如果 lastExitOK 是 true,表示 Broker 正常退出,通过
this.commitLog.recoverNormally(maxPhyOffsetOfConsumeQueue)恢复这个方法是在 CommitLog 类中,是对 CommitLog 文件进行恢复
- 在正常退出时,对 commieLog 恢复的逻辑为:从倒数第三个文件开始恢复,恢复完成后设置 flushedWhere 和 commitWhere 两个偏移量,并且将多余的文件删除
否则,表示 Broker 异常退出,通过
this.commitLog.recoverAbnormally(maxPhyOffsetOfConsumeQueue)恢复- 在异常退出时,对 commieLog 恢复的逻辑为:从倒数第一个文件开始恢复,迭代 mappedFiles 集合,找到 mappedFile 中的第一条写入的消息,校验是否满足条件,如果满足则从这个文件开始恢复,恢复完成后设置 flushedWhere 和 commitWhere 两个偏移量,并且将多余的文件删除
# 消息大量堆积如何处理?
消息出现大量堆积的原因是:生产者速度 >> 消费者速度
首先需要排除 代码层面 的问题,再去对 RocketMQ 的配置做处理!
那么对于消息堆积的处理,就分为两种情况:
事发时处理:
扩容消费者(在消费者数量 < MessageQueue 的情况下)
这里
增加消费者的数量是有依据的,比如一个 Topic 下有 8 个 MessageQueue,那么最多将消费者数量增加到 8 个,因为 Topic 下一个队列只可以被同一消费者组的一个消费者消费,如果消费者的数量比 Topic 下的队列数量多的话,会有部分消费者分不到队列,因此消费者数量最多和 Topic 下的队列数量相同设置消费者的并发线程数
提高单个消费者的消费并发线程,RocketMQ 支持批量消费消息,可以通过修改 DefaultMQPushConsumer 类中的 consumeThreadMin、consumeThreadMax 来提高单个消费者的并发能力
消费者批量拉取消息
