 01.深入理解Dubbo系列
01.深入理解Dubbo系列
# 最新 Dubbo3 深入理解原理系列
# Dubbo 相关资料
谁在使用 Dubbo3? (opens new window)
阿里技术专家详解 Dubbo 实践,演进及未来规划 (opens new window)
秒懂Dubbo接口(原理篇) (opens new window)
阿里集团业务驱动的升级 —— 聊一聊 Dubbo 3.0 的演进思路 (opens new window)
极客时间:提升技术认知★ (opens new window)
在极客时间中搜索资料!
CSDN Dubbo 专栏 (opens new window)
Apache dubbo 服务自省架构设计 (opens new window)
孙帅suns讲Dubbo (opens new window)
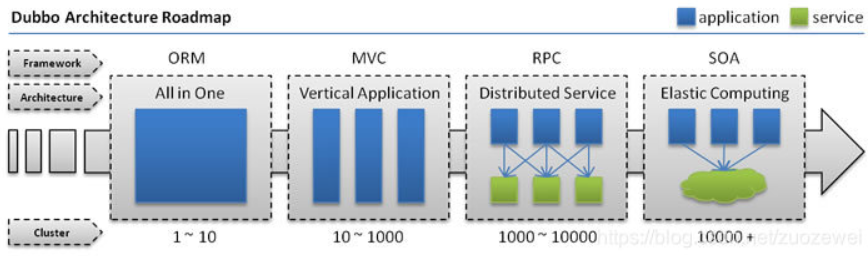
# 互联网的发展
随着互联网的发展,用户规模、数据规模、请求规模逐渐扩大,常规的单体架构、垂直应用架构已经无法满足网站需要,因此需要通过 分布式架构 、 流动计算架构 来对系统进行优化升级,提升性能来应对大规模的用户请求!
# 单一应用架构
将所有功能都揉进一个应用中,核心就是面向数据库的 CRUD 操作,该架构中的关键就是 ORM,通过 ORM 思想来操作数据库!
# 垂直应用架构
由单一应用架构进一步升级,按照子系统进行拆分,每个 子系统独立部署 、 共享数据库资源
解决了单体架构中子系统耦合程度高、扩展性差、不好维护的问题
像现在许多小公司,使用的还都是垂直应用架构,因为访问量、数据量都不大,垂直应用架构部署、开发简单,完全可以满足需求!
对于电商系统来说,垂直应用架构就是 Web 端 部署为一个 jar 包 ,Web 端应用是用户进行购物、结算等操作的,而 后台管理端 部署为另一个 jar 包 ,用于工作人员管理商品、库存的,他们是 两个不同的 JVM 进程 :

# RPC 架构
RPC 架构由垂直应用架构进一步演变,就是为了解决不同模块之间调用的问题

但是 RPC 架构也存在问题:比如库存管理模块压力比较大,我们 想要对库存管理模块进行扩容 ,部署多份,那么我们必须要 将后台管理端部署多份 才可以达到这个效果,这显然资源比较浪费,因为后台管理端还包括了商品管理模块和订单模块
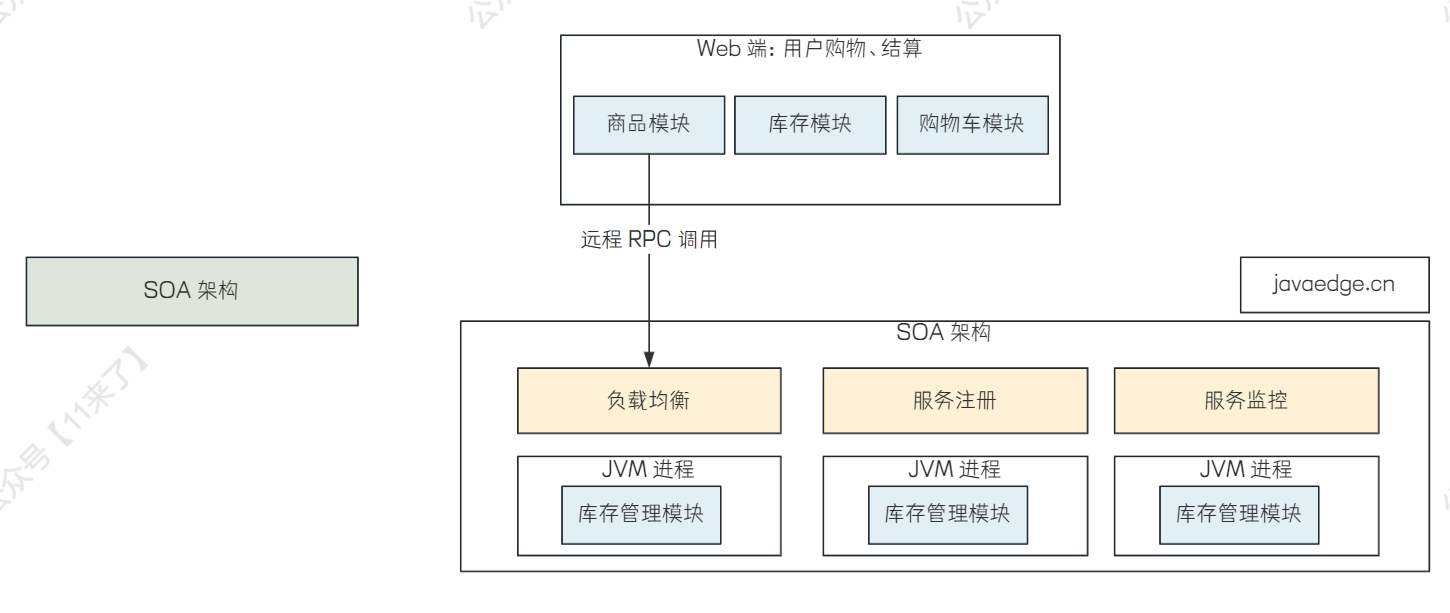
# 分布式架构
由 RPC 架构进一步升级,将应用的不同模块进行进一步的拆分,使得单个模块职责更加单一,相比于 RPC 架构,可以进行负载均衡、服务注册、服务监控等功能
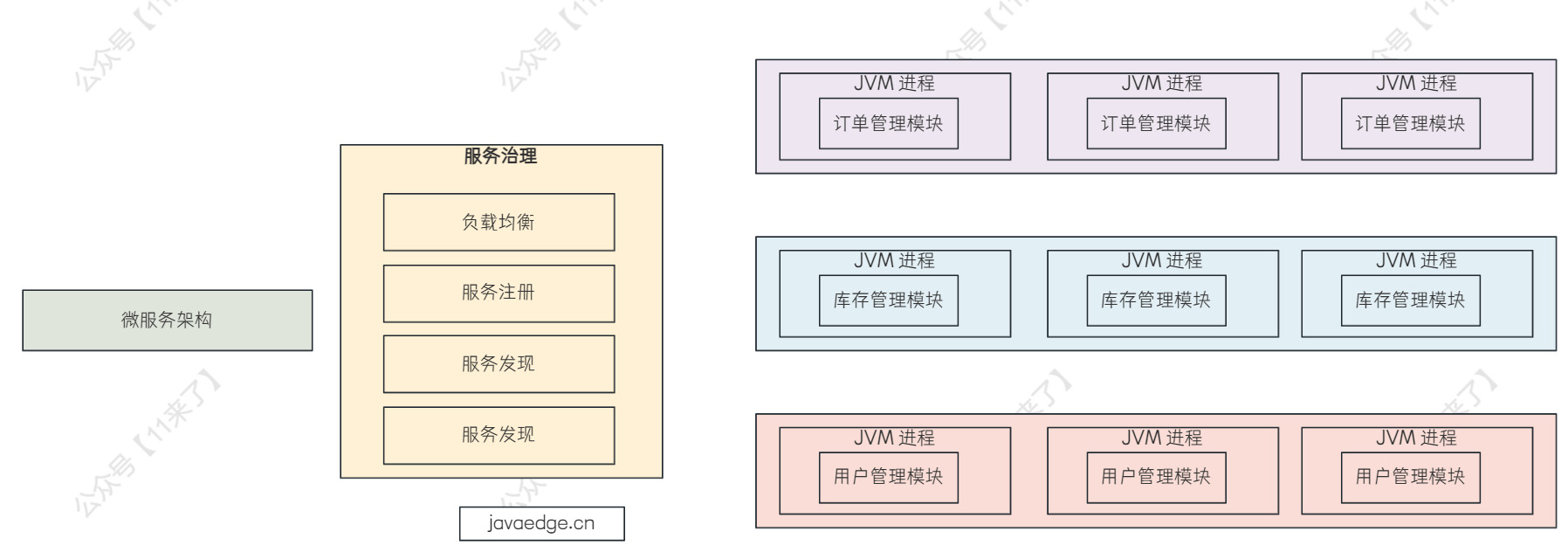
# 微服务架构
微服务架构是 SOA 架构的升级,其实现在微服务架构和 SOA 架构指的基本上就是一个东西了,只不过微服务架构是 SOA 架构做到极致的架构
通过微服务架构对多个应用进行编排、服务治理、服务注册、服务发现、负载均衡、限流、配置中心等操作
# Dubbo 的特性
这里说一下 Dubbo 最主要的特性,从这些特性中,就可以看出来我们为什么要选用 Dubbo,也可以将 Dubbo 和 Spring Cloud 进行对比,比如我们搭建一套微服务系统,出于什么考虑选用 Dubbo,又是出于什么考虑而选用 Spring Cloud 呢?
# Dubbo 主要的特性
- 负载均衡
- 服务注册、服务发现
- 高性能 RPC 调用
接下来针对 Dubbo 的讲解主要从这 3 个特性出发
# Dubbo、SpringCloud 技术选型
不过在说 Dubbo 特性之前,要先说一下面试相关的东西,因为我们在面试中,Dubbo 毕竟是分布式相关的东西,那么面试官可能问我们公司是如何进行技术选型的呢?为什么选择使用了 Dubbo 而不是 Spring Cloud 呢?
其实技术选型的东西,就是比较考察你对这两个框架特性的了解,那么像你如果选用了 Dubbo,那么就说一下 Spring Cloud 存在的缺点即可:
- 落地成本以及后期维护成本大
- 欠缺服务治理功能,尤其负载均衡、流量路由方面较弱
- 基于 HTTP 进行通信,性能不如 RPC 框架
而这些缺点,也正是 Dubbo 的优势所在,Dubbo 使用 RPC 进行通信,追求极致的性能,并且可以进行服务治理、负载均衡!
答出来他们各自的优势,那么再说一下由于公司开发人员对于 Dubbo 比较熟悉,因此最终选用 Dubbo 作为分布式框架
# Dubbo 工作原理
首先,在讲解 Dubbo 特性之前,先把 Dubbo 的工作原理给梳理一下,了解 Dubbo 底层是如何进行工作的
从整体上先把握,之后再深入到具体特性进行学习
Dubbo 主要分为 3 个部分:注册中心、服务消费者、服务提供者,Dubbo 工作的流程如下:
1、每个服务提供者都会去注册中心注册自己,包括自己的地址(ip+port)
2、服务消费者去消费时,从注册中心(Dubbo 使用 ZooKeeper 作为注册中心)中拉取服务列表
3、消费者会去为远程代理对象创建一个动态代理对象,通过动态代理来拦截方法的执行
4、在代理对象的拦截中,会去执行一系列的操作
4.1、负载均衡,选择一台机器进行通信
4.2、选择一种通信协议:Dubbo 提供了自定义的高性能 rpc 通信协议
4.3、将请求进行封装,并且序列化
4.4、通过网络通信框架,将远程调用请求传给 Dubbo 服务提供者
5、Dubbo 服务提供者收到后,也会进行一系列操作解析请求,最后调用本地服务,将执行结果返回给服务消费者

# Dubbo 的负载均衡策略
负载均衡策略就是当某个服务压力比较大的时候,这时候部署多个节点同时提供相同的服务
当服务消费者来消费的时候,可以从这多个节点中选择一个节点进行消费,这个选择的过程,就是 负载均衡
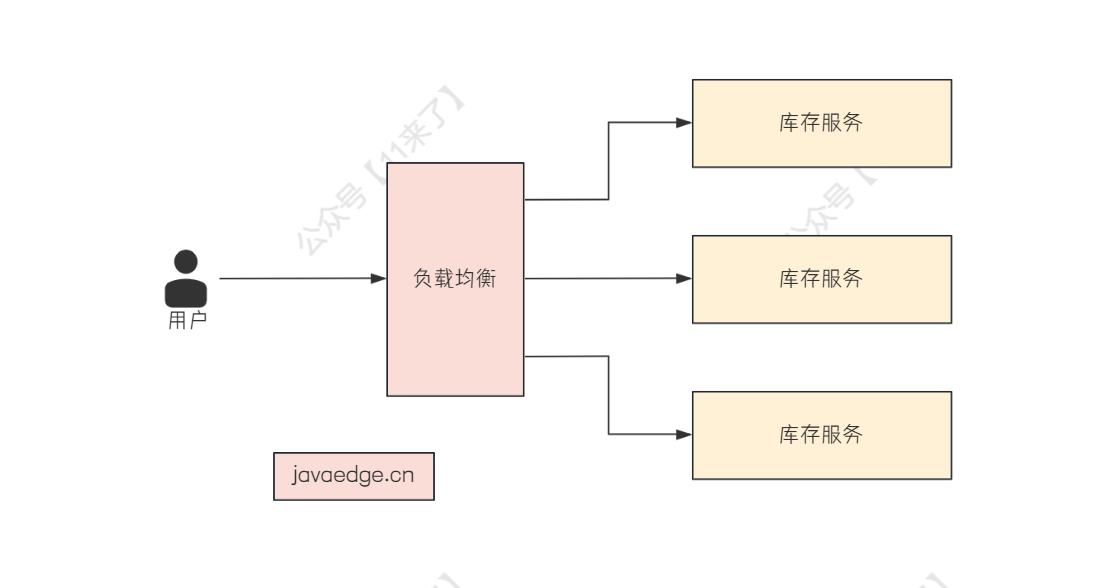
Dubbo 提供了多种负载均衡策略:
# Random LoadBalance
基于权重的随机负载均衡策略,为 Dubbo 的 默认策略
特点就是:根据每个服务的权重来设置它的随机概率,如下图

