03.Redisson分布式锁源码分析
03.Redisson分布式锁源码分析
# Redisson源码分析
# Redis 和 ZooKeeper 分布式锁优缺点对比以及生产环境使用建议

在分布式环境中,需要保证共享资源安全的话,一般是需要使用到分布式锁的,那么常用的分布式锁有基于 Redis 实现的,也就基于 ZooKeeper 来实现的
这里说一下这两种分布式锁有什么区别,以及如何进行技术选型
- Redis 实现的分布式锁
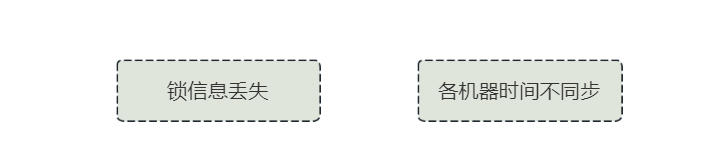
Redis 实现的分布式锁的话,不能够 100% 保证可用性 ,因为在真实环境中使用分布式锁,一般都会集群部署 Redis ,来避免单点问题,那么 Redisson 去 Redis 集群上锁的话,先将锁信息写入到主节点中,如果锁信息还没来得及同步到从节点中,主节点就宕机了,就会导致这个锁信息丢失
并且在分布式环境下可能各个机器的时间不同步,都会导致加锁时出现一系列无法预知的问题
因此 RedLock 被 Redis 作者提出用于保证在集群模式下加锁的可靠性,就是去多个 Redis 节点上都尝试加锁,超过一半节点加锁成功,并且加锁后的时间要保证没有超过锁的过期时间,才算加锁成功,具体的流程比较复杂,并且性能较差,了解一下即可
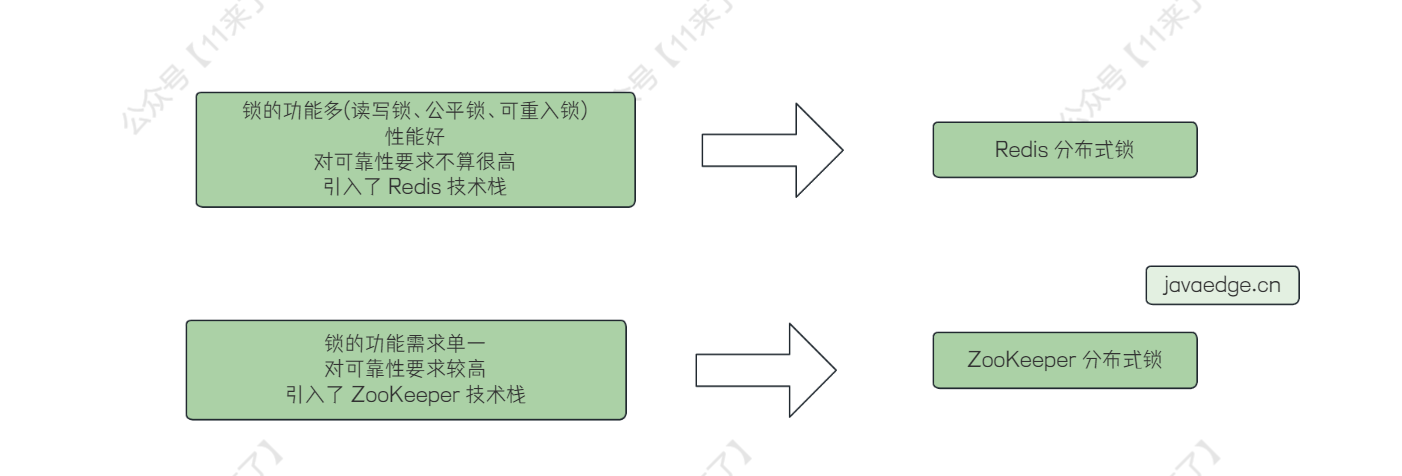
所以说呢,在分布式环境下,使用 Redis 做分布式锁的话,或多或少都可能会产生一些未知的问题,并且 Redis 本质上来说也不是做分布式协调的,他只是作为一个分布式缓存解决方案存在

如果业务不追求非常高的可靠性,可以选用 Redisson 分布式锁
- ZooKeeper 实现的分布式锁
ZooKeeper 的分布式锁的特点就是:稳定、健壮、可用性强
这得益于 ZooKeeper 这个框架本身的定位就是用来做 分布式协调 的,因此在需要保证可靠性的场景下使用 ZooKeeper 做分布式锁是比较好的

ZooKeeper 的分布式锁是 基于临时节点 来做的,多个客户端去创建临时同一个节点,第一个创建客户端抢锁成功,释放锁时只需要删除临时节点即可
因此 ZooKeeper 的分布式锁适用于 对可靠性要求较高 的业务场景,这里是相对于 Redis 分布式锁来说相对 更见健壮 一些
并且 ZooKeeper 的分布式锁在 极端情况下也会存在不安全的问题 ,也不能保证绝对的可靠性:
如果加锁的客户端长时间 GC 导致无法与 ZooKeeper 维持心跳,那么 ZK 就会认为这个客户端已经挂了,于是将该客户端创建的临时节点删除,那么当这个客户端 GC 完成之后还以为自己持有锁,但是它的锁其实已经没有了,因此也会存在不安全的问题
- 真实项目实际使用建议
这里最后再说一下真实项目中使用如何进行选型,其实两种锁使用哪一个都可以,主要看公司技术栈如何以及架构师对两种锁的看法:
具体选用哪一种分布式锁的话,可以根据需要使用的功能和已经引入的技术栈来进行选择,比如恰好已经引入了 ZK 依赖,就可以使用 ZK 的分布式锁
其实这两种锁在真正的项目中使用的都是比较多的
而且要注意的是无论是使用 Redis 分布式锁还是 ZK 分布式锁其实在极端情况下都会出现问题,都不可以保证 100% 的安全性,不过 ZK 锁在健壮性上还是强于 Redis 锁的
可以通过分布式锁在上层互斥掉大量的请求,如果真有个别请求出现锁失效,可以在底层资源层做一些互斥保护,作为一个兜底
因此如果是对可靠性要求非常高的应用,不可以把线程安全的问题全部寄托于分布式锁,而是要在资源层也做一些保护,来保证数据真正的安全
而 Redis 中的 RedLock 尽量不使用,因为它为了保证加锁的安全牺牲掉了很多的性能,并且部署成本高(至少部署 5 个 Redis 的主库),使用 Redis 分布式锁建议通过【主从 + 哨兵】部署集群,使用它的分布式锁
最后再说一下关于技术选型的东西,如果进行技术选型的话,如果不是必须引入的话,就不要引入,在进行技术选型的时候,一定要思考确保引入之后利大于弊,因为引入的技术越多,整个系统越复杂,故障的几率就越高,比如如果只是使用到简单的发布订阅功能,也不要求非常高的可靠性,那可能就没有必要进入 RocketMQ
对于项目中使用的任何第三方组件,都是有可能出现故障的,所以在进行技术选型的时候,一定要考虑清楚引入之后带来的技术负担
# Redisson可重入锁加锁源码分析

一般在分布式环境下,需要控制并发安全的地方,基本上都要用到分布式锁,所以分布式锁相关的内容以及实现原理是比较重要的,Redisson 是 Redis 中比较优秀的一个客户端工具,源码写的非常规范,值得我们学习,这里说一下 Redisson 可重入锁 的源码
这里 Redisson 版本使用的是 3.15.5 ,其实版本不重要,主要理解里边的加锁原理即可
# 1、加锁入口
相关的使用就不说了,这里直接看源码,首先是加锁的入口:

public static void main(String[] args) {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6360")
.setPassword("123456")
.setDatabase(0);
//获取客户端
RedissonClient redissonClient = Redisson.create(config);
RLock rLock = redissonClient.getLock("11_come");
rLock.lock();
}
通过 redissonClient 获得 RLock 的锁对象,通过 rLock 的 lock 方法进行,接下来进入 lock() 方法:
// RedissonLock
@Override
public void lock() {
try {
lock(-1, null, false);
} catch (InterruptedException e) {
throw new IllegalStateException();
}
}
// RedissonLock
private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {
long threadId = Thread.currentThread().getId();
// 加锁
Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
// ... 先省略
}