新建临时 Topic 并设置 MessageQueue 数量多一点,将当前堆积信息转发到新建 Topic 中,再使用大量消费者去消费新的 Topic
提前设计预防:
- 生产者:限流,评估 Topic 峰值流量合理设计 Topic 的队列数量,添加异常监控
- 存储端:限流,将次要消息转移
- 消费者:降级次要消息消费,将重要消息落库(数据库或ES),再异步处理,合理根据 Topic 队列的数量和应用性能来部署消费者机器数量
- 上线前,采用灰度发布,先灰度小范围用户进行使用,没问题之后,再全量发布
# 部署架构和高可用机制
部署架构分为(这里的 Master ):
单 Mastaer
(图片来源于网络)

- 入门学习时常使用
单 Msater 单 Slave:Master 宕机后集群不可写入消息,但是可以从 Slave 读取消息
(图片来源于网络)
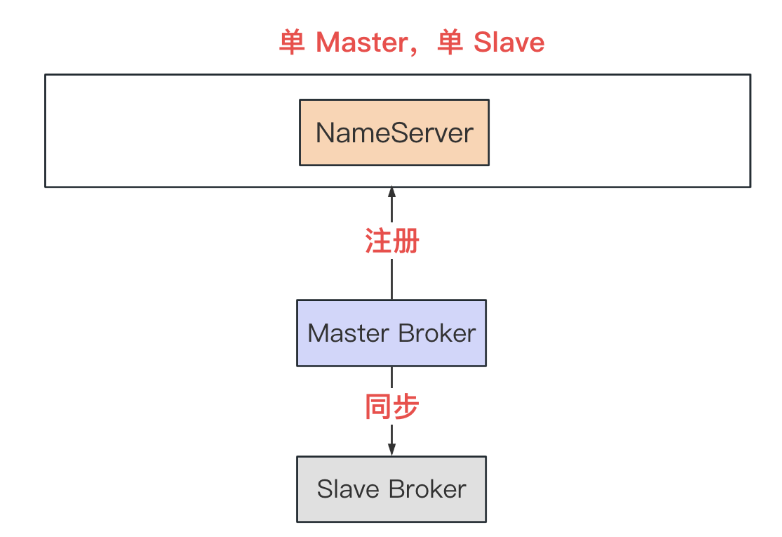
- 生产上不怎么使用,一般用作自己学习搭建主从使用
多 Master ,无 Slave
(图片来源于网络)
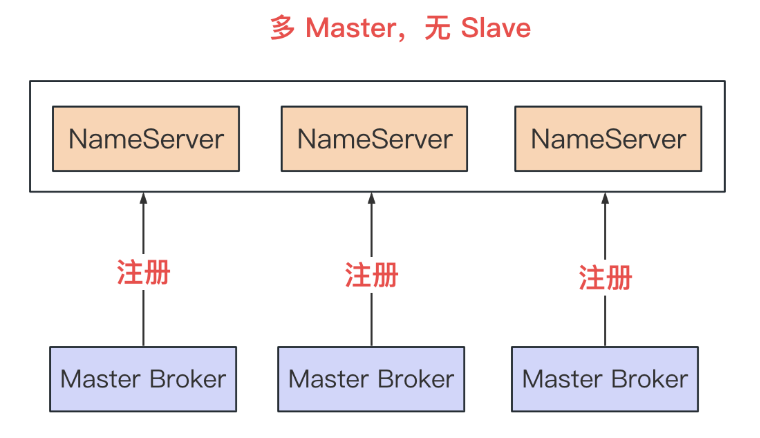
- 部署方式简单,生产常用
- 单个 Master 宕机后,不影响整体集群的读写服务,但是宕机的在这台服务中未被消费的消息,在这台服务下次重启之前无法被消费
多 Master,多 Slave,异步复制
(图片来源于网络)
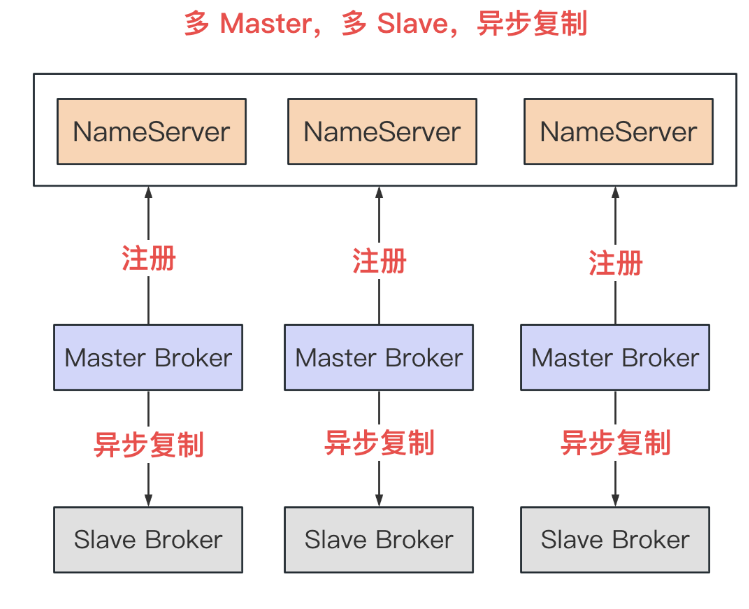
- Slave 作为备份节点,提供数据保障
- 但是异步复制,可能丢失部分 Master 中的数据
多 Msater,多 Slave,同步复制
(图片来源于网络)
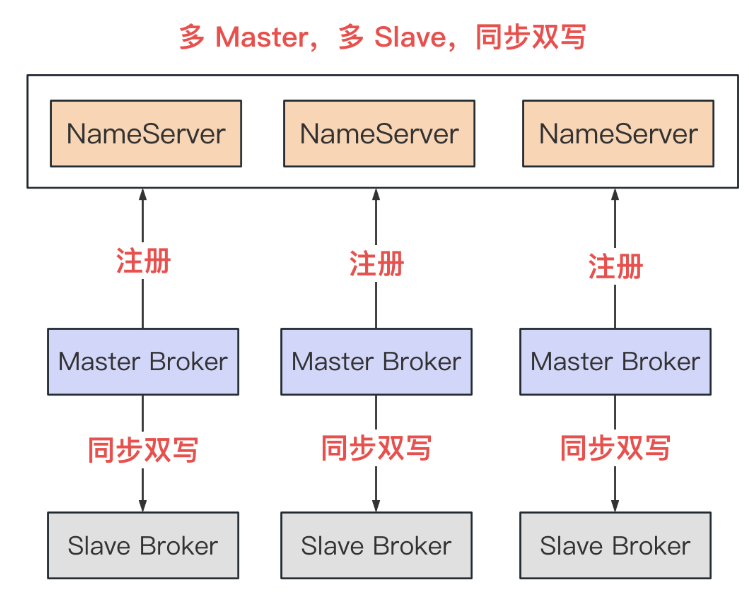
- 同步复制中,避免了丢失 Master 数据的风险
- 但是同步复制限制了整个集群的吞吐量
Dledger 模式
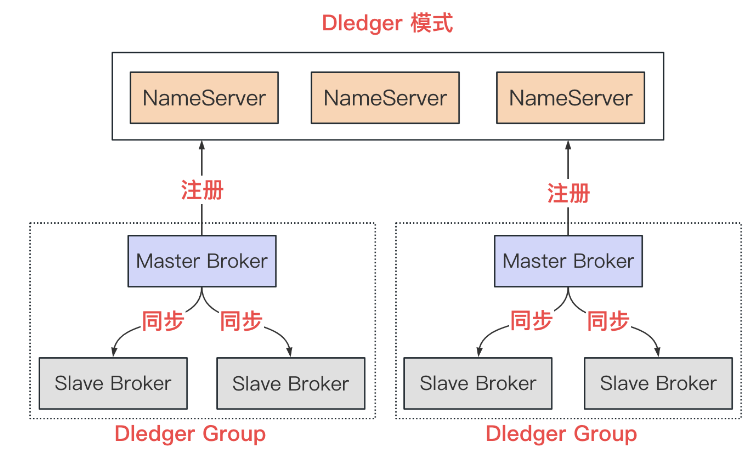
- 提供了在主从模式中,Master 挂了之后,自动将 Slave 选举为 Master 的功能
- 但是在 Dledger Group 中,至少需要 3 个 Broker 才可以完成选举