# RoundRobin LoadBalance
基于权重的轮询负载均衡策略,一般不使用该策略
因为轮询的话有一个比较致命的问题,如果其中有一台机器处理请求的速度比较慢,那么当一个请求被转发到很慢的机器上之后,很久都没有处理完,会导致其他请求也会被转发到这个机器上,导致该机器上堆积很多请求,更加处理不过来了
# LeastActive LoadBalance
最少活跃负载均衡策略,也就是看哪台机器上活跃的请求比较少
Dubbo 对活跃数的定义:当服务收到一个请求,活跃数 +1,当 Dubbo 处理完一个请求,活跃数 -1
Dubbo 就认为谁的活跃数越少,谁的处理速度就越快,性能也越好,这样的话,我就优先把请求给活跃数少的服务提供者处理
- 如果活跃的请求数量较少,说明该机器的性能是比较高的,有请求的话优先给该机器处理
- 如果活跃的请求数量较多,说明该机器的处理速度较慢,请求分给该机器的话可能会造成请求堆积
# ConsistentHash LoadBalance
一致性 Hash 负载均衡策略
可以保证相同参数的请求总是发到同一提供者,当某一台提供者机器宕机时,原本发往该提供者的请求,将基于虚拟节点平摊给其他提供者,这样就不会引起剧烈变动。
# 基于注解配置负载均衡策略
@Reference(loadbalance = "roundrobin")
HelloService helloService;
# Dubbo 的高性能 RPC 调用
Dubbo 的高性能 RPC 调用离不开它的序列化协议、通信协议,那么接下来就从这两方面来介绍
# Dubbo 的序列化协议
Dubbo 中支持多种序列化协议,在 Dubbo3.2 版本之前使用 Hessian2 作为默认的序列化方式,在 Dubbo3.2 版本之后使用 FastJSON2 作为默认的序列化方式
# Hessian、Hessian2
在 Dubbo3.2 版本之前使用
Hessian2作为默认的序列化方式
Hessian 序列化是一种支持动态类型、跨语言、基于对象传输的网络协议
Dubbo 中使用的 Hessian2 是阿里基于 Hessian 所做的升级版本
相比 Hessian1,Hessian2中增加了压缩编码,其序列化二进制流大小是 Java 序列化的50%,序列化耗时是 Java 序列化的30%,反序列化耗时是 Java 序列化的20%
相比于 Java 序列化,Hessian2 无论是从 序列化速度 还是 序列化后的体积 上都存在非常大的优势!
配置启用:
# application.yml (Spring Boot)
dubbo:
protocol:
serialization: hessian2
# FastJSON、FastJSON2
在 Dubbo3.2 版本之后使用
FastJSON2作为默认的序列化方式(FastJSON2 仅在 Dubbo > 3.1.0 版本支持)
FastJSON 是阿里开源的高性能 JSON 解析库
FastJSON 的特点就是 快 !
但是 FastJSON 中存在一些安全漏洞,因此 FastJSON2 对其进行升级,在 性能 和 安全性 上都有所提升!
FastJSON2 使用方式:
引入依赖:
引入依赖:
<dependencies>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.23</version>
</dependency>
</dependencies>
配置启用:
# application.yml (Spring Boot)
dubbo:
protocol:
serialization: fastjson2
# Protobuf
全称 Google Protocol Buffer,简称 Protobuf,由 Google 公司开发
Protocol Buffers 是一种轻便高效的 结构化 数据存储格式 (和 json、xml 文件类似),可以用于结构化数据串行化、或者说序列化,非常适合用于做 数据存储 或者 RPC 数据交换
Protocol 相比于 xml、json 来说,体积更小,解析更快
- 应用场景:
就比如现在有一个 Java 项目和 Go 项目之间要相互通信,两个模块之间对于数据的定义可能是不同的,并且 Java 语言和 Go 也是不兼容的,比如你要传输一个 User 类,在 Java 和 Go 中的定义肯定是不一样的
那么怎么来传输呢?
通过 Protobuf 来定义一个 User 数据对象(假设定义在 user.proto 文件),这个数据对象在 Java 和 Go 中都需要使用, 那么在 Java 中根据 user.proto 文件生成 Java 中的类对象,在 Go 中根据 user.proto 文件生成 Go 中的类对象 ,即可完成不同语言项目之间的通信
并且 Protobuf 在 序列化方面 也有很大的优势,可以很大程度上减小序列化后的体积,比如 proto 文件定义 User 类如下:
message User {
string uid = 1;
string username = 2;
}
那么一般在序列化传输数据的时候,需要传输数据的 key 和 value
而使用了 Protobuf 之后,在序列化的时候,不需要传输数据的 key 了,因为 key 已经在 proto 文件中定义了,只需要传输 value,因此 序列化后的数据体积减小很多!
- 配置启用:
# application.yml (Spring Boot)
dubbo:
protocol:
serialization: protobuf
# Avro
Avro 是一种远程过程调用和数据序列化框架,使用 JSON 来定义数据类型和通讯协议,使用压缩二进制格式来序列化数据,它主要用于Hadoop,是 Hadoop 持久化数据的一种序列化格式
# 其他序列化协议
还有其他很多序列化协议,如 FST、Gson、Kryo、MessagePack,这里就不一一介绍了
# Dubbo 支持的通信协议
Dubbo 框架提供了自定义的高性能 RPC 通信协议:
基于 TCP 的 Dubbo2 协议
基于 HTTP/2 的 Triple 协议
Dubbo 框架是不和任何通信协议绑定的,对通信协议的支持非常灵活,支持任意的第三方协议,如:gRPC、Thrift、REST、JsonRPC、Hessian2
# 通信协议是什么?网络通信框架?
通信协议 就是对通信传输的数据进行定义,表示每一位的含义是什么
这里再说一下 Dubbo 中使用的网络通信框架有以下三个:Netty、Mina、Grizzly
# HTTP/1.x 通信协议的缺点
我们知道,Dubbo 中的 RPC 通信是比较快的,因为 Dubbo 就是为了追求极致的 RPC 通信性能,在 Dubbo2 版本中有 Dubbo 协议,在 Dubbo3 版本推出了新的 Triple 协议
- 为什么 Dubbo 不选择 HTTP/1.x 协议呢?
HTTP/1.x 的优点就是它的 通用性 ,基本上所有的应用都可以接收 HTTP/1.x 请求并进行解析,但是缺点也很显然 速度慢 ,HTTP/1.x 协议速度慢主要是由两个方面:
第一方面:传输的无用数据很多,降低了数据传输效率
第二方面:Http/1.x 中,在一条 Socket 连接中,一次只能发送一个 HTTP 请求,然后必须等收到了响应之后,再发送下一个 HTTP 请求
如果不太理解的话,可以想象一下我们在 Java 中通过 HttpClient 发送 HTTP 请求的过程,是不是必须要
httpclient.get('请求url')发起请求,请求之后必须要拿到该 httpclient 的响应进行解析,而不可以连续发送两个请求如下:httpclient.get('请求1');
httpclient.get('请求2');
因此呢,针对以上的缺点,Dubbo 就推出了自己的通信协议
# Dubbo 协议
Dubbo2.x 中默认采用 Dubbo 协议,Dubbo 协议是采用 单一长连接 和 NIO 异步通讯 ,因此适合 小数据量高并发 的服务调用,不适合传送大数据量的服务(如视频)
Dubbo 协议是 基于 TCP 传输层协议的 RPC 通信协议,目的就是为了简化 RPC 调用的复杂性,提高通信效率
- Dubo 协议针对 HTTP/1.x 协议的优化
Dubbo 协议针对于 HTTP/1.x 协议的缺点,做出了优化,在 Dubbo 协议中尽量避免了传输无用的字节,并且还可以基于一个 Socket 连接同时发送多个 Dubbo 请求
- Dubbo 协议的组成如下

如上就是 Dubbo 协议的定义
- 前 16 bit 是 Magic,也就是魔数,标识这是 Dubbo2 协议,以及版本号,Magic 一般都是固定的:0xdabb
接下来每个 bit 或者多个 bit 组合起来有不同的含义,这里就不赘述了
通信协议就是对拿到的一系列 bit 数据进行语义解析,拿到远程服务想要传输过来的数据,了解通信协议到底是用来做什么的就可以了!
- 为什么 Dubbo 协议采用异步单一长连接?
因为现在的服务通常情况下是 服务提供者比较少,服务消费者比较多
通过单一长连接可以减少连接握手验证等操作,避免服务消费者过多时,直接将提供者给压垮
并且使用异步 IO、复用线程池,避免 C10K 问题(C10K 问题就是如何让服务器可以同时处理 10K 并发的 TCP 连接)
不过现在由于硬件水平的提升,C10K 基本上不是问题了,而逐渐演变成了 C100K 的问题
- 为什么 Dubbo 协议不建议传大数据包?
因为 Dubbo 协议采用单一长连接,如果每次请求的数据包大小为 500KB,假设网络为千兆网卡(1000Mb=128MB),根据测试经验发现每条连接最多只能压满 7MB,因此,理论上一个服务提供者需要 20 个服务消费者才能压满网卡
如果每次传输的数据包较大 ,假设为 500KB,那么单个消费者的最大 TPS(每秒事务处理数)为:128MB / 500KB = 262
单个消费调用者处理单个提供者的最大 TPS 为 7MB / 500KB = 14,也就是说每秒只可以调用 14 次提供者,次数较少
如果可以接受的话,可以考虑使用 Dubbo 协议传输大的数据包,否则, 网络带宽 将成为服务调用的性能瓶颈!

- Dubbo 协议所存在的缺点
Dubbo 协议目前所存在的缺点就是 通用性不足 ,如果其他应用想要调用 Dubbo 服务,就必须按照 Dubbo 协议的格式去发送请求,因此 Dubbo 协议在通用性上不如 HTTP 协议
# Triple 协议