# 2、tryAcquire 尝试加锁
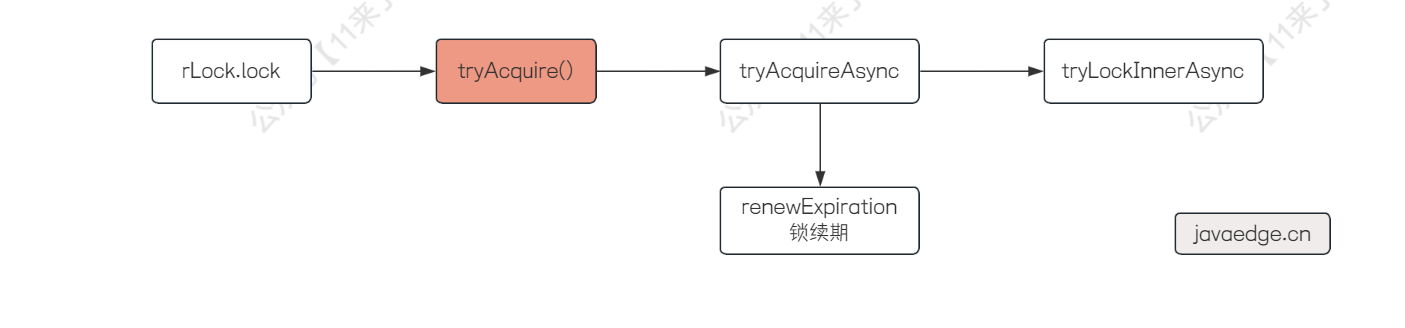
lock() 方法最终就走到了 RedissonLock 实现类中,先去获取了线程 ID 也就是 threadId ,这个其实就是标记到底是哪个线程获取的 Redisson 锁的
之后通过 tryAcquire() 方法尝试获取锁,这个方法就是获取锁的 核心代码 :
// RedissonLock
private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));
}
这里是包含了两层方法,get() 嵌套了 tryAcquireAsync() ,get() 就是阻塞获取异步拿锁的结果
# 3、tryAcquireAsync 异步加锁
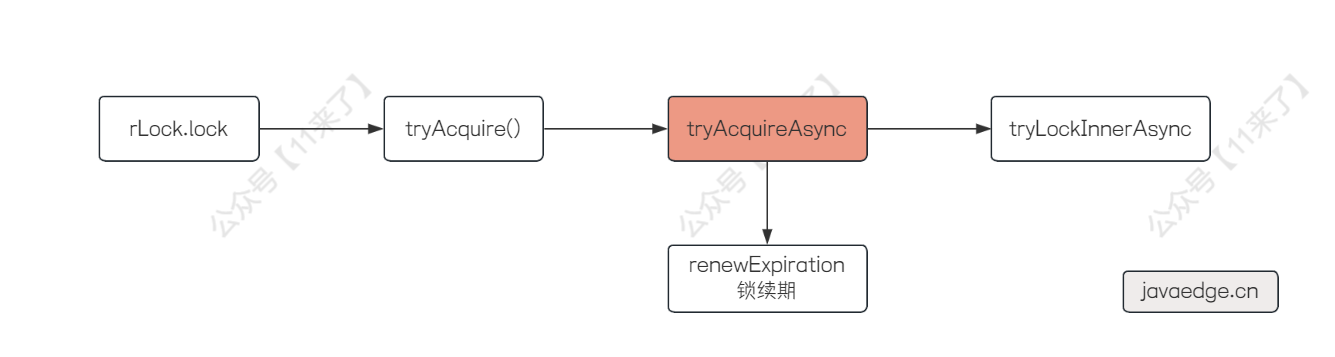
先来看里边的方法尝试异步加锁 tryAcquireAsync() :
// RedissonLock
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
if (leaseTime != -1) {
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
// ... 先省略
}
在 tryAcquireAsync() 方法中,先判断 leaseTime 是否为 -1,我们不指定锁的释放时间的话,默认 leaseTime 就是 -1,于是使用默认的锁释放时间(超过这个时间就会自动释放锁)也就是 30s,接下来进 tryLockInnerAsync() 方法:

// RedissonLock
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}·
这里就是执行一个 lua 脚本,这个 lua 脚本就是加锁的核心代码,主要关注 lua 脚本去 Redis 中 做了哪些事情 ,以及 lua 脚本中的参数 KEYS 和 ARGV 到底是什么
首先看一下 lua 脚本中的参数:
- KEYS :KEYS 参数是一个数组,也就是
Collections.singletonList(getRawName()),这里的KEYS[1]其实就是我们定义的 RLock 的名称11_come - ARGV :ARGV 参数就是 KEYS 参数后边跟的参数了
ARGV[1]是unit.toMillis(leaseTime),也就是锁的释放时间,30000ms 也就是 30sARGV[2]是getLockName(threadId),也就是UUID + “:” + threadId,比如ffa56698-e0f7-4412-ad5a-00669156d187:1
# 4、加锁 lua 脚本
那么参数说完了,这里用 lua 脚本执行加锁的命令其实就是 想通过 lua 脚本来保证命令执行的原子性 ,因为 Redis 处理请求是单线程执行,那么在执行 lua 脚本时,其他请求需要等待,以此来保证原子性
接下来看一下讲一下这个 lua 脚本在做什么事情:
1、第一个 if 分支
首先会去判断 KEYS[1] 这个哈希结构是否存在,也就是我们定义的锁的哈希结构是否存在
如果不存在,也就是 redis.call('exists', KEYS[1]) == 0 ,说明没有线程持有这个锁,就直接执行 redis.call('hincrby', KEYS[1], ARGV[2], 1) 也就是给这个哈希结构中添加一个键值对,value 设置为 1,表示加锁成功,哈希结构如下所示:
"11_come": {
ffa56698-e0f7-4412-ad5a-00669156d187:1: 1
}
再通过 pexpire 设置 key 的过期时间为 30000ms
最后 return nil 也就是返回 null 表示当前线程成功获取到了锁
2、第二个 if 分支
如果 redis.call('hexists', KEYS[1], ARGV[2]) == 1 ,表示 11_come 这个哈希结构存在,并且当前线程的键值对存在于这个哈希结构中,表明当前线程已经已经上过锁了,于是通过 hincrby 命令给键值对的 value + 1,表示重入次数 +1 ,并且使用 pexpire 命令将锁过期时间重置,最后 return nil 表示线程加锁成功
3、第三个 if 分支
如果走到这里了,说明前边两个 if 条件都没满足,也就是 11_come 这个锁的哈希结构已经存在了,并且当前线程的键值对并不在这个哈希结构中,说明是其他线程持有了这个锁,因此当前线程就加锁失败
这里注意一下,加锁失败使用了 pttl 命令来查询 11_come 这个哈希结构的剩余存活时间
为什么加锁失败要返回存活时间呢?不要着急,之后我们会讲到
那么 tryLockInnerAsync() 方法就已经讲完了,这里稍微总结一下,如果当前线程成功加锁的话,就会返回 null ,如果当前线程加锁失败的话,就会返回这个锁的剩余存活时间
那么接下来看一下在执行 tryLockInnerAsync() 加锁之后,还会做一些什么操作
# 5、锁续期
在执行完 tryLockInnerAsync 方法之后,返回了一个 RFuture 对象,这里学过 JUC 的应该都清楚,Future 中就包装了异步操作的执行结果
接下来通过 tlRemainingFuture.onComplete() 其实就是给这个 Future 对象注册了一个监听器,等加锁的异步操作执行完成之后,就执行我们定义的这个监听器中的操作
这个监听器中做要做什么呢?
// RedissonLock
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// 获取锁
if (ttlRemaining == null) {
if (leaseTime != -1) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
在监听器中先判断 ttlRemaining 是否为空,之前我们讲到在 lua 脚本中去加锁,如果加锁成功的话,返回 null ,加锁失败的话,返回这个锁的剩余存活时间
那么这里的 ttlRemaining 就是 lua 脚本的返回值,如果为空的话,表明加锁成功,于是进入这个 if 分支中:
// RedissonLock # tryAcquireAsync
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
// ...
