 11.美团优选后端一面
11.美团优选后端一面
# 美团优选后端一面
美团优选一面主要问了 项目 、 计算机基础 、 八股
# 项目
# 1、项目中负责了什么工作?遇到了什么问题?如何解决?
结合自己项目说即可,要在项目上多花费一些精力
# 2、TCP 报文的组成?有哪些标志位?
TCP 报文主要由头部和数据组成,头部放一些标志字段,其中比较重要的就是橙色部分的 标志位 ,总共有 6 位,代表不同的功能吗,TCP 报文的组成如下:

橙色部分的 6 个标志位功能如下:
1、UGR: 紧急指针标志,用于传输紧急数据 2、ACK : 确认序号标志,用于确认收到数据 3、PSH: 提示接收方在接收到数据以后,应尽快的将这个报文交付到应用程序,而不是在缓冲区缓冲 4、RST : 用于重置错误的连接 5、SYN : 建立连接时使用 6、FIN : 用于释放连接
其中 seq 和 ack 功能如下:
seq :发送数据的第一个字节的序号,比如当前报文段的 seq 为 100,当前报文段有 100 个字节,那么下一个报文段的 seq 就是 200
ack :期待下一个收到的字节序号,比如收到了 seq 为 100 的 TCP 报文,该报文有 100 个字节,那么应该回复的 ack 就是 200
# 3、HTTP 和 HTTPS 的区别?
HTTP 是明文传输的,因此存在安全风险,而 HTTPS 则是在 HTTP 的基础上添加了 SSL/TLS 协议,来保证通信的安全的
那么双方如果需要建立 HTTP 通信的话,只需要通过 TCP 三次握手即可
但是若果需要建立 HTTPS 通信的话,除了 TCP 三次握手建立 TCP 连接,还需要进行 SSL/TLS 握手,之后双方才可以加密进行通信
扩展:HTTPS 通信流程
HTTPS 的通信流程为:
- 客户端向服务器请求获取 公钥
- 双方协商产生 对称密钥
- 双方采用 对称密钥 进行加密通信
前两个步骤是建立 SSL/TLS 的过程,HTTPS 是基于 SSL 或 TLS 进行加密的,不过 SSL 已经退出历史舞台了,现在说的 HTTPS 其实就是 HTTP+TLS
那么 TLS 握手的过程总共包含了 4 次通信 ,在 4 次通信之后,TLS 协议也就建立成功了,可以进行 HTTPS 通信了,4 次通信如下:
- 第一次通信 ClientHello:客户端向服务端发送加密请求,主要是协商 TLS 版本、随机数(生成后续的对称密钥)
- 第二次通信 ServerHello:服务端向客户端回复,主要协商 TLS 版本、随机数(生成后续的对称密钥)、数字证书(包含公钥)
- 第三次通信 客户端回应:取出数字证书的公钥,将用于通信的 对称密钥 通过公钥加密发送给服务端
- 第四次通信 服务端最后回应:使用自己本地的密钥进行解密,得到用于通信的 对称密钥
之后双方就可以使用这个 对称密钥 进行加密通信了
# 4、说一说操作系统中的死锁,如何避免死锁呢?具体使用什么样的算法?
死锁需要 同时满足 四个条件才会发生:
1、互斥 :资源是互斥的,也就是一个资源只能被一个进程持有
2、持有并等待 :一个进程至少占有一个资源,并且正在等待获取额外的资源
3、不可剥夺 :进程持有的资源不可以被其他进程抢占
4、循环等待 :每个进程持有下一个进程所需要的至少一个资源
避免死锁的话,可以通过破坏四个条件中的一个或几个来避免死锁,对于 互斥 来说,一般无法避免,因为有些资源互斥的特性我们无法改变
避免死锁常用的方法是:资源分配图 和 银行家算法
- 资源分配图 是标识进程与资源之间分配状态的有向图,节点分为 进程节点(P) 和 资源节点(R)
通过检查资源分配图中是否存在环,可以检测系统是否处于死锁状态。如果图中存在环,则系统处于死锁状态。
- 银行家算法 是一种避免死锁的预分配策略,预分配流程如下:
1、当进程请求资源时,系统尝试分配,分配后判断系统是否处于安全状态
2、如果分配后系统处于安全状态,则允许分配,否则拒绝请求
# 5、什么是虚拟内存?为什么需要?优缺点
虚拟内存是现代系统提供的对主存储器的抽象,是用于内存管理的一种技术
虚拟内存的作用就是为每个进程提供了一个大的、统一的、私有的地址空间,让每个进程认为自己在独享内存
虚拟内存的意义是定义了一块连续的虚拟地址空间,并且将内存空间扩展到了磁盘空间,也就是说一块连续的虚拟内存在进程看来是连续的,但是其实是多个物理内存碎片,并且还有一部分暂存在磁盘上,如果需要用到磁盘上的数据的话,需要进行数据交换