- 为什么要推出 Triple 协议?
因为 Dubbo3 版本之前的 Dubbo 协议是 高性能 的 RPC 通信协议,保证了高性能,但是同时带来了 通用性差 的缺点,与 其他语言应用 以及 Spring Cloud 应用之间通信比较麻烦,因为使用了 Dubbo 协议,其他应用要和 Dubbo 框架通信必须遵循 Dubbo 协议的传输格式来进行通信,因此通用性比较差!
Triple 协议的推出就是为了解决这个问题,在提升了通用性的基础上,保证了性能
因此在 Dubbo3.x 版本推出了 基于 HTTP/2 并且 兼容 gRPC 的 Triple 协议,在 兼容性 和 性能 上都有所提升!
使用 Triple 协议之后,兼容 gRPC,支持 gRPC 的 Protobuf 序列化,Protobuf 就满足了跨平台、跨语言的需求,通用性较好
所带来最直观的感受就是,使用了 Triple
- Triple 协议是 Dubbo3 推出的主力协议,Triple 的含义就是三,表示是第三代,Triple 协议的特点:
1、Triple 协议是 Dubbo3 设计的基于 HTTP2 的 RPC 通信协议规范, 通用性 能有所提升,并且由于是基于 HTTP/2 的,因此 性能 上也要比 HTTP/1.x 要好一些
2、Triple 协议支持 流式调用
由于 Triple 协议是基于 HTTP/2 的,因此这里对 HTTP/2 协议再介绍一下
- 介绍一下 HTTP/2 协议
HTTP/2 协议是对 HTTP/1 协议的升级,HTTP/1 的缺点就是任何一个普通的 HTTP 请求,就算只发送很短的一个字符串,也要带上一个请求头,并且这个请求头比较大,占用多个字节,导致数据传输效率不高!
HTTP/1 协议的请求格式如下:
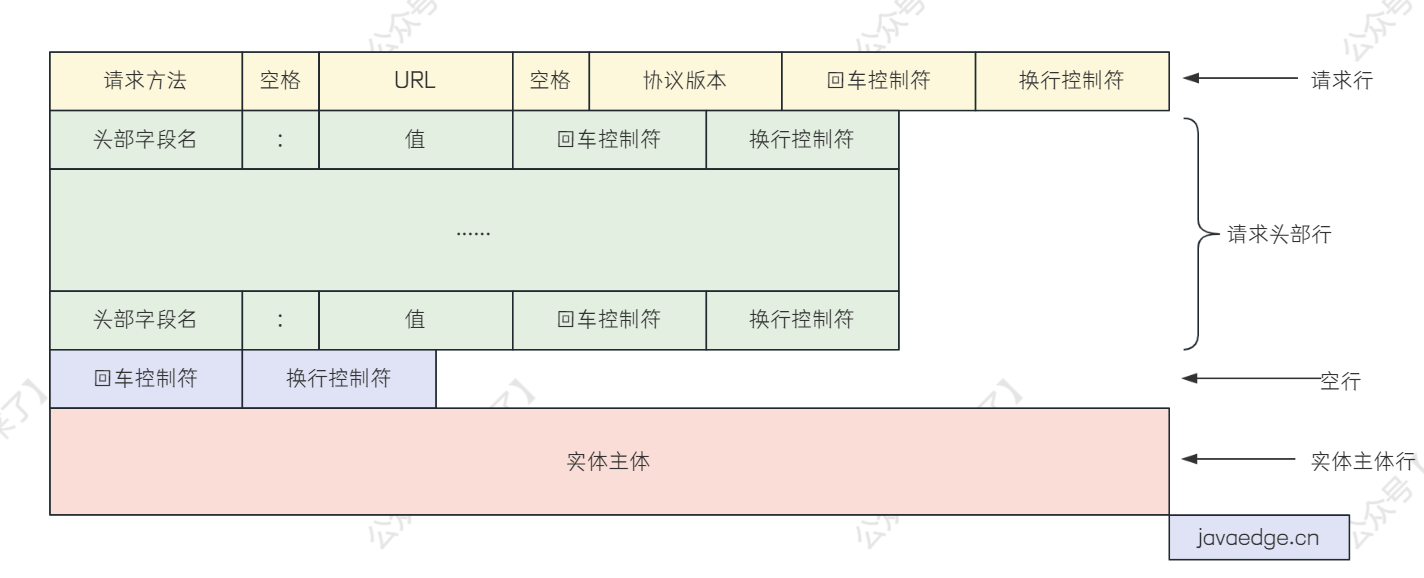
可以看到下边红色部分的实体也就是我们需要传输的数据
而上边都是请求头中的一些数据,像一些空格、换行符都是没有必要存在的字符,因此在 HTTP/2 中做了优化
- HTTP/2 中所做的优化:
1、HTTP/2 中 将请求和响应数据分割为更小的帧
2、并且 引入 HPACK 算法对标头压缩 ,减小标头大小
3、并且 支持 Stream :

1、帧长度:总共 24 bit,表示的最大数字为 2^24bit = 16M,所以一个帧最大为:9B(头部) + 16M(内容)
2、帧类型,8bit,分为数据帧和控制帧
2.1、数据帧分为:HEADERS 帧和 DATA 帧,用来传输请求头、请求体
2.2、控制帧分为:SETTINGS、PING、PRIORITY,用来进行管理
3、标志位,8bit,可以用来表示当前帧是请求的最后一帧,方便服务端解析
4、流标识符,32bit,表示 Stream ID,最高位保留不用
5、实际传输的数据,如果帧类型是 HEADERS,则这里存储的就是请求头,如果帧类型是 DATA,则这里存储的就是请求体
- HTTP/2 中的 Stream 流
HTTP/2 除了使用 HPACK 来压缩请求头的大小,他还支持 Stream,通过 Stream 可以极大程度上提升 HTTP/2 的并发度
常用的 HTTP 协议的版本包含了 HTTP/1.1、HTTP/2.0、HTTP/3.0,不过目前常见的就是 HTTP/1.1 和 HTTP/2.0(通过 F12 控制台可以看到协议版本)
HTTP1.0 中为 短连接 ,每次通信都要建立一次 TCP 连接,开销很大
因此在 HTTP/1.1 中优化为 长连接 ,通过管道机制在一个 TCP 连接中,客户端可以发送多个请求,服务端可能会按顺序处理请求,因此会导致后续的请求被阻塞
因此,在 HTTP/2 中,可以在一个 TCP 连接上维护多个 Stream,这样就可以并发的给服务端发送多个帧了
比如说,客户端要给服务端发送 3 个请求,如果只建立一个 Stream,那么每次只能发送 1 个请求,之后等拿到了响应结果之后,再发送第 2 个请求
如果建立了三个 Stream,客户端就可以使用三个线程,同时将 3 个请求通过这三个 Stream 发送给服务端去
- 在 HTTP/2 中客户端发送请求的流程为:
1、新建 TCP 连接
2、新建一个 Stream:生成一个新的 StreamID,生成一个控制帧,帧里记录了生成的 StreamID,通过 TCP 连接发送出去
3、发送请求的请求头:生成要发送请求的 HEADERS 帧,使用 ASCII 编码,HPACK 进行压缩,将压缩后的数据放到帧的 Payload 区域,记录 StreamID,通过 TCP 连接发送出去
4、发送请求的请求体:将要发送请求的请求体中的数据按照指定的压缩算法(请求中指定的压缩算法,比如 gzip)进行压缩,使用压缩后的数据生成生成 DATA 帧,记录 StreamID,通过 TCP 连接发送出去
- 在 HTTP/2 中服务端接收请求的流程为:
1、服务端从 TCP 连接中不断接受帧
2、当接收到控制帧,表示客户端要和服务端建立一个 Stream,服务端记录下来 StreamID,在 Dubbo3 中会生成一个 ServerStreamObserver 对象
3、当接收到 HEADERS 帧,取出 StreamID,找到对应的 ServerStreamObserver 对象,解压之后得到请求头,将请求头信息存入该 ServerStreamObserver 对象中
4、当接收到 DATA 帧,取出 StreamID,找到对应的 ServerStreamObserver 对象,将请求体解压之后,按照业务逻辑处理请求体
5、处理完之后,将结果生成 HEADERS 帧和 DATA 帧发送给客户端
- 基于 HTTP/2 的数据帧机制,Triple 协议支持 UNARY、SERVER_STREAM、BI_STREAM 三种模式
1、UNARY :最普通的,服务端接受完所有请求帧之后,才处理数据
2、SERVER_STREAM :服务端流式调用,服务端接收完所有请求帧之后,才处理数据,但是可以多次发送响应 DATA 帧给客户端
3、BI_STREAM :双端流式调用,客户端可以多次发送 DATA 帧,服务端不断接收 DATA 帧进行处理,并且将处理结果作为响应 DATA 帧多次发送给客户端,客户端收到之后,也会立即进行处理(也就是客户端和服务端都可以不断接收 DATA 帧,进行处理)
- 接下来说一下 Triple 协议支持的流式调用(就是基于 HTTP/2 的帧实现)
流式调用是在 Dubbo3.x 版本新增的,如果我们需要使用流式调用的话,需要自己定义对应的方法
首先引入一下需要使用的类 StreamObserver 的依赖:
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-common</artifactId>
<version>3.0.7</version>
</dependency>
并且引入一下 Triple 协议的依赖
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-rpc-Triple</artifactId>
<version>3.0.7</version>
</dependency>
比如说,我们在 UserService 接口中定义了流式调用:
public interface UserService {
String hello(String name);
// 服务端流式调用
default void helloServerStream(String name, StreamObserver<String> response) {}
// 双端流式调用
default StreamObserver<String> helloStream(StreamObserver<String> response) {return response;}
}
服务端流式调用 的话,返回值需要为 void ,参数中需要有 StreamObserver<String> ,
服务端对应接口实现方法为:
// UserServiceImpl implements UserService
@Override
public void sayHelloServerStream(String name, StreamObserver<String> response) {
response.onNext(name + " hello");
response.onNext(name + " world");
response.onCompleted();
}
客户端调用者代码为:
userService.helloServerStream("11", new StreamObserver<String>(){
@Override
public void onNext(String data) {
// 服务端返回的数据
}
@Override
public void onError(Throwable throwable) {}
@Override
public void onCompleted(String data) {
// 服务端执行完毕
}
})
双端流式调用 的话,返回值和参数都要有 StreamObserver
服务端对应接口实现方法为:
// UserServiceImpl implements UserService
@Override
public StreamObserver<String> sayHelloStream(StreamObserver<String> response) {
return new StreamObserver<String>() {
@Override
public void onNext(String data) {
// 接收客户端发送的数据
response.onNext("result:" + data);
}
@Override
public void onError(Throwable throwable) {}
@Override
public void onCompleted(String data) {
// 服务端执行完毕
}
}
}
客户端调用者代码为:
StreamObserver<String> streamObserver = userService.sayHelloStream(new StreamObserver<String>() {
@Override
public void onNext(String data) {
System.out.println("接收到响应数据:"+ data);
}
@Override
public void onError(Throwable throwable) {}
@Override
public void onCompleted(String data) {
// 接收数据完毕
}
})
// 客户端发送数据
streamObserver.onNext("第一次发送数据");
streamObserver.onNext("第二次发送数据");
streamObserver.onCompleted();
- 接下来总结一下 Triple 协议中的流式调用的优点以及应用场景
首先,流式调用的优点就是 客户端可以多次向服务端发送消息,并且服务端也可以多次接收 ,通过 onNext 方法多次发送,比如用户在处理完一部分数据之后,将这一部分数据发送给服务端,之后再去处理下一部分数据,避免了一次发送很多数据的情况
流式调用的应用场景为:接口需要发送大量数据,这些数据通过一个 RPC 请求无法发送完毕,需要分批发送,并且需要保证发送的有序性
# Dubbo 的服务注册中应用级注册优化
# Dubbo 的注册中心
Dubbo 支持很多种注册中心,支持的主流注册中心包括:ZooKeeper、Nacos、Redis
Dubbo 需要引入注册中心依赖,并且配置注册中心地址,这里以 ZooKeeper 注册中心为例介绍如何使用
引入依赖:
其中引入的 dubbo-dependencies-zookeeper 将自动为应用增加 Zookeeper 相关客户端的依赖,减少用户使用 Zookeeper 成本,如使用中遇到版本兼容问题,用户也可以不使用 dubbo-dependencies-zookeeper,而是自行添加 Curator、Zookeeper Client 等依赖。
<properties>
<dubbo.version>3.0.8</dubbo.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>${dubbo.version}</version>
</dependency>
<!-- This dependency helps to introduce Curator and Zookeeper dependencies that are necessary for Dubbo to work with zookeeper as transitive dependencies -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper</artifactId>
<version>${dubbo.version}</version>
<type>pom</type>
</dependency>
</dependencies>
要特别注意 ZooKeeper 版本和 Dubbo 版本之间的适配兼容,如下:
| Zookeeper Server 版本 | Dubbo 版本 | Dubbo Zookeeper 依赖包 | 说明 |
|---|---|---|---|
| 3.4.x 及以下 | 3.0.x 及以上 | dubbo-dependencies-zookeeper | 传递依赖 Curator 4.x 、Zookeeper 3.4.x |
| 3.5.x 及以上 | 3.0.x 及以上 | dubbo-dependencies-zookeeper-curator5 | 传递依赖 Curator 5.x 、Zookeeper 3.7.x |
| 3.4.x 及以上 | 2.7.x 及以下 | dubbo-dependencies-zookeeper | 传递依赖 Curator 4.x 、Zookeeper 3.4.x |
| 3.5.x 及以上 | 2.7.x 及以下 | 无 | 须自行添加 Curator、Zookeeper 等相关客户端依赖 |
配置启用:
# application.yml
dubbo
registry
address: zookeeper://localhost:2181
# Dubbo 支持多注册中心
Dubbo 在默认情况下:
- Service 服务会
注册到所有的全局默认的注册中心去 - 会将 Reference 服务去
对所有的全局默认注册中心进行订阅
多注册中心配置如下:
# application.yml (Spring Boot)
dubbo
registries
beijingRegistry
address: zookeeper://localhost:2181
shanghaiRegistry
address: zookeeper://localhost:2182
如果不进行 默认项 的配置,则该注册中心是默认的,上边两个注册中心没有指定默认项(默认 default = true),那么对于没有指定注册中心 id 的服务将会分别注册到上边的两个注册中心去
也可以指定该注册中心不是默认的:
# application.yml (Spring Boot)
dubbo
registries
beijingRegistry
address: zookeeper://localhost:2181
default: true
shanghaiRegistry
address: zookeeper://localhost:2182
# 非默认
default: false
可以显式指定服务要注册的注册中心 id:
@DubboService(registry = {"beijingRegistry"})
public class DemoServiceImpl implements DemoService {}
@DubboService(registry = {"shanghaiRegistry"})
public class HelloServiceImpl implements HelloService {}
# Dubbo 的服务注册
Dubbo3 之前一直是接口级注册,Dubbo3 之后推出了应用级注册,接下来说一下为什么要换为应用级注册!
- Dubbo 中
接口级注册的缺点
在 Dubbo3.0 之前的服务注册使用的是 接口级注册 ,这种注册方式对于注册中心的压力是非常大的,比如一个应用有 3 个实例对象,那么在注册中心上注册的格式如下:
tri://192.168.65.61:20880/com.zqy.UserService
tri://192.168.65.62:20880/com.zqy.UserService
tri://192.168.65.63:20880/com.zqy.UserService
tri://192.168.65.61:20880/com.zqy.ProductService
tri://192.168.65.62:20880/com.zqy.ProductService
tri://192.168.65.63:20880/com.zqy.ProductService
那么当一个 服务提供者 上提供很多接口的时候,就需要在注册中心上 注册大量的节点 ,导致注册中心压力比较大,并且如果提供者新增接口的话,消费者也需要去修改本地缓存的注册中心节点,也会比较耗费性能
简单一句话概括就是,在 Dubbo3.0 之前,接口级注册要注册的信息太多了!
而在 SpringCloud 中,和 Dubbo 的 注册粒度不同 ,SpringCloud 是进行应用级的注册,因此下边无论多少个接口,都不影响 SpringCloud 的注册,注册的格式如下:
应用名:
192.168.65.61:8080
192.168.65.62:8080
192.168.65.63:8080
- 因此,Dubbo3 中改成了
应用级服务注册!
简单来说,应用及服务注册带来的好处就是,大大减少了注册的数据!但同时给服务消费者寻找服务带来了复杂性!
在 Dubbo3.0 中,默认情况下,会同时进行 接口级注册 和 应用级注册 ,这是为了兼容!因为当服务提供者升级到 3.0 之后,可能有些服务消费者还处于 Dubbo2.7 的版本,并没有应用级注册的能力!
如果确认所有的消费者都已经成功迁移 Dubbo3.0 的话,就可以在 yml 文件中配置只进行应用级注册:
# application.yml
dubbo:
application:
name: dubbo-app
register-mode: instance # 只进行应用级注册
# register-mode: interface # 只进行接口级注册
# register-mode: all # 默认,同时进行接口级、应用级注册,为了兼容
- Dubbo 的服务提供者如何进行
应用级注册
我们先来思考一下,服务消费者如果需要使用服务,需要哪些信息?
服务消费者本身是只有接口相关的信息的,比如 com.zqy.hello.UserService 这个接口信息,那么消费者就要通过这个接口信息来找到提供者中对应的服务
因此提供者必须将接口 -> 服务的信息给暴露出来
1、首先,服务提供者进行应用级注册,在注册中心上的数据为:
# 应用名 -> 应用地址的映射
dubbo-provider: 192.168.65.61:20880
2、此时注册中心上只有应用地址的 ip:port 信息,那么服务消费者还不知道他所使用的接口对应的应用是哪一个
因此服务提供者还存储了 接口名 -> 应用名 的映射:
# 接口名和应用名的映射
com.zqy.dubbo.service.UserService: dubbo-provider
那么此时,消费者就可以根据接口名获取到对应的应用地址了
3、但是消费者怎样去知道这个应用中是否有自己需要的服务呢?
因此服务提供者将自己应用中的所有 Dubbo 服务信息都给存储了 MetaDataInfo 中去,并且在服务启动之后,会暴露一个 应用元数据服务 ,这是 Dubbo 内置的一个服务
那么消费者就可以调用这个 应用元数据服务 来获取该应用中的 Dubbo 服务信息了
这样一来呢,Dubbo 中服务的具体信息就不在注册中心上了,而是在元数据中进行存储,避免了注册中心压力过大!
- 再说一下 Dubbo 的应用元数据服务
上边说到了 Dubbo 服务提供者会暴露一个 应用元数据 服务
这个 应用元数据服务 其实就是用来减轻注册中心压力的,之前使用接口级注册的时候,会将服务的信息都给注册到注册中心去,导致注册中心压力很大
现在会将服务的信息给存储到 应用元数据服务 中去,来供消费者查询服务的具体信息
那么服务提供者需要将服务的元数据信息给暴露出去,让服务消费者可以查询到,暴露的方式有两种,可以通过 metadata-type 来配置:
# application.yaml
dubbo:
application:
name: dubbo-provider
metadata-type: local # 或 remote
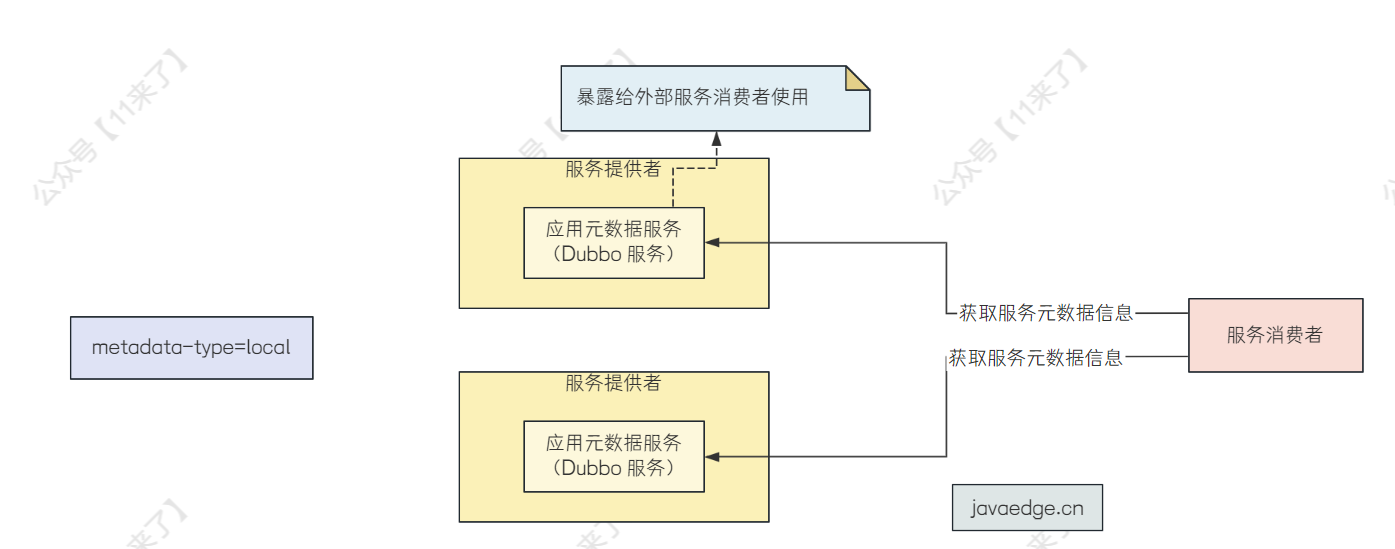
- local :默认情况,如果是 local 的话,会将服务的元数据给放在服务提供者的本地,之后暴露
应用元数据服务来供消费者进行查询,也就是上边我们说的情况
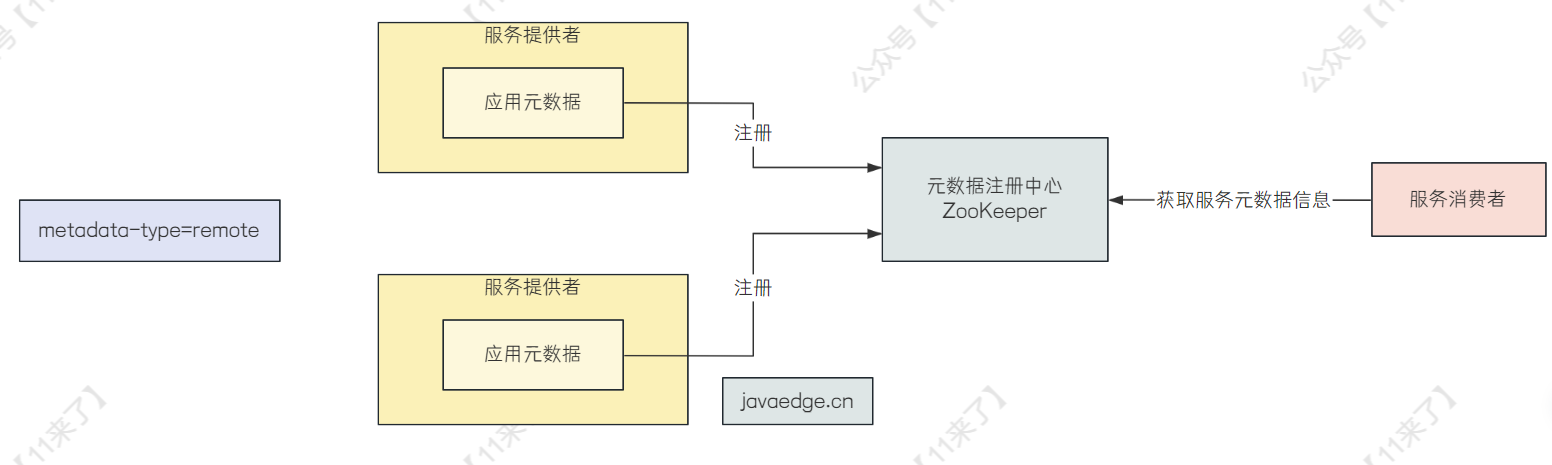
- remote :如果是 remote 的话,表示会将服务的元数据放在远程主机,则提供者不会暴露
应用元数据服务,而是通过将服务的元数据信息存储在远程的元数据中心中去,元数据中心可以是 ZooKeeper 也可以是 Nacos,那么消费者需要查询服务的信息时,去元数据中心中查询即可!
这两种暴露方式在性能上有什么区别呢?
- 如果是暴露
应用元数据服务的话,每一个服务提供者都会暴露一个应用元数据服务,因此这个元数据服务是比较分散的,一般不会出现单点压力较大的情况 - 如果是使用
元数据中心的话,当整个微服务集群压力比较大的时候,会导致这个元数据中心压力也大
因此,综上看来,暴露 应用元数据服务 这一种方式比较好,而 Dubbo 中默认的也就是这一种方式
那么,应用级注册就已经说完了,为什么需要应用级注册呢?
就是为了减轻注册中心的压力,至于具体非常细的细节可以不用抠的非常认真,知道它原理是什么,用于解决什么问题的即可
# Dubbo 的 SPI 机制
# SPI 机制原理介绍
在 Dubbo 中 SPI 是一个非常重要的模块,基于 SPI 可以很容易的进行扩展,可以 很灵活的替换接口的实现类,通过 SPI 可以在运行期间动态的寻找具体的实现类!
并且 Dubbo 的 SPI 还实现了自己的 IOC 和 AOP!
其实 SPI 的原理很简单,就是我们定义一个接口 UserService,在定义一个配置文件(假设为文件 a),此时假设 UserService 有两个实现类:UserServiceImpl1、UserServiceImpl2,用户根据自己的需求在文件 a 中指定需要加载哪一个实现类,如下:
# 指定接口对应实现类的全限定类名
com.example.hello.UserService=com.example.hello.impl.UserServiceImpl1