// 获取锁
if (ttlRemaining == null) {
if (leaseTime != -1) {
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
// 锁续期
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
获取锁成功之后,会在这个 if 分支中判断 leaseTime 是否为 -1,我们在加锁的时候没有设置释放时间,因此肯定是 -1,于是 Redisson 会对我们加的锁自动进行续期,进入到 scheduleExpirationRenewal() 方法,这个方法就是对我们加的锁进行 续期 操作:
// RedissonBaseLock(RedissonLock 的父类)
protected void scheduleExpirationRenewal(long threadId) {
ExpirationEntry entry = new ExpirationEntry();
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
oldEntry.addThreadId(threadId);
} else {
entry.addThreadId(threadId);
// 锁续期
renewExpiration();
}
}
可以看到,在这个方法中创建了一个 ExpirationEntry 对象,你也别管这个对象干嘛的,Redisson 底层对锁续期肯定需要存储一些信息,这里就是存储线程的信息,那么创建完这个对象后,就去将这个 Entry 对象放到一个 ConcurrentHashMap 中存放以便在后边取出使用
接下来有个 if 分支,如果这个 Map 原来没有这个 Entry 对象,就将 threadId 放到新创建的这个 Entry 中,并调用 renewExpiration()
这里从 ConcurrentHashMap 中获取这个 Entry 就是根据 EntryName 来获取的,这个 EntryName 其实就是你的 RedissonLock 的 id + name ,也就是:ffa56698-e0f7-4412-ad5a-00669156d187:11_come
那么也就是你第一次来加锁的时候,肯定是没有这个 Entry 的,所以一定会进入到 renewExpiration() 方法中:
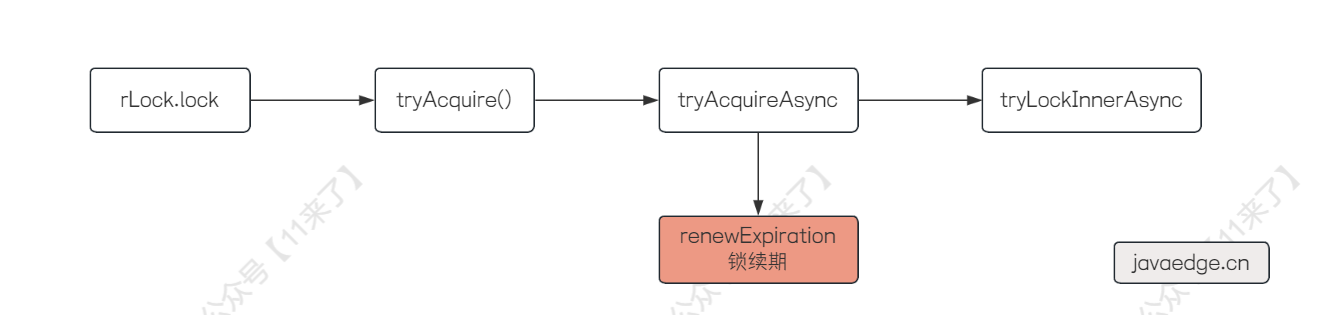
// RedissonBaseLock(RedissonLock 的父类)
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
// 锁续期的定时任务
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
// ...
}, internalLockLeaseTime / 3 /*锁续期的间隔时间*/, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
这个方法就是就是 给锁续期的核心方法 了,因为我们不给锁设置过期时间的话,Redisson 底层会自动去给锁继续宁续期,默认锁过期时间是 30s,那么 Redisson 每隔 1/3 的时间(10s)去判断锁该线程是否还持有锁,如果仍然持有的话,就将锁的过期时间重新设置为 30s
因此在这个方法中就是通过 commandExecutor 来执行一个 TimerTask ,执行任务的间隔时间为 1/3 的锁施放时间,默认就是 10s,这个任务就是对锁进行续期操作,也就是每过 10s,发现当前线程还持有这个锁,就将锁的过期时间重置为 30s :
// RedissonBaseLock(RedissonLock 的父类) # renewExpiration
private void renewExpiration() {
// ...
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 锁续期
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (res) {
// reschedule itself
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3 /*锁续期的间隔时间*/, TimeUnit.MILLISECONDS);
}
这个方法中有一些零碎的细节逻辑,个人觉得没必要看,所以这里直接省略掉了,因为我们只是去了解他加锁以及锁续期的原理是怎样的,而不是真正要去实现这个功能,这里直接看核心代码 renewExpirationAsync():
// RedissonBaseLock(RedissonLock 的父类)
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
在这里就是执行一个 lua 脚本:
1、通过 hexists 判断当前线程加的锁是否存在,跟之前加锁的 lua 脚本差不多,这里就不再赘述
2、如果存在的话,说明当前线程还持有这个锁,于是通过 pexpire 重置过期时间,完成锁续期操作,并返回 1
3、如果不存在,说明当前线程已经不持有这个锁了,显然不需要续期,于是返回 0 即可
那么上边执行完锁续期这个操作之后,这个定时任务就结束了,下一次怎么进行锁续期呢?
// RedissonBaseLock(RedissonLock 的父类)
private void renewExpiration() {
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
// ...
future.onComplete((res, e) -> {
// ...
if (res) {
// 如果锁续期成功,继续调用锁续期的代码,来实现不断锁续期
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
可以看到在锁续期成功之后,又重新调用了 renewExpiration() 方法,再次执行锁续期的操作
# 6、可重入锁加锁流程总结
那么至此呢,Redisson 的可重入加锁的源码流程就分析完毕了,这里再对整个流程做一下梳理:
首先,通过 lock() 进行加锁,加锁最终是走到执行 lua 脚本的地方,通过在 Redis 中的哈希结构 存入当前线程的键值对来实现加锁,key 是 RedissonLock.id + threadId,value 就是 1
那么在加锁成功之后,我们如果没有指定锁的释放时间的话,Redisson 底层默认设置为 30s
并且会启动一个定时任务进行 锁续期 ,也就是只要我们当前线程持有锁,就会隔一段时间对这个锁进行续期操作,锁续期操作的执行间隔默认为锁释放时间的 1/3(10s)
可以看到,整个 Redisson 中可重入锁加锁的流程还是比较简单的,主要比较核心的功能为:
(1)通过 Redis 的哈希结构 进行加锁,并实现不同线程之间的锁互斥(通过 threadId 标识锁信息)
(2)如果不指定锁的释放时间,会启动定时任务去进行 锁续期 ,每隔 10s 续期一次,最后通过 lua 脚本执行的
(3)可重入锁 就是通过 hincrby 来对哈希结构中的键值对 +1 实现重入的
# 可重入锁加锁不成功怎么办?
之前说可重入锁加锁的源码时,只讲了客户端加锁成功的流程,如果当前的锁已经被其他客户端锁占有了,当前客户端是会加锁失败的,那么枷锁失败的话,当前客户端是会去停止等待一段时间的
// RedissonLock
private void lock(long leaseTime, TimeUnit unit, boolean interruptibly) throws InterruptedException {
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
// ... 省略 subscribe 的一些方法,不是核心逻辑
try {
while (true) {
ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
break;
}
// waiting for message
if (ttl >= 0) {
try {
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
if (interruptibly) {
throw e;
}
future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
}
}
}
// ...