# 为什么需要虚拟内存?
通过虚拟内存,程序可以拥有超过物理内存大小的可用内存空间,并且为每个进程提供了一个连续、独享的内存空间,一个进程的错误不会影响到其他进程,提升系统稳定性
并且操作系统可以更加灵活的管理内存资源,如按需加载页面、提供高效的缓存机制
# 虚拟内存的优点
使用虚拟内存优点如下:
1、程序可以不受物理内存大小的限制
2、不同进程之间的内存空间相互隔离,减少进程之间干扰和内存冲突
3、操作系统可以更灵活的管理内存资源
# 虚拟内存的缺点
使用虚拟内存缺点如下:
1、需要将虚拟地址转换到物理地址,增加额外的性能开销
2、管理虚拟内存增加了操作系统的复杂性
3、当内存和磁盘中需要数据交换时,速度是比较慢的
扩展:操作系统如何管理虚拟地址与物理地址之间的映射关系呢?
有 内存分段 和 内存分页 两种方式
# 内存分段
内存分段 会根据进程实际需要使用内存大小进行分配,需要多少内存就分配多大内存的段,但是由于每个段的长度不固定,因此会在物理内存上出现内存碎片的问题,也称为 外部内存碎片 问题
举个例子:有 100MB 物理内存,程序 A 使用了 30MB,占据了 0-30MB 的区域,程序 B 使用了 40MB,占据了 30-70MB 的区域
此时程序 A 卸载了,于是腾出了 0-30MB 的内存区域,又进来一个程序 C 占用 35MB,但是此时只有 0-30MB 和 70-100MB 的物理内存区域是空闲的,并没有 35MB 的连续空间供程序 C 使用,这就是外部内存碎片问题
解决外部内存碎片问题的方法就是 内存交换 :也就是将程序 B 先写到磁盘,再读回内存,此时将程序 B 放在内存 0-30MB 的区域,那么就留出来了 70MB 的连续空闲内存可以供程序 C 使用
内存分段的缺点: 存在外部内存碎片问题,需要内存交换来解决,效率比较低,因此为了解决该问题,引入了 内存分页
# 内存分页
内存分页 会将虚拟和物理内存空间切分为一页一页的固定大小,这样就 不会存在内存碎片的问题了 ,通过 页表 来记录虚拟地址和物理地址之间的映射关系,如果物理内存不够的话,操作系统会根据置换策略,将一些页面给写入到磁盘上,释放这些页面占用的内存空间,当需要使用这些页面时,再去磁盘中加载对应页到内存中
# 6、深拷贝和浅拷贝?Java 里如何实现?
深拷贝和浅拷贝的区别为:
- 深拷贝: 完全复制一个新的对象出来,对象中的属性如果是引用类型,就再创建一个该类型的变量赋值给拷贝对象
- 浅拷贝: 在堆中创建一个新的对象,对象中的属性如果是引用类型,就直接将该属性的引用赋值给拷贝对象,那么此时原对象和拷贝对象共享这个引用类型的属性了
浅拷贝实现:
Java 中实现浅拷贝通过实现 Cloneable 接口来实现,从输出可以发现原 Student 对象和新 Student 对象中的引用属性 Address 的地址相同,说明是浅拷贝:
public class Student implements Cloneable {
public Address address;
@Override
protected Object clone() throws CloneNotSupportedException {
Student student = (Student) super.clone();
student.setAddress((Address) student.getAddress().clone());
return student;
}
@Override
public String toString() {
return "Student{" +
"address=" + address +
'}';
}
public void setAddress(Address address) {
this.address = address;
}
public Address getAddress() {
return address;
}
public static void main(String[] args) throws CloneNotSupportedException {
Student student = new Student();
student.setAddress(new Address());
Student clone = (Student) student.clone();
System.out.println(student);
System.out.println(clone);
System.out.println(student == clone);
/**
* 输出:
* Student{address=com.example.springbootpro.DeepCopy.Address@6f539caf}
* Student{address=com.example.springbootpro.DeepCopy.Address@6f539caf}
*/
}
}
public class Address {}
深拷贝实现:
实现深拷贝的话,只需要修改 Student 的 clone() 方法,在该方法中对 Address 对象也进行克隆就好了,Address 对象也需要实现 Cloneable 接口
public class Student implements Cloneable {
public Address address;
@Override
protected Object clone() throws CloneNotSupportedException {
Student student = (Student) super.clone();
student.setAddress((Address) student.getAddress().clone());
return student;
}
@Override
public String toString() {
return "Student{" +
"address=" + address +
'}';
}
public void setAddress(Address address) {
this.address = address;
}
public Address getAddress() {
return address;
}
public static void main(String[] args) throws CloneNotSupportedException {
Student student = new Student();
student.setAddress(new Address());
Student clone = (Student) student.clone();
System.out.println(student);
System.out.println(clone);
System.out.println(student == clone);
/**
* 输出:
* Student{address=com.example.springbootpro.DeepCopy.Address@6f539caf}
* Student{address=com.example.springbootpro.DeepCopy.Address@79fc0f2f}
* false
*/
}
}
public class Address implements Cloneable{
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
# 7、JVM 的类加载过程?
采用双亲委派机制进行加载,JVM 在加载类的 class 文件时,Java虚拟机采用的是 双亲委派机制 ,即把请求交给父类加载器去加载
工作原理:
- 如果一个类加载器收到了类加载请求,他并不会自己先去加载,而是把这个请求委托给父类的加载器去执行
- 如果父类加载器也存在其父类加载器,则继续向上委托
- 如果父类加载器可以完成类加载任务,就成功返回;如果父类加载器无法完成类加载任务,则会由自家在其尝试自己去加载
优势:
- 避免类的重复加载
- 保护程序安全,防止核心API被篡改(例如,如果我们自定义一个java.lang.String类,然后我们去new String(),我们会发现创建的是jdk自带的String类,而不是我们自己创建的String类)
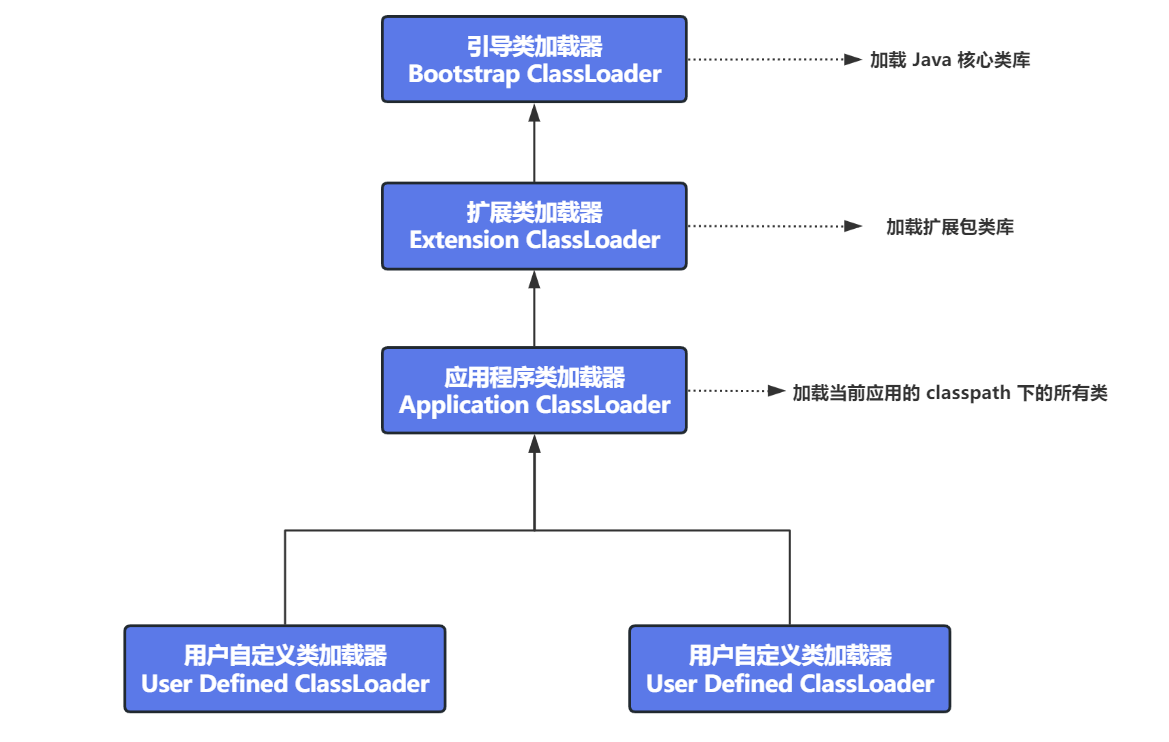
扩展:哪里打破了双亲委派机制?为什么要打破?