像 Java 中也提供了 SPI 机制,但是 Dubbo 中并没有使用 Java 提供的 SPI ,而是 基于 Java 提供的 SPI 实现了一套功能更强的 SPI 机制!
Dubbo 中通过 SPI 指定实现类的配置文件放在 META-INF/dubbo 路径下(一般 SPI 机制的配置文件都在 META-INF 目录下)
# Dubbo 为什么不用 JDK 中的 SPI 而是自己实现一套呢?
其实很容易想到,为什么不用呢,就是因为太弱了!
JDK 提供的 SPI 机制不满足 Dubbo 的需求,因此 Dubbo 才要开发自己的 SPI 机制
回答的思路就是,先说 JDK 的 SPI 哪里不满足呢?那就是列出 JDK 的 SPI 缺点
之后再说在 Dubbo 中的针对它的哪些需求做了哪些的改进
这些 JDK 的 SPI 缺点、Dubbo SPI 优点,网上一查一大堆,这里我也给列一下:
- JDK SPI 的缺点:
JDK 的 SPI 机制在查找实现类的时候,由于配置文件根根据接口的全限定类名命名的,需要先遍历 META-INF/services/ 目录下的所有配置文件,找到对应的配置文件,再将配置文件中的全部实现类都取出来,进行实例化操作
因此呢,它的缺点就是无法按需加载实现类,导致出现资源浪费,并且指定了配置目录 META-INF/services/ ,不是很灵活
- Dubbo SPI 的优点:
Dubbo 的 SPI 对配置文件的目录规定了多个,各自的职责不同:
- META-INF/services/ 目录:该目录下的 SPI 配置文件是为了用来兼容 Java SPI 。
- META-INF/dubbo/ 目录:该目录存放用户自定义的 SPI 配置文件。
- META-INF/dubbo/internal/ 目录:该目录存放 Dubbo 内部使用的 SPI 配置文件。
Dubbo 的 SPI 代码中还实现了 IOC 和 AOP,可以对扩展的实现类进行依赖注入,以及 AOP 拦截,也就是方法增强
并且 Dubbo 中的 SPI 是通过 K-V 方式配置的,因此可以 按需加载实现类 ,优化了 JDK SPI 的缺点
从这几个点呢,可以看出 Dubbo 的 SPI 机制是非常灵活的,可以针对实现类做出拦截扩展操作,并且性能也不错,按需加载,不会出现资源浪费
# Dubbo 中 SPI 使用
先说一下 Dubbo 中的 SPI 使用:
- 第一步:配置文件如下(配置文件在 META-INF/dubbo 目录下,Dubbo 会自动去扫描该目录中的配置文件):
userServiceImpl1 = com.example.hello.impl.UserServiceImpl1
userServiceImpl2 = com.example.hello.impl.UserServiceImpl2
- 第二步:SPI 接口:
@SPI("userServiceImpl2") // 可以指定默认的 SPI 实现类为 userServiceImpl2
public interface UserService {
void sayHello();
}
- 第三步:加载实现类
public class DubboSPITest {
@Test
public void sayHello() throws Exception {
ExtensionLoader<Robot> extensionLoader =
ExtensionLoader.getExtensionLoader(UserService.class);
UserService userServiceImpl1 = extensionLoader.getExtension("userServiceImpl1");
userServiceImpl1.sayHello();
UserService userServiceImpl2 = extensionLoader.getExtension("userServiceImpl2");
userServiceImpl2.sayHello();
UserService defaultUserServiceImpl = extensionLoader.getDefaultExtension();
defaultUserServiceImpl.sayHello();
}
}
Dubbo 的 SPI 实现中,包含了 IOC 和 AOP,接下来说一下 Dubbo 如何实现了 IOC 和 AOP
# Dubbo 的 IOC?
Dubbo 通过 SPI 来创建接口的扩展实现类时,那么如果这个实现类中有其他扩展点的依赖的话,Dubbo 会自动将这些依赖注入到这个扩展实现类中
Dubbo 中的 IOC 和 AOP 的代码都是在 ExtensionLoader # createExtension() 方法中(为了代码简洁性,省略一些无关代码):
@SuppressWarnings("unchecked")
private T createExtension(String name, boolean wrap) {
Class<?> clazz = getExtensionClasses().get(name);
try {
T instance = (T) extensionInstances.get(clazz);
if (instance == null) {
extensionInstances.putIfAbsent(clazz, createExtensionInstance(clazz));
instance = (T) extensionInstances.get(clazz);
instance = postProcessBeforeInitialization(instance, name);
// IOC 代码
injectExtension(instance);
instance = postProcessAfterInitialization(instance, name);
}
}
}
SPI 中 IOC 的核心方法就是 injectExtension():
private T injectExtension(T instance) {
try {
// 使用反射遍历所有的方法
for (Method method : instance.getClass().getMethods()) {
// 如果不是 setter 方法就跳过
if (!isSetter(method)) {
continue;
}
// 获取 setter 方法的参数
Class<?> pt = method.getParameterTypes()[0];
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
// 获取 setter 中需要设置的属性,比如 setUserName,该方法就是取出来 set 后边的名称 String property = "UserName"
String property = getSetterProperty(method);
// 寻找需要注入的属性
Object object = injector.getInstance(pt, property);
if (object != null) {
// 通过反射进行注入
method.invoke(instance, object);
}
}
}
}
return instance;
}
Dubbo 的 IOC 是 通过 setter 方法注入依赖 的:
- 第一步:通过反射获取实例的所有方法,找到 setter 方法
- 第二步:通过 ObjectFactory(这里的 ObjectFactory 其实是 AdaptiveExtensionFactory 实例,这个实例就是 Dubbo 中的扩展工厂) 获取依赖对象(也就是需要注入的对象),来进行 setter 属性注入的!
# Dubbo 的 AOP?
Dubbo 的 AOP 其实就是通过 装饰者模式 来实现的,在包装类上进行增强
Dubbo 的 IOC 和 AOP 都在 org.apache.dubbo.common.extension.ExtensionLoader # createExtension() 这个方法中,AOP 相关的源码如下:
private T createExtension(String name, boolean wrap) {
try {
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
// 拿到缓存中的包装类 WrapperClass
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
// 将所有的包装类按照 order 进行排序,order 比较小的包装类在较外层
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
// 通过 for 循环,进行 Wrapper 的包装,进行包装类的层层嵌套
// 比如有三个 Wrapper 类,AWrapper、BWrapper、CWrapper
// 那么经过包装之后也就是:AWrapper(BWrapper(CWrapper(被包装类)))
// 执行流程:先执行 AWrapper 包装的方法,再执行 BWrapper 包装的方法,再执行 CWrapper 包装的方法,再执行被包装类的方法
for (Class<?> wrapperClass : wrapperClassesList) {
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
boolean match = (wrapper == null)
|| ((ArrayUtils.isEmpty(wrapper.matches())
|| ArrayUtils.contains(wrapper.matches(), name))
&& !ArrayUtils.contains(wrapper.mismatches(), name));
if (match) {
// 先调用包装类的构造方法创建包装类,有 3 个包装类,因此是 3 次 for 循环,外层包装类包裹了里边的包装类
// 比如第一次就是 instance = CWrapper(被包装类)
// 第二次就是 instance = BWrapper(CWrapper(被包装类))
// 第三次就是 instance = AWrapper(BWrapper(CWrapper(被包装类)))
instance = injectExtension(
(T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
}
}
return instance;
}
}
}
上边的方法主要是扫描 wrapperClassesList(包装类),而这个包装类集合其实就是 cachedWrapperClasses
cachedWrapperClasses 是 Dubbo 在扫描类(执行 loadClass)的时候,会去判断这个类是不是包装类,如果是包装类,就加入到 cachedWrapperClasses 中
通过 for 循环进行包装类的包装,下边举一个 SPI AOP 的例子,也就是通过 Wrapper 包装实现 Dubbo 中的 AOP 机制 :
// Person 接口
@SPI("person")
public interface Person {
void hello();
}
// SPI 接口实现类
public class Student implements Person {
public void hello() {
System.out.println("I am student");
}
}
// Wrapper 包装类
public class StudentWrapper implements Person {
private Person person;
public StudentWrapper(Person person) {
this.person = person;
}
public void hello() {
System.out.println("before");
person.hello();
System.out.println("after");
}
}
// Dubbo 配置文件(配置文件名与 Person 接口保持一致):resources/META-INF/dubbo/com.zqy.hello.Person
student=com.zqy.hello.impl.Student
filter=com.zqy.hello.wrapper.StudentWrapper
// 运行测试类即可看到包装类输出效果
public static void main(String[] args) {
ExtensionLoader<Person> loader = ExtensionLoader.getExtensionLoader(Person.class);
Person studesnt = loader.getExtension("student");
studesnt.hello();
}
# Dubbo 的 Filter 机制
Dubbo 中 Filter 机制也是一个其中的核心功能
Filter 机制就是提供一个拦截器的功能
# Filter 的实现
自定义 Filter 需要扩展 Filter 接口,默认 Filter 不开启,需要使用 @Activate 注解完成默认开启
// 自定义服务提供者端 Filter
// 通过 @Activate 激活 Filter,指定 group 为 provider 或 consumer,表示是消费端的 Filter 还是提供者端的 Filter
@Activate(group = "provider")
public class MyProviderFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
Class<?> interFace = invoket.getInterface();
String simpleName = interFace.getSimpleName();
String serviceName = interFace.getServiceName();
String methodName = interFace.getMethodName();
System.out.println(url);
System.out.println(simpleName);
System.out.println(serviceName);
System.out.println(methodName);
// Filter 链继续向下执行
Result invoke = invoker.invoke(invocation);
return invoke;
}
}
// 在配置文件中配置 Filter,配置文件名指定为 Filter 接口的全限定类名:META-INF/dubbo/org.apache.dubbo.rpc.Filter
myProviderFilter=com.zqy.hello.MyProviderFilter
# Filter 在链路追踪中的应用
一些生产环境中使用的链路追踪组件,都是基于 Filter 实现的:
Zipkin - 全链路追踪,使用 Filter 实现
Zipkin 对 Dubbo 的支持是构建在 Dubbo 的 filter 扩展机制上的,有兴趣的读者可以通过 https://github.com/openzipkin/brave/blob/master/instrumentation/dubbo/src/main/java/brave/dubbo/TracingFilter.java 了解其实现细节
小米的开源监控系统open-falcon
# Dubbo 相关面试题
# ZooKeeper 宕机后,Dubbo 服务还能使用吗?
在实际生产中,假如 ZooKeeper 注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,通过本地缓存可以拿到提供者的地址信息,仍然可以通信,这只是 Dubbo 健壮性的一种体现。
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。所以,我们可以完全可以绕过注册中心——采用 dubbo 直连 ,即在服务消费方配置服务提供方的位置信息。
# Dubbo 怎么实现动态感知服务下线?
一般来说,服务订阅有两种方式:
- Pull 模式:客户端定时去注册中心中拉去最新配置
- Push 模式:注册中心主动将配置推送给客户端
Dubbo 动态感知服务下线使用了 ZooKeeper 中的节点监听机制,流程如下:
1、消费者在第一次订阅时,会去 ZooKeeper 对应节点下全量拉取所有的服务数据,并且在订阅的节点注册一个 Watcher
2、一旦节点下发生数据变化,ZooKeeper 将会发送事件通知给客户端
3、客户端收到通知后,会重新去拉去最新数据,并且重新注册 Watcher
ZooKeeper 提供了 心跳检测 功能,它会定时向各个服务提供者发送一个请求,如果长期没有响应,服务中心就 认为该服务提供者已经挂了 ,并将其剔除
# Dubbo 的负载均衡策略
随机(默认策略):根据权重随机调用
轮询:一个一个调用,不建议使用
- 如果其中有一台机器处理请求的速度比较慢,那么当一个请求被转发到很慢的机器上之后,很久都没有处理完,会导致其他请求也会被转发到这个机器上,导致该机器上堆积很多请求,更加处理不过来了
最少活跃数:根据机器上活跃的请求数分配请求,Dubbo 认为活跃请求数少的机器,性能就高
一致性 Hash:相同参数的请求会发送给同一台机器
# Dubbo 容错策略
Dubbo 作为 RPC 框架,容错也算是其中比较核心的功能了
在网络通信中有很多不确定的因素,比如网络延迟、网络中断等,此类情况出现的话会造成当前这次请求出现失败。当服务通信出现这类问题时,需要采取一定措施来应对
Dubbo 提供了 容错机制 来处理这类错误
在集群调用失败时,Dubbo 提供了多种容错方案(默认方案是Failover 重试):
1、Failover Cluster :这是 默认的容错模式 ,当调用服务时失败,会自动切换到其他服务器进行重试,重试会带来更长的延迟并且会对下游服务造成更大的压力,可以通过配置 retries="2"来调整重试次数(不包含第一次),这种机制通常用于读操作 (相关代码在 FailoverClusterInvoker # invoke() )
2、Failfast Cluster :快速失败,只发起一次调用,如果调用服务失败立即报错。通常用于非幂等性的 写操作 以及 事务 ,例如新增记录等
3、Failsafe Cluster :失败安全,当消费者调用服务出现异常时,直接忽略异常。这种模式通常用于写入审计日志等操作
4、Failback Cluster :失败自动恢复,当调用服务失败,后台记录失败请求并定时重发。通常用于消息通知操作
5、Forking Cluster :并行调用多个服务器,只要一个成功就返回,通常用于实时性要求较高的操作 ,但比较浪费服务资源,通过 forks="2" 设置最大并行数
6、Broadcast Cluster :广播调用所有提供者,逐个调用,任意一台报错则就算调用失败,通常用于通知所有提供者更新缓存等本地资源
上边六种容错策略不用全部记住,前两种比较重要着重记一下,其余的可以从设计的思路来理解
像接口调用失败,无非就是重试,或者直接返回失败,或者将错误给记录下来,可能只是当前网络不稳定而已,再定一个新的时间重新发送调用请求
# Dubbo 源码中的一些小技巧
# 快速判断端口是否被占用
Dubbo 在暴露应用元数据服务的时候,有可能服务默认端口会被占用,那么就需要判断默认端口是否被占用,如果被占用了就换一个端口
那么判断端口占用其实就是在这个端口上创建一个 Socket 连接,如果失败抛出异常了,说明这个端口被占用:
int port = 20880;
while (true) {
try (ServerSocket isBusy = new ServerSocket(port)) {
// ...
} catch (IOException e) {
// 抛出异常说明端口被占用,再试试下一个端口
port += 1;
continue;
}
}
# transient 关键字使用
Dubbo 中服务暴露的时候需要向注册中心放一些信息,通过 Netty 将数据信息传输到注册中心进行注册
在 Java 中一般是使用一个类来存放这些信息的,但是有些字段只是在 Dubbo 内部使用,而不需要放到注册中心中去,这时可以使用 transient 关键里来不对这些字段进行序列化
要将数据传给注册中心都是需要对数据进行序列化的,我们就可以在序列化的时候通过 transient 关键字跳过那些不需要注册的数据
public class User {
private String name;
// 不对 password 进行序列化
private transient String password;
}
因此也就不会通过 Netty 传输到注册中心了
# 学会Dubbo服务注册、调用流程,再也不怕面试问Dubbo了!