}
}
在调用 lock 方法后会走到 ReidssonLock 的 lock 方法中,这里可以看到会先通过 tryAcquire() 尝试加锁,该方法返回 ttl
大家应该还记得,在最后执行加锁的是一段 lua 脚本:
- 加锁成功的话,返回 null
- 加锁失败的话,返回锁的剩余存活时间
那么这里在 tryAcquire() 之后就会进入到 while 死循环中,判断 ttl 是否为空,如果 ttl == null ,说明获取锁成功就直接退出循环即可
如果 ttl 不是空,说明锁已经被其他客户端占有了,此时 ttl 为锁的剩余存活时间,那么我们当前这个客户端可以等待 ttl 之后,再去尝试获取锁,也就是 future.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS) 这一行代码,getLatch() 的话是获取一个信号量 Semaphore,通过这个信号量阻塞 ttl 的时间 ,再次通过 tryAcqure() 尝试获取锁
因此如果获取锁失败之后,当前客户端会去等待 ttl 的时间,再次尝试去获取锁
这里阻塞使用 Semaphore,最后底层也是走到了 AQS 中去,具体的细节这里先不了解,毕竟主干流程是分布式锁
# Redisson公平锁加锁源码分析
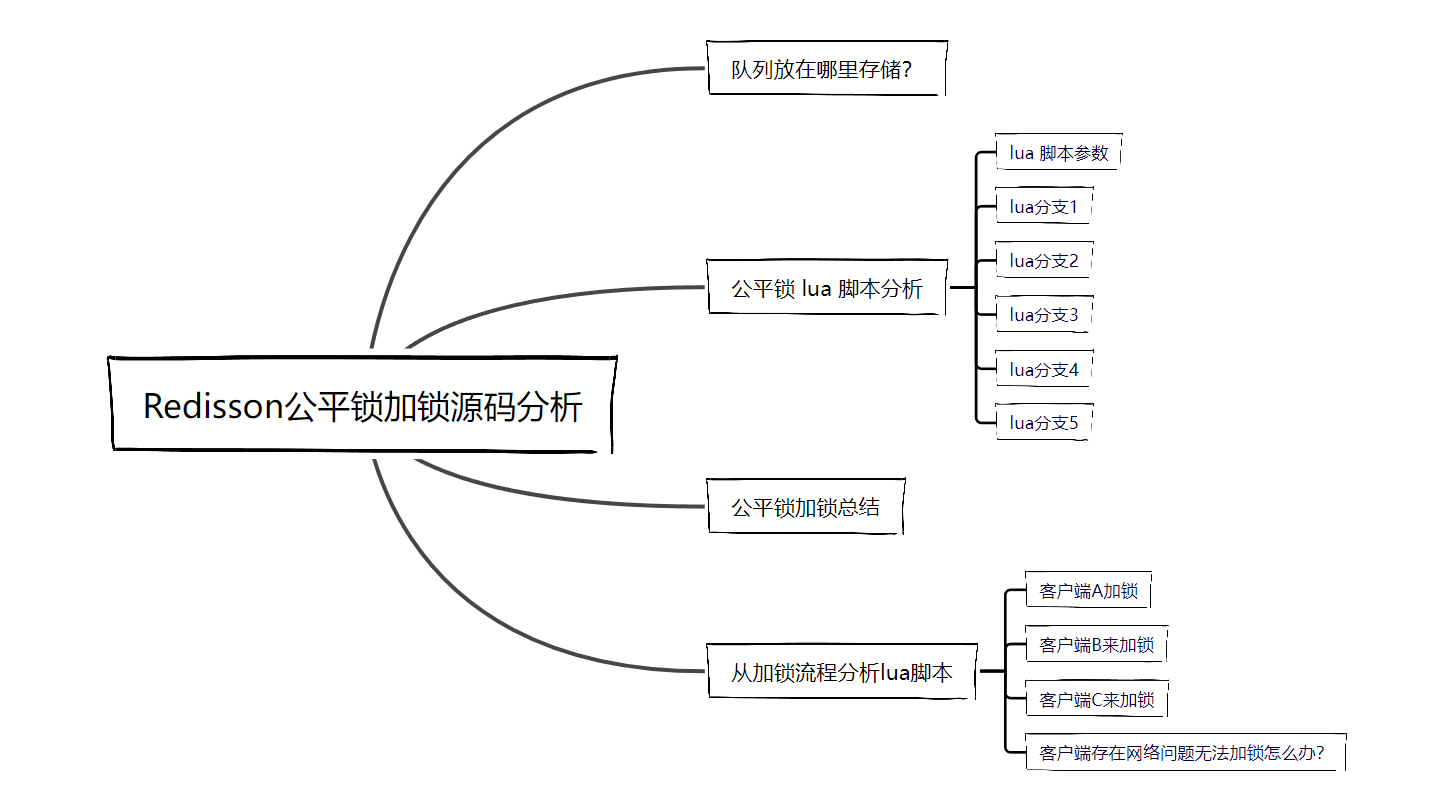
上一篇说了 可重入锁 加锁的流程,这个可重入锁其实就是非公平锁,非公平体现在哪里呢?
体现在当前客户端如果抢锁失败的话,会拿到这个锁的剩余存活时间,会进行等待,等待之后再次去尝试加锁,里边是没有任何排队的逻辑的,因此是非公平锁
首先还是将使用的代码给放上:
public static void main(String[] args) throws InterruptedException {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
.setPassword("123456")
.setDatabase(0);
//获取客户端
RedissonClient redissonClient = Redisson.create(config);
RLock fairLock = redissonClient.getFairLock("fair_11_come");
fairLock.lock();
}
# 队列放在哪里存储?
Redisson 的公平锁和非公平锁的区别只在最终执行的 lua 脚本有区别,所以这里就只说 最后的 lua 脚本是怎么实现公平锁的!
首先来思考一下,要实现公平锁肯定是需要一个队列的,那这个队列放在哪里存储呢?
可以放在本地吗? 肯定不行,因为 Redisson 分布式锁使用在分布式环境下的,放在本地其他节点都感知不到,当然不行
因此,这个队列还是放在分布式缓存 Redis 中比较合适,毕竟锁也是在 Redis 中记录的,将队列也放在 Redis 中也不用引入其他的技术栈,并且可以通过 lua 脚本执行,来保证原子性
# 公平锁 lua 脚本分析
公平锁的加锁流程最终会走到 RedissonFairLock # tryLockInnerAsync() 方法中,在该方法中执行 lua 脚本进行排队、加锁等一系列操作,因此这个 lua 脚本是比较长的,而关于这个 lua 脚本网上也有许多讲解的,这里直接将注释贴在 lua 脚本上,接下来通过画图的方式讲解这个公平锁的加锁以及排队流程
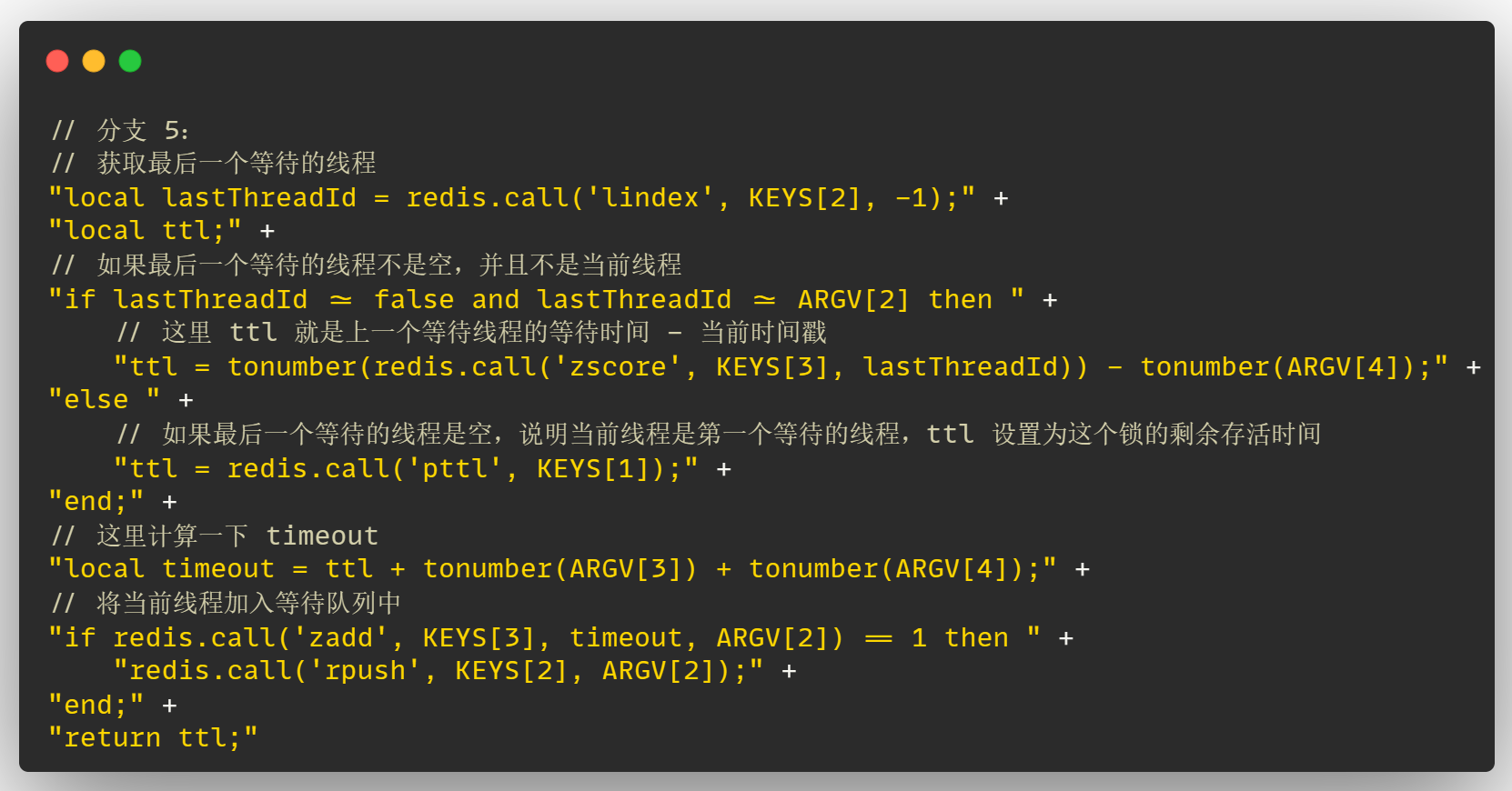
接下来为了保证阅读起来比较方便,将这个 lua 脚本分为 5 个分支来讲
# lua 脚本参数
这个 lua 脚本中有一些参数,这里先介绍一下这些参数是什么:
KEYS[1]:锁的名称,即fair_11_comeKEYS[2]:Redis 中的等待队列名称,即redisson_lock_queue:{fair_11_come}KEYS[3]:Redis 中的 Set 有序集合名称,超时时间作为 score 进行排序,即redisson_lock_timeout:{fair_11_come}ARGV[1]:默认的锁释放时间,即30000msARGV[2]:UUID + threadId,用于标识具体加锁线程,即54a63d7a-926a-4ef8-9155-3f5769a10a1f:1ARGV[3]:线程等待的时间,即300000msARGV[4]:当前的时间戳,即1709556953230
有了这些参数,接下来看 lua 脚本就清晰很多了,这里我先将这 5 个分支的 lua 脚本以及注释贴出来,这里先不细说 lua 脚本,大家可以直接跳过这个 lua 脚本看后边的客户端加锁案例, 根据客户端加锁案例来理解加锁的流程,通过加锁案例来理解 lua 脚本为什么这么设计!