- 在实际应用中,可能存在 JDK 的基础类需要调用用户代码,例如:SPI 就打破双亲委派模式(打破双亲委派意味着上级委托下级加载器去加载类)
- 比如,数据库的驱动,Driver 接口定义在 JDK 中,但是其实现由各个数据库的服务上提供,由系统类加载器进行加载,此时就需要
启动类加载器委托子类加载器去加载 Driver 接口的实现
- 比如,数据库的驱动,Driver 接口定义在 JDK 中,但是其实现由各个数据库的服务上提供,由系统类加载器进行加载,此时就需要
# 8、JVM运行时数据区?
运行时数据区主要包含:方法区、堆、栈,如下图:

这里只要讲清楚各个区域存储哪些对象就好了,是 JVM 中比较基础的内容,这里就不写太详细了
# 9、抽象类和接口的区别?
抽象类和接口之间最明显的区别:抽象类可以存在普通成员函数(即可以存在实现了的方法),而接口中的方法是不能实现的
接口设计的目的: 是对类的行为进行约束,约束了行为的有无,但不对如何实现进行限制
抽象类的设计目的: 是代码复用,将不同类的相同行为抽象出来,抽象类不可以实例化
接下来举一个例子更好理解,在常用的设计模式 模板方法模式 中,就会用到抽象类,在抽象类中可以对外暴露出一个方法的调用入口,这个方法中规定了需要执行哪些步骤,之后再将这些步骤的实现延迟到子类,那么不同的子类就可以有不同的实现了
如下,假设有一个制作饮料的过程,那么对外暴露一个方法 prepareRecipe() 供外界调用,该方法规定了制作饮料需要哪些步骤,将这些步骤定义为抽象方法,交由子类来实现,那么不同子类(制作柠檬水、制作咖啡)就可以对这些步骤进行定制化操作了
public abstract class Beverage {
// 模板方法,定义算法的框架
public void prepareRecipe() {
boilWater();
brew();
pourInCup();
addCondiments();
}
abstract void brew(); // 由子类提供具体实现
abstract void addCondiments(); // 由子类提供具体实现
void boilWater() {
System.out.println("Boiling water");
}
void pourInCup() {
System.out.println("Pouring into cup");
}
}
class Tea extends Beverage {
void brew() {
System.out.println("Steeping the tea");
}
void addCondiments() {
System.out.println("Adding lemon");
}
}
class Coffee extends Beverage {
void brew() {
System.out.println("Dripping Coffee through filter");
}
void addCondiments() {
System.out.println("Adding sugar and milk");
}
}
个人认为抽象类的功能是包含了接口的功能的,也就是抽象类功能更多,那么在使用时如何来选择呢,到底使用接口还是使用抽象类?
可以从这个方面进行考虑,Java 是 单继承、多实现 的,因此继承抽象类的话,只能继承 1 个,而实现接口可以实现多个,因此在工程设计中,如果只是需要规定一个实现类中需要实现哪些方法,这个功能对于接口和抽象类都具有,那么毫无疑问使用接口,这样就可以将继承的机会给留出来,毕竟很宝贵
而如果需要使用模板方法模式,也就是要定义一些方法的执行流程,并且将这些流程延迟到子类实现,那只能使用抽象类,因为接口并不具备该功能
# 10、我们现在一般使用自增作为主键,为什么要这样做?
这个要从 MySQL 如何存储来讲了,MySQL 的数据在底层是通过 B+ 树索引进行存储的,根据 主键值 来建立聚集索引
在向表里插入数据时,如果 主键自增 ,那么插入的每一条新数据都在上一条数据的后边,当达到页的最大填充因子,下一条记录就会被写入新的页中
如果不自增的话, 选择 UUID 作为主键 ,那么每一条数据插入的位置是随机的,因此新插入的数据很大概率会落在已有数据的中间位置,存在以下问题:
1、写入的目标页可能已经刷到磁盘上并从内存中删除,或者还没有被加载到内存中,那么 InnoDB 在插入之前,需要先将目标页读取到内存中。这会导致大量随机 IO
2、写入数据是乱序的,所以 InnoDB 会频繁执行页分裂操作
3、由于频繁的页分裂,页会变得稀疏并且被不规则地填充,最终数据会有碎片
# 11、关于乐观锁和悲观锁,MySQL 是怎么实现的?
MySQL 中的乐观锁通过 版本号 来实现,如下面 SQL
UPDATE table_name SET column1 = new_value, version = version + 1 WHERE id = some_id AND version = old_version;
如果 version 未被修改,则允许更新;如果 version 已被修改,则拒绝更新操作
乐观锁适用于并发冲突较少的场景,因为它避免了在读取数据时加锁,从而减少了锁的开销
但是在高并发环境中,如果冲突频繁,乐观锁可能导致大量的重试操作,从而影响性能。在这种情况下,可能需要考虑使用悲观锁或其他并发控制策略
悲观锁的话,MySQL 中有行锁、表锁来保证共享数据资源的并发访问安全,行级锁又分为了记录锁、间隙锁、临键锁、插入意向锁,各个锁之间的职责不同
扩展:可以了解一下 MySQL 中的行级锁