这里我们通过 画图 的方式来学习 Dubbo 服务注册、服务调用的底层原理,不会涉及源码,因为源码中涉及到比较多的细节,可能会陷入进去,并且对于这些源码的细节我们也根本记不住,能记住的只是他底层调用的一个流程以及实现的方式, 因此学习它的原理流程是很重要的!
因此决定以画图的方式讲解 Dubbo 服务注册、Dubbo 服务调用的原理,在面试中就可以按照流程图的方式给面试官来讲解整体的实现原理,对于应届生校招来说应该是可以的,相关的 Dubbo 一些源码实现方式之后会以源码的方式来讲解!
# Dubbo 服务注册
# 什么是 Dubbo 服务注册?
首先说一下什么是 Dubbo 服务注册,服务注册是 Dubbo 服务提供者所需要做的操作,目的就是 将自己所提供的服务给暴露出去 ,这样其他的服务如果需要调用自己时,就可以找到当前已经暴露的服务,进行 RPC 远程调用!
那么实际上 【服务提供者】 和 【服务调用者】 是处于不同的机器上的,那么是如何实现两台机器的远程调用呢?
其实就是通过 网络通信 来实现,【消费者】向【提供者】发送调用请求,指明自己要调用的接口、方法信息,【提供者】收到调用请求之后,就在本地找到对应的方法执行,拿到执行结果之后,再将 执行结果 通过网络通信的方式返回给【消费者】,这样【消费者】就完成了一次 RPC 远程调用!