# 分支1

# 分支2
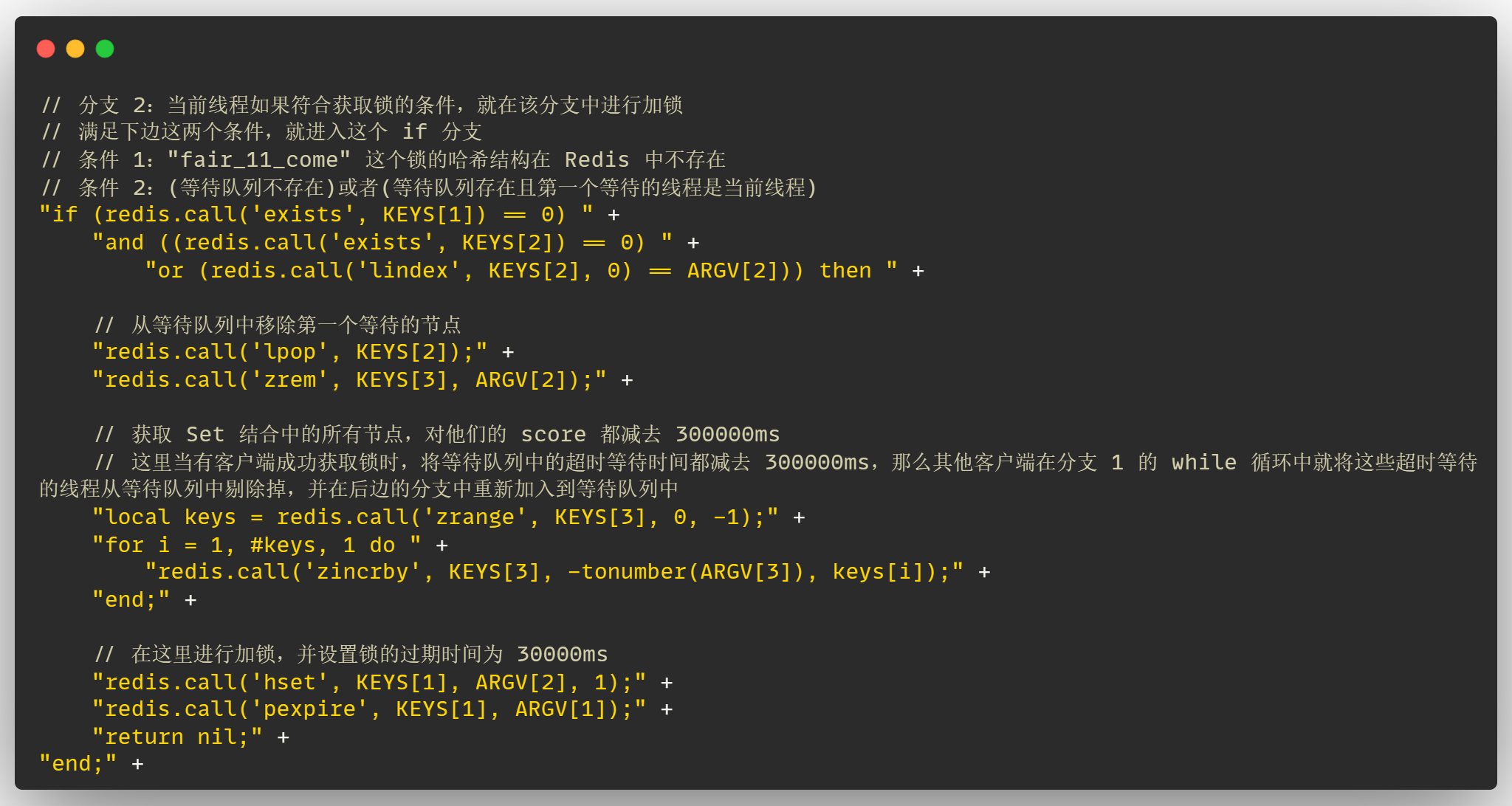
# 分支3

# 分支4

# 分支5
# 从加锁流程分析 lua 脚本
这里从加锁流程来分析上边的 lua 脚本,来理解整个公平锁的加锁流程是怎样的,假设有 3 个客户端:A、B、C
这里假设加的公平锁的名称为 fair_11_come
# 客户端 A 加锁
此时加入客户端 A 第一个过来加锁,到【分支1】,毫无疑问会从 while 循环中跳出来,因为等待队列中根本就没有等待线程,于是向下继续执行
到【分支2】,客户端 A 发现在 Redis 中不存在 fair_11_come 这个哈希结构, 并且等待队列中也没有等待线程,于是客户端 A 可以加锁,通过 hset 进行加锁,并且设置 过期时间为 30000ms ,也就是 30s,此时 Redis 中存在了该哈希结构如下:
"fair_11_come": {
"UUID_A + threadId_A": "1"
}
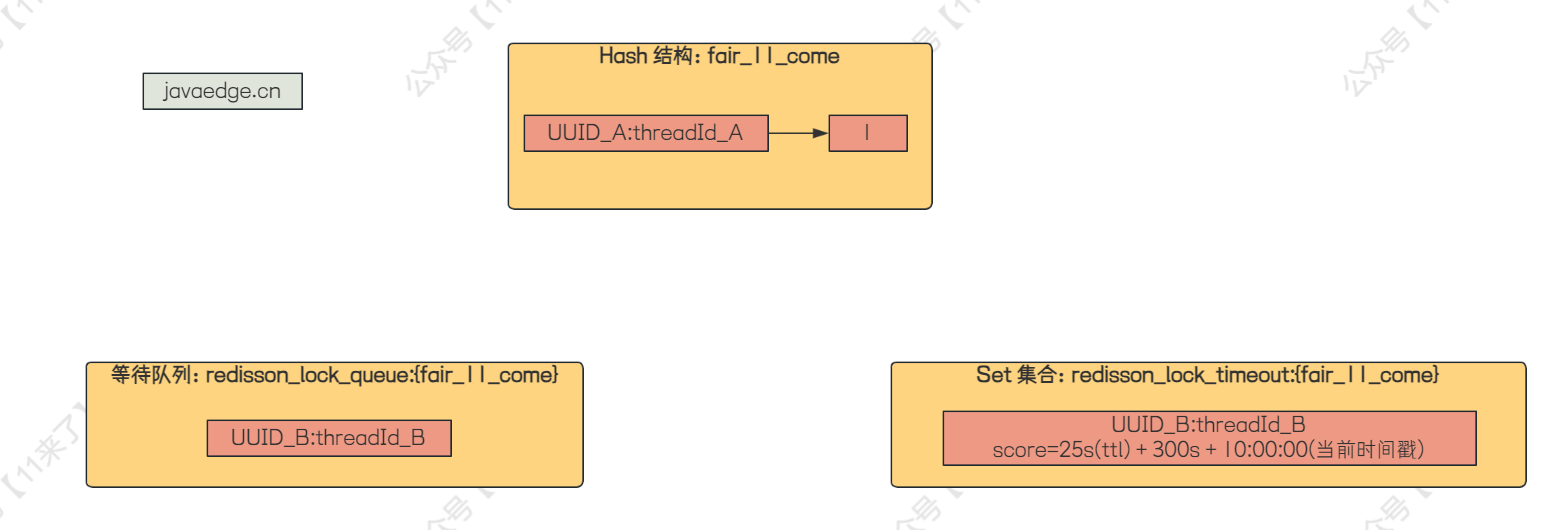
# 客户端 B 来加锁
那么此时如果客户端 B 来加锁,假设此时 A 还没有释放锁
那么 B 走到 【分支1】,也会从 while 循环中跳出来,因为等待队列为空
到【分支2】,发现这个哈希结构已经存在了,说明锁被其他客户端线程占有了,于是跳过【分支2】
到【分支3】,发现不是重入锁,跳过【分支3】
到【分支4】,取当前线程的等待时间,由于还没有加入等待队列中,所以取出来是空,跳过【分支4】
到【分支5】,获取最后一个等待线程,发现为空,此时 ttl 为这个 fair_11_come 这个锁的剩余存活时间,这里假设为 ttl 为 25s,那么计算出来的 timeout 的值为 ttl + ARGV[3] + ARGV[4] 也就是 ttl + 300000ms + 当前时间戳 ,假设当前时间为 10:00:00
于是将当前节点加入等待队列中,这里假设客户端 B 的线程标识为 UUID_B:threadId_B ,此时 Redis 中锁结构以及等待队列如下:
# 客户端 C 来加锁
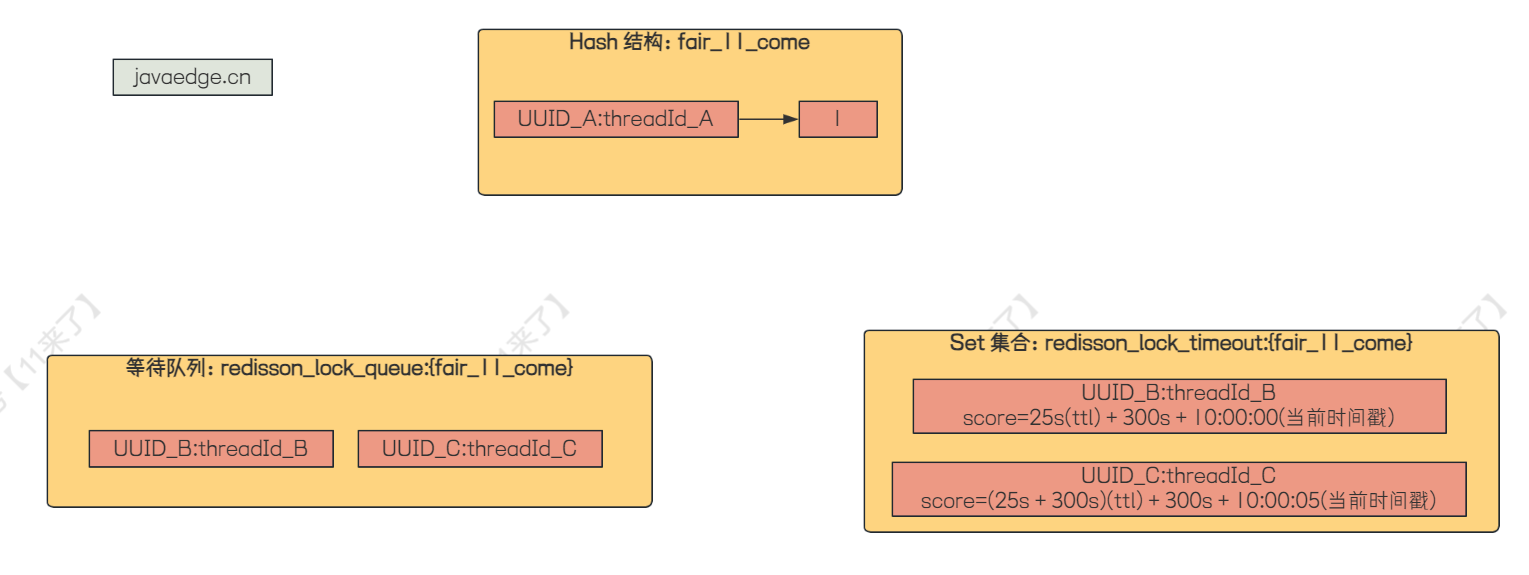