# 服务注册哪些信息?
上边说了 什么是服务注册 ,以及 RPC 远程调用的流程 !
那么这里说一下怎么注册,首先要搞明白两个问题:
- 注册的话去哪里注册?
- 注册什么信息?
Dubbo 中是可以选择注册中心的,那么常用的也就是 ZooKeeper 和 Nacos ,ZK 我了解的比较多,所以这里就以 ZK 举例(毕竟是了解原理,注册中心使用哪个倒无所谓)
不过使用 ZK 作为注册中心的公司正在减少 ,因为 ZK 是有 Leader 机制,往 ZK 里写数据都是往 Leader 里面写,这个 Leader 其实就是一个单点,所以整个写的过程是中心化的,并且如果节点很多的话,大量节点上下线会导致 ZK 推送大量的消息,此时 ZK 的突发压力是比较大的!
那么第一个问题就解决了,将服务的信息注册到注册中心 ZK 或者 Nacos 中即可
那么第二个问题呢,需要注册什么信息?
上边说了,RPC 远程调用需要建立网络通信,建立网络通信也就是 TCP 连接,肯定是需要知道对方机器的 【ip+port】 的,这是需要注册的第一个信息
进行远程调用,服务调用者肯定要知道提供者提供了哪些方法,这样才可以去进行调用,那么要注册的第二个信息就是 【实现类名+方法名】
这里我们简单画一张图:
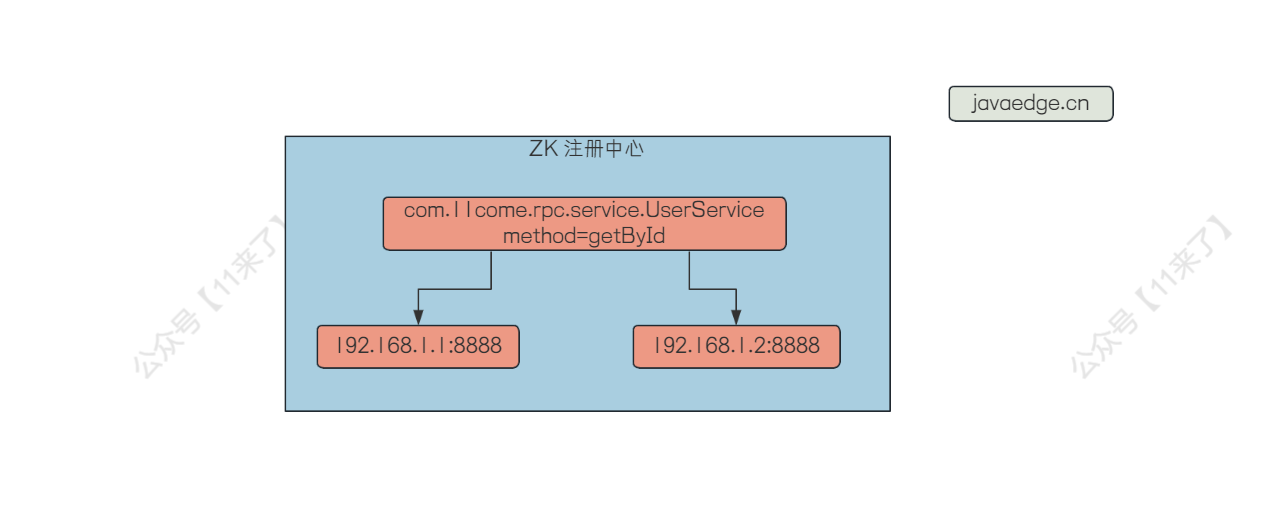
在注册中心以这样的方式注册节点,那么就将上边的两个信息都给存储到了注册中心了,Dubbo 服务注册就是通过这样的方式将自己给暴露出去
# Dubbo 如何实现的服务注册?
那么 Dubbo 是在哪里对服务进行注册的呢?
这其实就用到了 Spring 的扩展点: BeanPostProcessor
Dubbo 要将服务进行注册,会在需要对外暴露的服务上添加 @DubboService 注解,表示这是一个 Dubbo 服务提供类,主要是给 Spring 进行标识,让 Spring 知道这是我 Dubbo 需要暴露出去的服务!
@DubboService(version = "1.0.0", group = "test")
public class UserServiceImpl implements UserService {
@Override
public User getById(Long userId) {
// ...
}
}
那么要通过 Spring 扫描到这个服务提供类的话,就要通过 @ComponentScan 来指定需要扫描的包路径,这个就是在 @EnableDubbo 中进行指定(@EnableDubbo 是在使用 Dubbo 是在启动类上标识的)
那么有了 @EnableDubbo 这个注解,Spring 就知道去哪里扫描我们的 Dubbo 服务提供类了,于是 Spring 开始扫描
扫描的时候,Spring 提供了扩展点: BeanPostProcessor ,Dubbo 中就实现了这个扩展点,在这个扩展点中对 @DubboService 注解进行解析,并且找到需要暴露的方法,将方法注册到注册中心中去
至此,【提供者】就将自己的服务信息注册到 ZK 注册中心上了,来供【消费者】进行调用,接下来我们说一下【消费者】是如何进行服务调用的!
# Dubbo 服务调用
# 两台机器之间如何进行服务调用?
Dubbo 进行服务调用的话,是通过以下方式引入需要调用的服务:
@DubboReference(version = "1.0.0", group = "test")
private UserService userService;
那么 Dubbo 消费者目前的已知信息是: 需要调用的服务的接口、方法名称 ,也就是 com.11come.rpc.service.Uservice 这个接口名,以及方法名称 getById
那么 Dubbo 消费者是如何去进行服务调用的呢?
上边在说服务注册的时候说到了,服务调用其实就是通过 网络通信 进行远程调用,那么【消费者】去调用的话,只需要去注册中心根据接口名和方法名拿到【提供者】的 ip+port ,就可以和【提供者】建立 TCP 连接进行网络通信了!

# Dubbo 如何实现的服务调用?
这里说一下 Dubbo 是在哪里去进行服务拉取,以及 Dubbo 在我们开发人员无感知的情况下去发起了远程网络通信,完成了 RPC 的调用!
服务调用其实就是依靠 网络通信 ,Dubbo 中使用的网络通信组件就是 Netty
Dubbo 进行 RPC 调用的话,对于我们开发人员来说使用起来很方便,通过 @DubboReference 注解标注远程调用的接口即可:
@DubboReference(version = "1.0.0", group = "test")
private UserService userService;
只需要添加一个注解就可以进行远程调用了,我们使用起来非常方便,Dubbo 其实在底层做了许多的操作!
首先,我们引入的 UserService 是一个接口,肯定要对这个 userService 属性进行实例化才可以调用它的方法,那么这里就是用了 动态代理 来完成这个实例化的操作,并且将远程调用的逻辑放在动态代理的 拦截器 中,这样用户只是去调用了动态代理对象的方法,拦截器中进行远程调用的逻辑,用户就感知不到了!
这就是设计模式【代理模式】带来的好处!
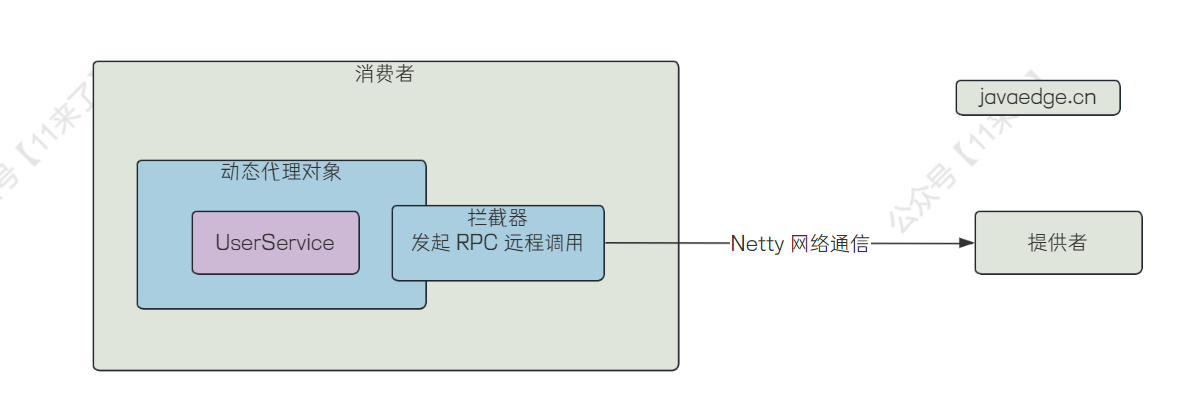
那么这个代理对象是什么时候生成的呢?
生成代理对象的实际其实和服务注册的时候差不多,当 Spring 扫描所有的类时,在 Spring 的扩展点 BeanPostprocessor 中对 @DubboRefercnce 注解进行解析,当发现 @DubboReference 标注的属性时,说明这个属性是 远程调用的属性 ,就为该接口生成一个动态代理,再注入到该属性中去,即 userService 此时其实是一个动态代理对象
# 总结一下服务调用的流程
最后再总结一下服务调用的流程:
1、Spring 扫描到 @DubboReference 标注的属性,在 BeanPostProcessor 中解析该注解,并且为该属性生成一个动态代理对象,并且将这个动态代理对象赋值给这个属性
2、当【调用者】调用动态代理对象的方法时,会进入到动态代理的拦截器中,在拦截器中会发起 RPC 调用
3、拦截器中执行 RPC 调用就是先根据接口名、方法名去注册中心拿到【提供者】的 ip+port,这样就可以通过 Netty 和【提供者】建立网络通信
4、建立网络通信之后,【调用者】将需要调用的接口、方法信息通过 Netty 发送给【提供者】,【提供者】就知道去执行哪个方法了,当【提供者】执行完对应的方法之后,将执行结果再通过 Netty 返回给【调用者】,至此,【调用者】就完成了一次服务调用的过程

这里如果【提供者】有多个的话,是可以进行负载均衡来选择一个提供者进行调用的,Dubbo 中常用的负载均衡策略:
- Random LoadBalance
基于权重的随机负载均衡策略,为 Dubbo 的 默认策略
- LeastActive LoadBalance
最少活跃负载均衡策略,也就是看哪台机器上活跃的请求比较少, Dubbo 就认为谁的活跃数越少,谁的处理速度就越快,性能也越好,这样的话,我就优先把请求给活跃数少的服务提供者处理
- ConsistentHash LoadBalance
一致性 Hash 负载均衡策略
可以保证相同参数的请求总是发到同一提供者,当某一台提供者机器宕机时,原本发往该提供者的请求,将基于虚拟节点平摊给其他提供者,这样就不会引起剧烈变动
# 在互联网环境下,理想的注册中心
摘自于阿里专家(2019年文章):曹胜利
CAP 理论:现在大部分主流而且在使用中的注册中心都是满足 CP 的,但是在互联网大集群环境下,期望的结果是满足 AP 的同时,能够满足最终一致性。在大集群环境下,可用性往往比强一致性的优先级更高。以 Zookeeper 为例,Zookeeper 能够为分布式系统提供协调功能的服务,默认提供强一致性的数据服务,但是它在某些情况下是允许 Zookeeper 是不可用的。列举一个场景,Zookeeper Leader 失效了,这时需要重新选举 Leader,而这个选举过程需要 30 秒以上(数据来自于网上的文章),这段时间内 Zookeeper 对外是不可用的。
去中心化:Zookeeper 是有 Leader 机制,往 Zookeeper 里写数据都是往 Leader 里面写,这个 Leader 其实就是一个单点。所以整个写的过程是中心化的。而且 Zookeeper 对跨城跨机房的方案上,支持非常有限。
数据推送的强控制:期望对推送的有更加强的灵活性。还是以 Zookeeper 为例,Zookeeper 中有 watch 机制,每个数据节点发生变更的时候,就会往外推送变更的通知。但是作为注册中心,我们期望能够控制它的推送频率,针对新增节点只需要一分钟里面推送 6 次就可以了,每十秒推送一次,这样可以合并一些变更通知,减少网络数据请求的数据量。
容量:Dubbo 是单进程多服务的方式来注册服务的。这也就意味着注册中心中需要存储的数据量较大,所以要有足够的容量来支撑这种场景。
那些注册中心产品:Zookeeper 作为服务注册中心的公司在减少,那么现在有哪些方案,可以来替代呢?
Eureka 是一个 AP 的应用,而且它是去中心化的。但是它有几点不足:
- 在我们的内部的性能测试中,它性能表现非常一般,性能大概只有 Zookeeper 的 60%左右。
- Eureka 内有一种契约机制,它每隔 30 秒会发起一个续约的请求,如果 3 次没有接收到,它才会过期失效;如果一个服务非正常退出(没有发起解约请求),那么就存在这个超时的间隙期,服务是不可用的。所以在生产环境,对服务敏感的相关应用方是无法满足需求的。
- Eureka 是应用维度的服务注册,当前的 dubbo 是服务维度的注册,如果要匹配的话,需要大范围改造。
- Netflix 宣布了停止更新 Eureka 2.0。
Etcd 是 Zookeeper 的升级版,它参考了 Zookeeper 的很多实现,同时进行了较多优化。Etcd 的强一致性协议和代码实现更加简单,它的部署方式也更加简单,它支持了 Rest 的方式进行相关访问,它的性能相对 Zookeeper 来说也有了一定的提升。但是它还是一个 CP 的系统,它也是要求数据的强一致性,而牺牲部分的可用性。
Consul 相对前面几个产品来说,更加专注服务注册发现本身,它是一个比较专业的服务注册中心。Consul 有了后台管理页面,它有了健康检查,Consul 原生支持多数据中心。但它的性能上有瓶颈的,它和 Zookeeper 和 ETCD 进行对比,它性能是稍微差一点的;同时 Consul 也要求数据的强一致性而牺牲部分可用性。
Nacos 是阿里巴巴开源的一个产品,内部系统也在使用,它已经经受了一定流量和用户的考验。现在阿里巴巴集团内部的 Provider 和 Consumer 数量已经到达了亿的级别,它现在能够支撑上亿级别的订阅量,整体经受了一定的实践检验。Nacos 整体设计是去中心化的,而且设计上满足 AP 和最终一致性,性能上和 Zookeeper 比较接近。
前段时间和网易考拉在沟通过程中也发现,他们也在做一个自己的注册中心;新浪也有一个自己的服务注册中心。所以许多大的互联网公司,因为定制或者差异化的需求,都在自研注册中心。
# Dubbo 生产环境问题排查案例
相关生产案例都搜集于网络,并非原创,在此声明!
# 一次关于 Dubbo 服务 IP 注册错误的踩坑经历
简介: 这不最近又遇到个问题,Dubbo 服务 IP 注册错误,好了,下面进入正题。
# 踩坑
阿粉公司最近新建一个机房,需要将现有系统同步部署到新机房,部署完成之后,两地机房同时对提供服务。系统架构如下图:

这个系统当前对外采用 Restful 接口,内部远程采用 Dubbo,服务注册中心使用 zookeeper。服务当前设定只会调用本机房内服务。
原先服务都在 A 机房,B 机房为新建机房。B 机房部署完成之后,需要测试 B 机房系统可用性。生产测试的发现 B 机房竟然调用 A 机房服务。
A/B 机房网络互相打通,可以互相访问
通过排查 B 机房服务日志,发现 Service B 一个服务节点注册 IP 解析错误,将 B 机房机器 IP 解析成 A 机房机器 IP。
于是当测试流量进入 B 机房时,openapi服务通过注册中心获取到错误的 Service B 服务地址,从而调用了 A 机房的服务。调用方式简化成如下图。

知识点:Dubbo 服务提供者启动时将会将服务地址(IP+端口)注册到注册中心,消费者启动时将会通过注册中心获取服务提供者地址(IP+端口),后续服务调用将会直接通过服务地址直接调用。
# 问题分析
Debug Dubbo 源码,定位到 IP 解析代码,位于 ServiceConfig#findConfigedHosts,源码如下:
Dubbo 版本为 2.6.7
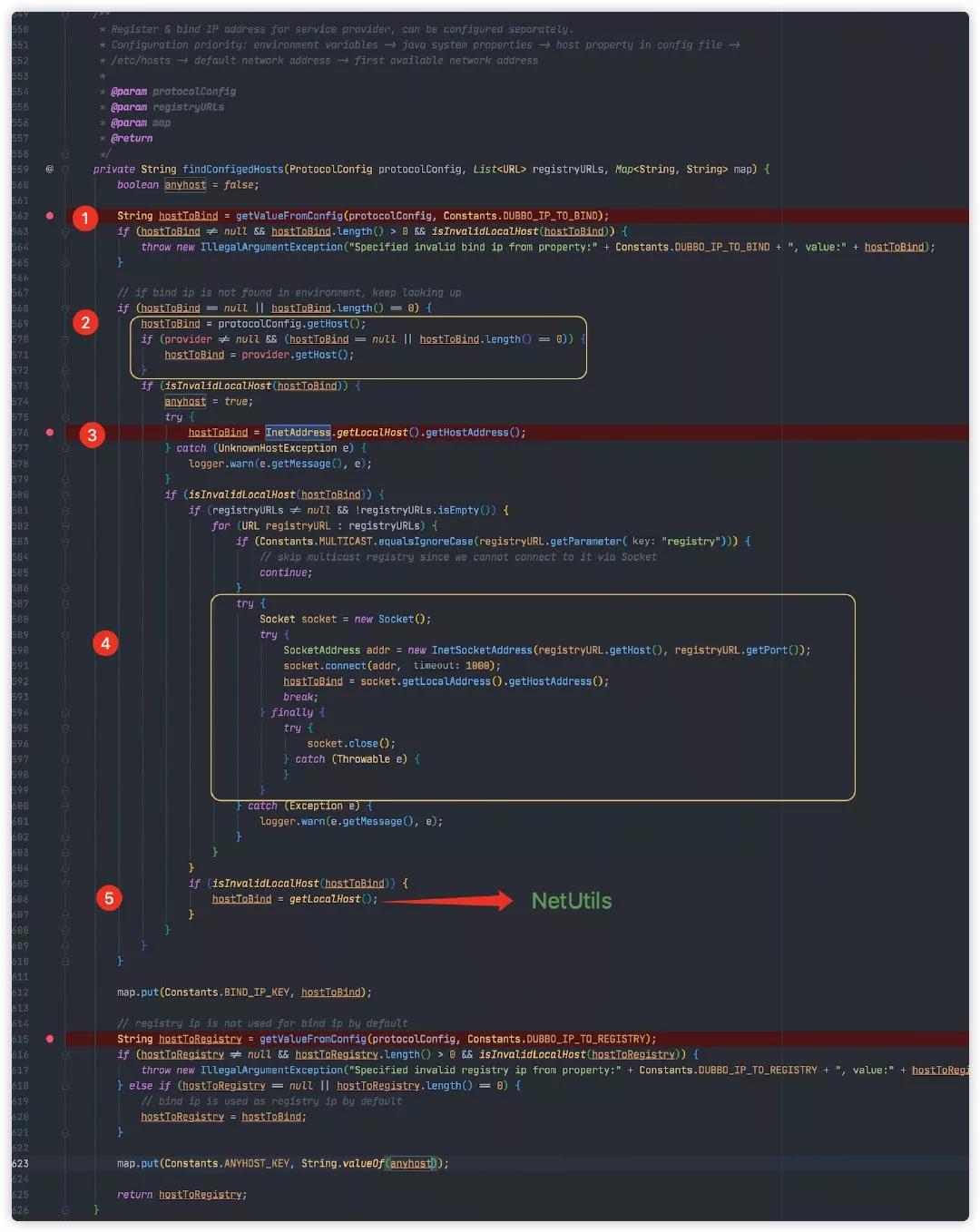
这个方法源码比较长,看起来比较费劲,不过好在这个方法注释上已经写明白 IP 地址查找顺序。
Register & bind IP address for service provider, can be configured separately. Configuration priority: environment variables -> java system properties -> host property in config file -> /etc/hosts -> default network address -> first available network address
解析过程,Dubbo 将会过滤无用 IP,过滤规则如下:
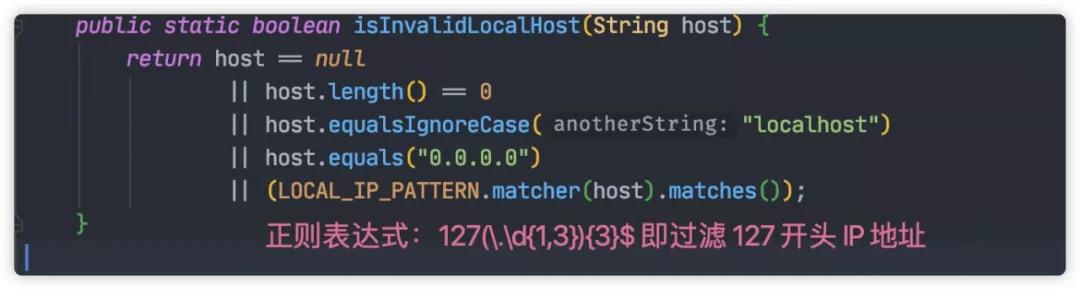
下面将结合图示讲解查找顺序,只要其中一步读取 IP 符合上述规则,方法就会返回。
第一步将会调用 ServiceConfig#getValueFromConfig 从 environment variables 或 java system properties 配置 IP 地址。
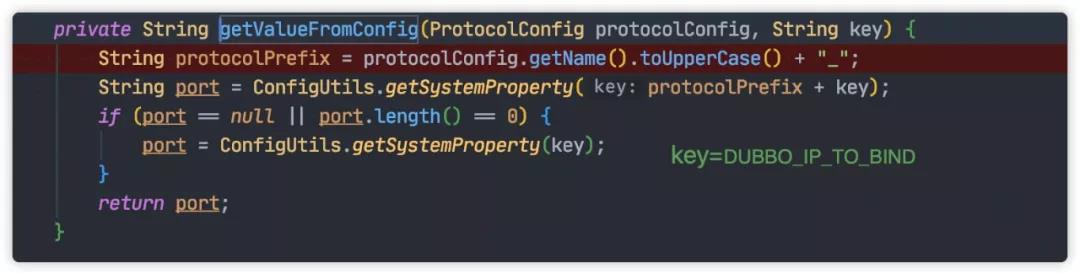
这种方式通过在 JVM 启动参数中显示指定 IP 。
-DDUBBO_IP_TO_BIND=1.2.3.4
第二步通过读取 Dubbo 配置文件配置变量获取 IP。
<!-- protocol 指定整个 Dubbo 应用服务默认 IP -->
<dubbo:protocol host="1.2.3.4"/>
<!-- provider 指定 Dubbo 应用具体某个服务默认 IP -->
<dubbo:provider host="1.2.3.4"/>
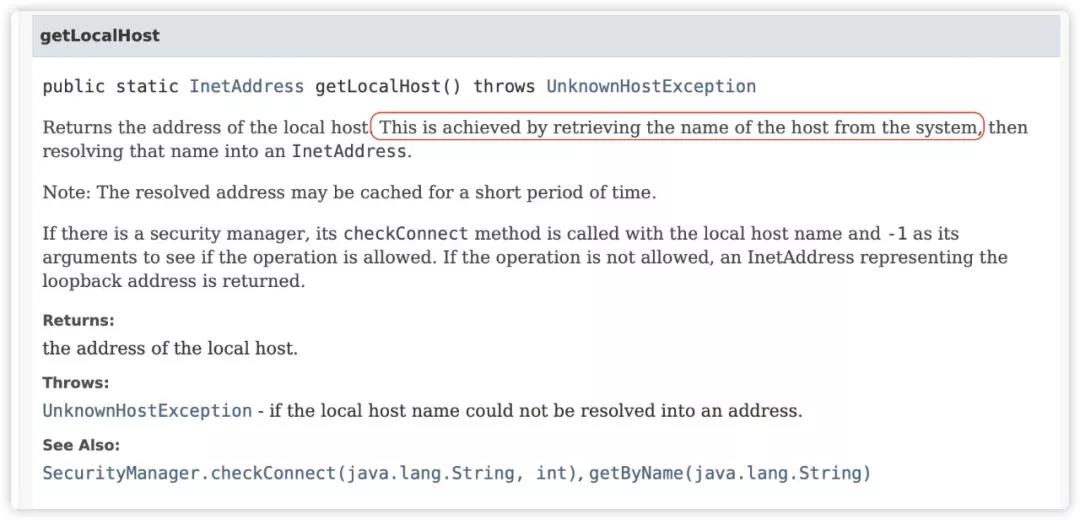
第三步通过调用 InetAddress.getLocalHost().getHostAddress() 获取本地 IP。该方法将会获取机器 hostname,然后再在 /etc/hosts 配置文件中查找 hostname 对应的配置 IP。
第四步通过 socket 连接注册中心从而获取本机 IP。
如果上述几步都不成功,Dubbo 将会轮询本机所有网卡,直到找到合适的 IP 地址。