此时假设客户端 C 来加锁,首先到【分支1】,发现没有等待超时的节点,于是退出 while 循环
到【分支2】,发现这个哈希结构已经存在了,说明锁被其他客户端线程占有了,于是跳过【分支2】
到【分支3】,发现不是重入锁,跳过【分支3】
到【分支4】,取当前线程的等待时间,由于还没有加入等待队列中,所以取出来是空,跳过【分支4】
到【分支5】,取出最后一个等待线程,发现不是空,说明前边有线程在等待了,此时 ttl 为 前一个等待线程的 score - ARGV[4] ,前一个节点也就是 B 的 score 为 25s + 300s + 10:00:00,再减去 ARGV[4] = 10:00:00
于是客户端 C 的 ttl 为 25s + 300s
接下来计算客户端 C 的 timeout = ttl + 300s + 当前时间戳 ,假设当前时间为 10:00:05 ,那么客户端 C 的 timeout = (25s+300s) + 300s + 10:00:05
我们可以发现,这里客户端 C 的 timeout 也就是 score 每进入一个节点排队都会多加一个 300s,所以在【分支2】中,如果有线程获取锁的话,会遍历这个 Set 集合将所有节点的 score 都减去 300s
并且将客户端 C 加入等待队列:
那么至此正常的加锁流程就已经说完了
# 客户端存在网络问题无法加锁怎么办?
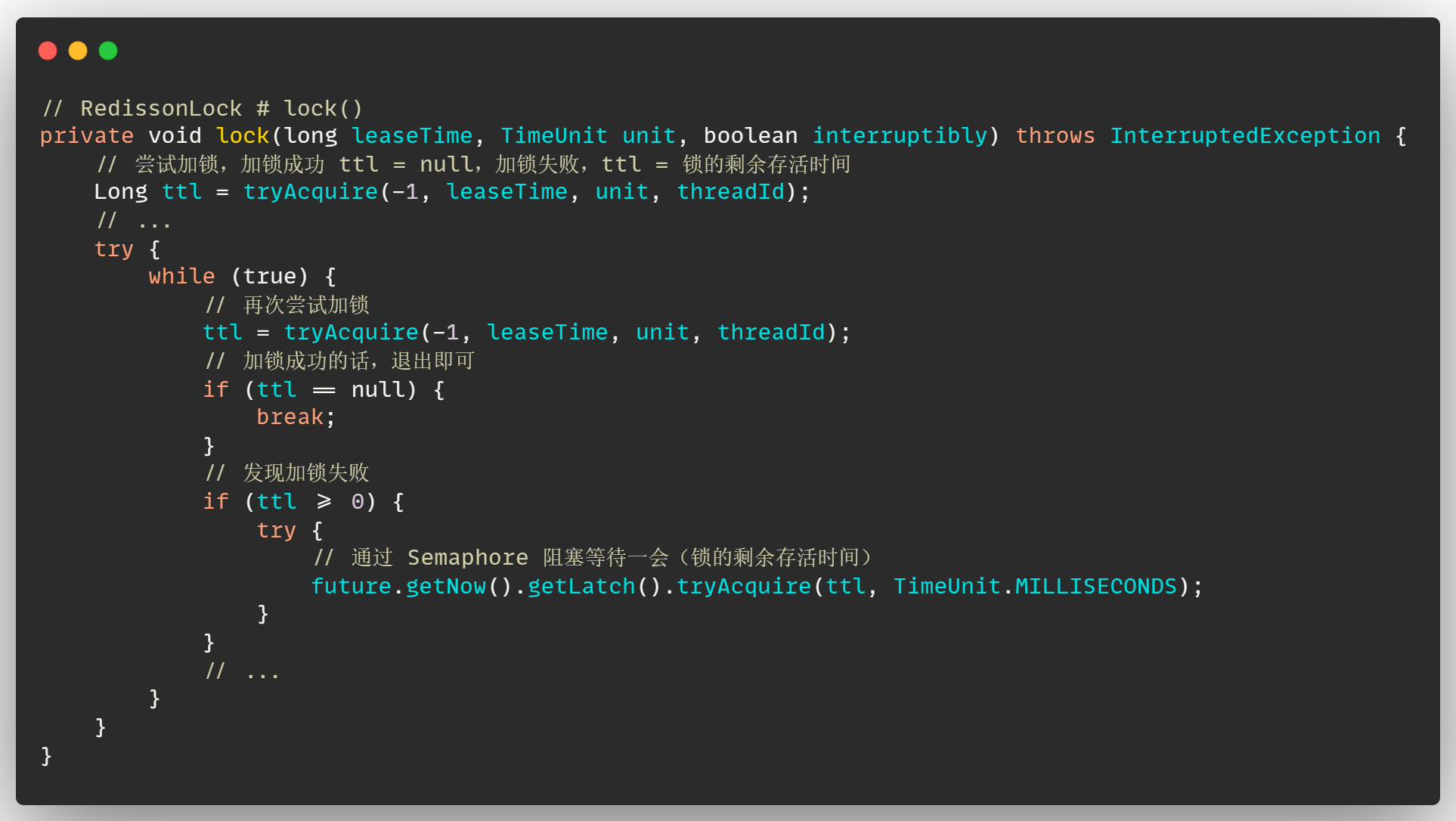
但是除了这些正常情况,还会存在异常情况,如果轮到某一个客户端加锁了,但是该客户端网络存在异常,导致无法加锁,那么肯定不能让这个客户端在等待队列中一直等,从而导致后边的客户端线程也无法加锁,
这些 Redisson 都考虑到了,会给每一个客户端线程设置一个最长的等待时间,每个线程进入队列之后,最多允许等待【锁的剩余存活时间 + 300s】,所以每当有线程进入【分支1】的 while 循环中,如果发现队列中的线程已经【等待超时】了,说明这个线程可能存在网络问题,也可能是锁一直被占有没有释放,那么直接就将这个线程扔出队列即可
- 那么被扔出去的线程如何再次加入队列呢?
在这个 lua 脚本中,如果加锁失败,在【分支4】中会返回锁的剩余存活时间,之后会在 RedissonLock # lock() 方法中进入到 while 循环,在这个 while 循环中通过信号量 Semaphore 来阻塞等待一会(锁的剩余存活时间),等待完之后,再次尝试去加锁就可以了
如果客户端被扔出队列了之后,就会在这个 lock 方法中的 while 循环中一直尝试去加锁,最后走到 lua 脚本中,会将自己重新加入到等待队列中进行等待
这里在将可重入锁的时候已经说过了,为了避免忘记还是将代码再贴一下:
# 公平锁加锁总结
最后总结一下公平锁的加锁流程
公平锁的排队主要是靠 等待队列 来实现公平的,这个等待队列就是 Redis 中的列表,并且为了避免网络有问题的客户端一直在队列中,导致其他客户端线程无法获取锁的情况,因此还通过一个 有序 Set 集合 来存储每个排队客户端线程的超时等待时间,每个客户端线程最多等待【锁的剩余存活时间 + 300s】
公平锁的 lua 脚本虽然比较长,有 5 个分支,但是每个分支的功能其实是很明确的,这里再归纳一下:
【分支1】:从任务队列中剔除等待超时的节点
【分支2】:如果锁未被占有,并且自己是第一个等待锁的线程,就直接加锁
【分支3】:执行重入逻辑
【分支4】:如果当前客户端线程已经在等待队列中了,就返回实际需要等待的时间,也就是锁的剩余存活时间,返回这个时间就是方便在获取锁失败之后,阻塞等待这个时间之后,再来重试加锁
【分支5】:如果当前线程获取锁失败,就将自己加入到等待队列中,并且将等待超时时间设置到 Set 集合中去
# 完整的 lua 脚本
// 分支 1:while 循环,主要是将等待队列中已经【等待超时】的线程给扔出去
// 因为这些线程可能因为网络问题而无法获取锁,如果网络没有问题的话,这些线程会再次将自己加入到等待队列的
"while true do " +
// 从等待队列中取出第一个等待的线程
"local firstThreadId2 = redis.call('lindex', KEYS[2], 0);" +
// 如果为空的话,说明队列中没有线程等待了,那么自己就可以跳出 while 循环出去获取锁了
"if firstThreadId2 == false then " +
"break;" +
"end;" +
// 如果不为空的话,从 Set 集合中取出这个线程的 score 值,也就是它的等待超时的时间
"local timeout = tonumber(redis.call('zscore', KEYS[3], firstThreadId2));" +
// 如果超时时间 <= 当前时间戳的话,说明已经过了这个线程的等待超时时间,于是将这个线程直接从等待队列中扔出去,为什么要扔出去呢,因为这个线程可能因为网络问题无法获取锁了,就将他扔出去,当这个线程网络恢复之后还是会将自己加入到等待队列中去的
"if timeout <= tonumber(ARGV[4]) then " +
"redis.call('zrem', KEYS[3], firstThreadId2);" +
"redis.call('lpop', KEYS[2]);" +
// 如果超时时间 > 当前时间戳的话,说明队列中的第一个线程还没有等待超时,因此当前线程直接跳出 while 循环,接着向下走其他分支即可
"else " +
"break;" +
"end;" +
"end;" +
// 分支 2:当前线程如果符合获取锁的条件,就在该分支中进行加锁
// 满足下边这两个条件,就进入这个 if 分支
// 条件 1:"fair_11_come" 这个锁的哈希结构在 Redis 中不存在
// 条件 2:(等待队列不存在)或者(等待队列存在且第一个等待的线程是当前线程)
"if (redis.call('exists', KEYS[1]) == 0) " +
"and ((redis.call('exists', KEYS[2]) == 0) " +
"or (redis.call('lindex', KEYS[2], 0) == ARGV[2])) then " +
// 从等待队列中移除第一个等待的节点
"redis.call('lpop', KEYS[2]);" +
"redis.call('zrem', KEYS[3], ARGV[2]);" +
// 获取 Set 结合中的所有节点,对他们的 score 都减去 300000ms
// 这里当有客户端成功获取锁时,将等待队列中的超时等待时间都减去 300000ms,那么其他客户端在分支 1 的 while 循环中就将这些超时等待的线程从等待队列中剔除掉,并在后边的分支中重新加入到等待队列中
"local keys = redis.call('zrange', KEYS[3], 0, -1);" +
"for i = 1, #keys, 1 do " +
"redis.call('zincrby', KEYS[3], -tonumber(ARGV[3]), keys[i]);" +
"end;" +
// 在这里进行加锁,并设置锁的过期时间为 30000ms
"redis.call('hset', KEYS[1], ARGV[2], 1);" +
"redis.call('pexpire', KEYS[1], ARGV[1]);" +
"return nil;" +
"end;" +
// 分支 3:如果当前线程的键值对在 "fair_11_come" 这个哈希结构中存在的话,说明是重入了,直接重入次数 + 1 即可
"if redis.call('hexists', KEYS[1], ARGV[2]) == 1 then " +
"redis.call('hincrby', KEYS[1], ARGV[2],1);" +
"redis.call('pexpire', KEYS[1], ARGV[1]);" +
"return nil;" +
"end;" +
// 分支 4:走到这里的话,说明分支 2 和分支 3 都不满足,也就是当前线程既不是第一个等待的线程,又不是发生重入
// 获取当前线程在 Set 集合中的 score,也就是等待超时时间
"local timeout = redis.call('zscore', KEYS[3], ARGV[2]);" +
// 如果 timeout 不是 false 的话,也就是这个当前线程已经在等待了
"if timeout ~= false then " +
// 加锁失败,返回锁的存活时间,这里要减去这两个参数是因为 timeout = 锁的剩余存活时间+ARGV[3]+ARGV[4],这里减去这两个参数就返回锁的剩余存活时间了
"return timeout - tonumber(ARGV[3]) - tonumber(ARGV[4]);" +
"end;" +
// 分支 5:
// 获取最后一个等待的线程
"local lastThreadId = redis.call('lindex', KEYS[2], -1);" +
"local ttl;" +
// 如果最后一个等待的线程不是空,并且不是当前线程
"if lastThreadId ~= false and lastThreadId ~= ARGV[2] then " +
// 这里 ttl 就是上一个等待线程的等待时间 - 当前时间戳
"ttl = tonumber(redis.call('zscore', KEYS[3], lastThreadId)) - tonumber(ARGV[4]);" +
"else " +
// 如果最后一个等待的线程是空,说明当前线程是第一个等待的线程,ttl 设置为这个锁的剩余存活时间
"ttl = redis.call('pttl', KEYS[1]);" +
"end;" +
// 这里计算一下 timeout
"local timeout = ttl + tonumber(ARGV[3]) + tonumber(ARGV[4]);" +
// 将当前线程加入等待队列中
"if redis.call('zadd', KEYS[3], timeout, ARGV[2]) == 1 then " +
"redis.call('rpush', KEYS[2], ARGV[2]);" +
"end;" +
"return ttl;"
# Redisson读写锁加锁机制分析
前几篇说了 Redisson 的可重入锁和公平锁是如何实现的
这里来讲一下 Redisson 的读写锁是如何实现的,这里在具体学习源码的时候,不要去具体扣他每一行的命令到底是执行的什么操作,扣这些细节是没有意义的
那么我们要学习源码中的哪些内容呢?
主要是要学习它的 设计思想 ,也就是为了实现功能做了哪些设计,以及实现的 流程 ,了解原理就好了!