问题原因
通过排查上述几个规则,最后发现本地 /etc/hosts 文件 IP 配置错误, hostname 配置成了 A 机房的 IP 。
# 总结
这次的问题其实不大,就是 hosts 文件配置错误,但是整个查找问题的过程还是值得学习的,深入到了源码层面,跟踪代码,最终发现问题。毕竟运维人员和开发人员在一定的程度上还是会出现沟通问题,而且还是生产环境,所以更加需要仔细。
我们可以看到 Dubbo 在 IP 解析上花费很大功夫,最大程度上帮我们自动获取正确 IP。但是现实还是很残酷,真实环境下机器可能存在多网卡,内外网 IP,VPN ,或者应用采用 Docker 部署,这些情况下Dubbo 有可能就会获取到错误 IP,从而导致消费者调用失败。如果真遇到这种情况,读者首先通过上面顺序排查 IP 读取来源,若最后确定 IP 读取自网卡 。这种情况下就只能根据下面几种方式显示指定 IP。
配置方式一:在 JVM 启动参数中加入如下配置
-DDUBBO_IP_TO_BIND=1.2.3.4
配置方式二:在 /etc/hosts 设置 hostname 对应的 IP。
配置方式三:Dubbo 配置文件显示指定 IP。
<!-- protocol 指定整个 Dubbo 应用服务默认 IP -->
<dubbo:protocol host="1.2.3.4"/>
<!-- provider 指定 Dubbo 应用具体某个服务默认 IP -->
<dubbo:provider host="1.2.3.4"/>
# 阿里专家讲 Dubbo 真实生产案例:Dubbo3 中应用级注册的前身
文章来源于阿里专家(2019年文章):曹胜利
特说明:该文章完成时 Dubbo3 还没有完成!
# 背景知识介绍

注册中心注册介绍
在 RPC 整个链路中,需要的元素有 Provider、Consumer,以及注册中心(中间 Zookeeper 是作为注册中心来使用的)。整个注册过程如下:
- Provider 会把一长串 URL(dubbo://xxx 的字符串)写入到 Zookeeper 里面某个节点里面去。
- Consumer 的注册也是类似,会写到 Zookeeper 里面某个节点(Consumer 写入的原因,是因为 OPS 服务治理的时候需要实时的消费者数据)。
- Consumer 发起一个订阅,订阅相关的服务。
- 当某个服务的 Provider 列表有变化的时候,Zookeeper 会将对应的变化通知到订阅过这个服务的 Consumer 列表。
从图中我们可以看到 Provider 端的 URL 非常长,特别是当一个服务有大量方法的时候。Provider 端的 URL 会先从 Provider 到 Zookeeper,再往 Consumer 传递,这样导致了单次传输的网络开销比较大。
那么再来看一下集群的情形,图中左边有 N 个 Provider,右边有 M 个 Consumer,那么 Provider 发布的时候,会遇到什么情形呢?Provider 每次发布它会先下线再上线,所以每个 Provider 发布的时候,Provider 会发送两次通知,也就是发送 2N 次;接收数据方有 M 个 Consumer,最后算出在整个网络里面的推送数据的次数是 2N×M。
# 案例
来看一个真实的案例,在杭州有一家中等规模的电商公司,公司内部有 4000+个服务,以 Zookeeper 作为注册中心,Zookeeper 有 100w 个节点,在发布日的时候,公司内部网络的网卡被打爆了,进而导致服务变更的推送失败,新的服务注册也失败。整个集群基本上处于不可用状态。同样的也收到了一些中小公司的反馈,每次在发布的时候,网络也会有个抖动。
分析一下为什么会出现这种情形。
Zookeeper 的 100 万节点中,大约有 10 万个 Provider 节点和 50 万个 Consumer 节点。按照前面的算法,在所有 Provider 同时发布的极端情况下,有 2×10 万×50 万次推送,也就是说会产生 1000 亿条的数据推送。针对每次推送的数据进行了一个统计,每条 URL 大小大概有 1KB,那么计算出来的极端的推送数据量是 1KB 再乘以 1000 亿,已经是 100TB 的级别了。
上面说的是极端情形,就算是发布日也不可能同时进行发布:有的应用发布日不发版本,不同应用不可能同时发布,同一个应用也需要分批发布。假设同一时刻发布的量在千分之一,那么推送的数据量也在 100GB,所以出现发布日的时候间断性地网卡爆掉的现象就不足为奇了。每次发布的时候,都会想着要跟别的应用发布时间错开,争取单独发布,作为程序员还要纠结这个事情真是一个悲剧。
# 案例分析
来分析下现在的问题和需求:
首先,根据上述案例中的数据分析得知,性能出现了问题。推送的数据量非常大,存储的数据量大,网络传输量大,服务推送延迟,网卡堵塞,服务注册不可用。
接着对 Provider 端那个很长的 URL 进行分析之后发现,不需要把整个 URL 写到注册中心里,只需要把 IP 的端口写进去就可以了,因为只有 IP 的端口需要实时变化。把其他信息放到一个类似的 KEY-VALUE 结构的持久化存储里去,而且这个 KEY-VALUE 结构只要是应用级别就行了,节省了大量的存储空间。
社区中对服务测试的需求非常强烈。要支持服务测试需求,就需要知道调用的服务方法名,入参出参的详细信息。所以这部分信息也是需要存储下来的。但是这部分信息非常大,每个服务中可能有 10 多个方法,每个方法可能有三四个方法入参,入参和出参的完整数据结构往往非常复杂。这部分数据信息也叫做服务的元数据信息。
首先来看一下怎么解决性能的问题。主要有两种方式可以解决:
- 怎么减少当次的注册量,就像前面分析的,只存储 IP 的端口到注册中心;
- 是否可以减少推送的次数,现在推送次数太大了。
# 减少单次推送量
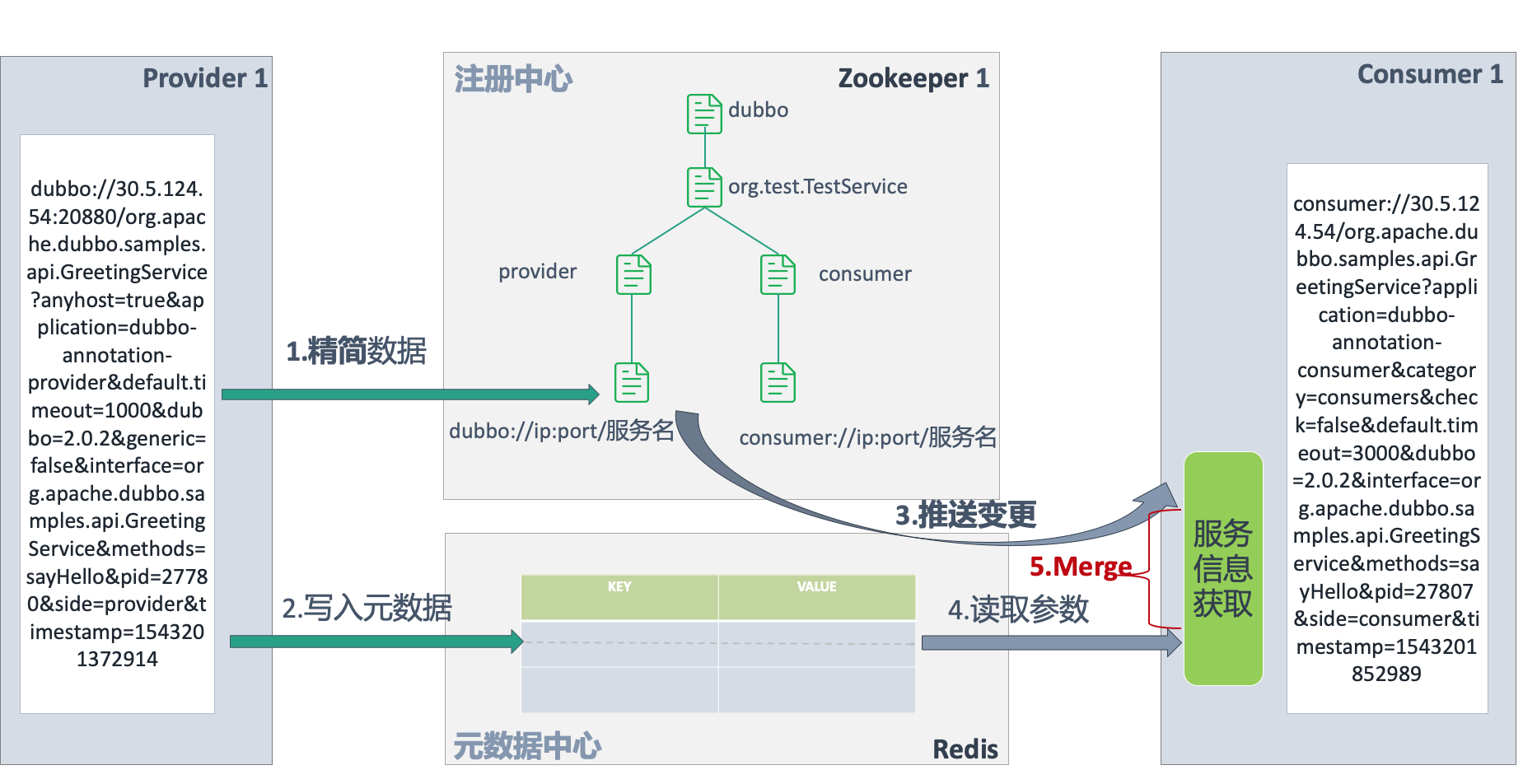
查看上图可知,Provider 端 URL 还是很长,期望简化往注册中心注册的信息;同时服务测试需求,又同时期望能将更丰富的元数据信息进行持久化的存储。
Provider 端写入的改造。Provider 往注册中心写的时候,将整个数据的写入分成两部分:
- 写入注册中心;
- 写入元数据中心。
注册中心作为服务的注册和发现,更加关注数据的实时性和有效性(watch 机制),整个 URL 中 IP 和端口就能判断某个服务是否可用,其他信息都是相对固定不变的。所以注册中心中,只需要存储 IP 和端口。元数据中心中存储 URL 中除 IP 和端口外的其他信息,加上服务测试需要的服务方法名,服务方法的出入参信息。元数据是一个 KEY-VALUES 的持久化存储,是独立于注册中心的存储,它不需要有 watch 的机制,而只需要提供持久化存储。图中使用的的 KEY VALUE 存储是 Redis,但是元数据中心定义了一套 SPI,开发者可以去扩展,可以自己实现 DB 存储,或者其他持久化存储的方式。
Consumer 端获取 Provider 列表信息的改造。Dubbo 之前的版本中,直接从注册中心里面获取 Provider 端的服务信息,获取到的信息已经是一个完整的可调用的服务信息。但是 Provider 端写入改造之后,原有 Consumer 端获取的 Provider 服务信息的方式不可用了。除了从注册中心获取到的数据之外,还需要从元数据中心里拿到元数据信息,然后对这两部分数据做一个 Merge 之后才能构建出完整的可调用的服务信息。
当前 Dubbo2.7 版本还没有完全去除所有参数,而是采用先去除部分参数的方式来验证;后续会逐渐迭代完善,同时在 2.6.x 版本中也会进行一些兼容方案的支持。
# 应用级服务注册
上面的改造针对的是怎么减少单次的推送数据量,针对的还是服务维度。期望中最理想地给注册中心减负的方式是应用维度的服务注册和发现,可以参考 Spring Cloud 体系下的 Eureka 实现。一旦实现这种方案,服务注册中心就再也不会成为 RPC 领域的瓶颈,而且可以认为这种方案是服务注册的终极方案。
当然这种实现方式做的改动相对比较大,不仅需要将服务执行和运维完全分开,而且需要一定的架构体系改造来支撑具体服务的发现。到目前为止还没有形成成熟可靠的方案,团队内部也只是在探讨阶段。
# 服务变更推送开关
所谓服务变更推送开关,就是针对任何的服务信息的变更,不进行推送。
到底哪种情形需要这种开关呢?阿里巴巴整个集群的机器数非常大,所以宿主挂掉或者虚拟机挂掉出现的概率比较高。在每年双十一的时候,大部分消费者都会去淘宝天猫上购物。在 11 月 10 号 11 点 50 几分开始,大量买家在拼命地刷新购物车或者商品详情页面,这时候阿里巴巴内部的系统负载是非常高的,网络负载也非常高。如果这时候,有一台机器因为宿主机挂了的原因而导致部分服务下线,这时候需要推送相关应用服务下线的变更给对应的服务 Consumer。这时候就需要占用网络带宽,可能对服务调用产生影响,进而还会对双十一造成很大的压力。所以这时候就希望有一个开关,能够把整个服务推送关掉。
但是这时候也会带来一些问题,当服务 Provider 不可用的时候,注册中心没有向服务 Consumer 推送变更通知,服务 Consumer 请求的时候可能会报错,这时候的小部分服务出错可以允许的;保证整个集群上万台机器,特别是整个双十一核心链路的稳定性才是双十一最重要的使命。
# 服务分组
在一个大的集群环境中,在没有路由规则的情况下,Consumer 集群会调用整个 Provider 集群中的任何机器。服务分组,就是对 Consumer 集群和 Provovider 集群进行分组,将大的服务级分成几个子集。
举个例子,集群中有 8 个 Consumer 实例,有 8 个 Provider 实例,按照正常流程 Consumer 这 8 个实例会调用 Provider 任何一台,任何一个 Provider 的变更通知也会通知到这 8 个 Consumer 实例。但是如果对它进行分组呢,Consumer 实例集群分成 A 和 B 两个组,Provider 集群也分成 A 和 B 两个组。Consumer 中 A 的组只能调到 Provider 中 A 组的服务;Provider 的 A 组中的实例在发布过程中,也只会推送到 Consumer 的 A 组中,而不会推动 Consumer 的 B 组。最终通过推送的范围,来减少了推送的数据总量。