# 读锁加锁流程
这里我们先来看读写锁中的 读锁 的加锁流程,首先还是先从调用入口进入:
public static void main(String[] args) throws InterruptedException {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
.setPassword("123456")
.setDatabase(0);
//获取客户端
RedissonClient redissonClient = Redisson.create(config);
// 获取读写锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("11_come");
// 获取读锁
readWriteLock.readLock().lock();
//关闭客户端
redissonClient.shutdown();
}
这里其实 lock() 方法还是进入了 RedissonLock 的 lock() 方法,而读锁和之前说的可重入锁的区别就在于最底层加锁的方法,也就是最终的 tryLockInnerAsync() 方法不同,接下来进入 读写锁的加锁方法 查看:
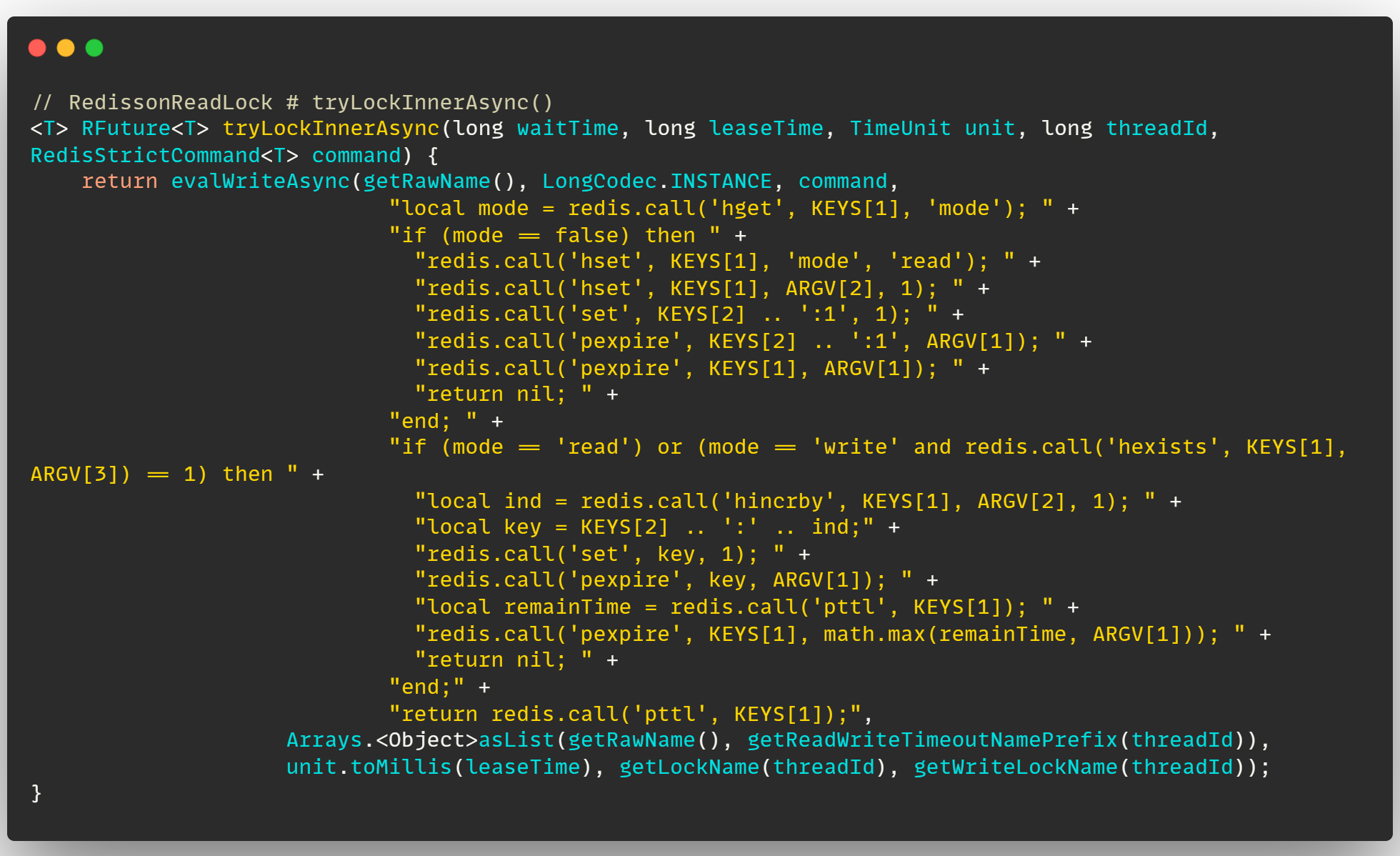
整体的加锁方法如上,这里先说参数含义,之后来说一下这个 lua 脚本在做什么事情:
- KEYS[1] :读写锁的名称, 也就是
11_come - KEYS[2] :读锁超时时间的前缀,用来表示每一把读锁,也就是
{11_come}:23d25595-6532-4105-a24b-98fea0997bc5:1:rwlock_timeout - ARGV[1] :锁的释放时间,默认是
30000ms,也就是30s - ARGV[2] :锁的标识,也就是当前客户端线程的唯一标识,
UUID+threadId,即23d25595-6532-4105-a24b-98fea0997bc5:1
接下来在说 lua 脚本之前,先说一下 读写锁的特性 ,即:
- 读锁和读锁之间不互斥
- 读锁和写锁之间互斥
- 写锁和写锁之间互斥
# 读锁分支1
那么 Redisson 为了实现读写锁的这三个特性,一定要有一个标识,来表明当前加的锁是读锁还是写锁对吧,这样才可以继续来判断是否要进行互斥操作
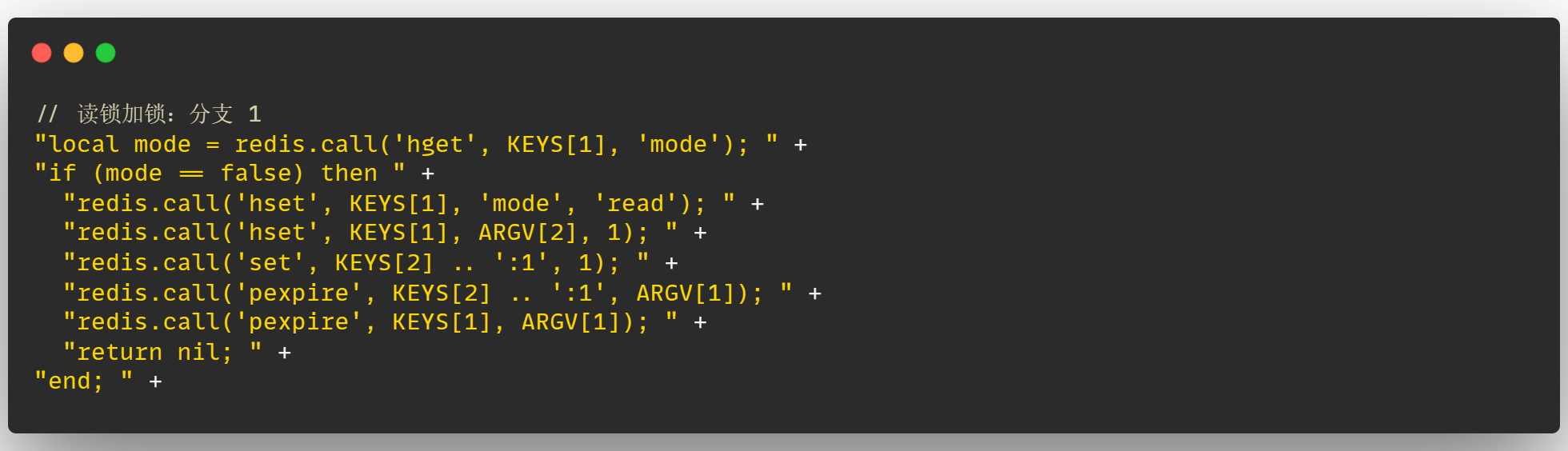
在读锁加锁的第一个分支中,可以看到先去获取 KEYS[1] 中的 mode 属性值了,这个属性值就存储了当前加的锁是读锁还是写锁
如果发现 mode == false 的话,说明没有上锁,当前客户端就可以成功上锁
这里在客户端上锁时,设置了 3 个属性值,加锁之后,在 Redis 中存储的锁信息如下图:

hset KEYS[1] mode read):目的是表明当前锁是写锁还是读锁hset KEYS[1] ARGV[2] 1):将当前客户端线程的lockName:UUID+threadId设置到锁的哈希结构中,value 是该锁的重入次数set KEYS[2] .. ':1' 1):设置一个键值对,用来 标识每一把锁的超时时间 。这里的..在 lua 脚本中的含义是进行字符串拼接,因此 key 是"KEYS[2]:1",即{lockName}:UUID:threadId:{number},这里的 number 表示是重入的第几把锁,如果是第二次重入的锁,number 就为 2这里为什么要设置这个键值对呢,是为了避免在锁释放之后,读写锁的超时时间和读锁的超时时间出现不一致,具体解释可以看后边的 【键值对对每个锁的超时时间标识】
# 读锁分支2
接下来说一下读锁加锁的【分支2】
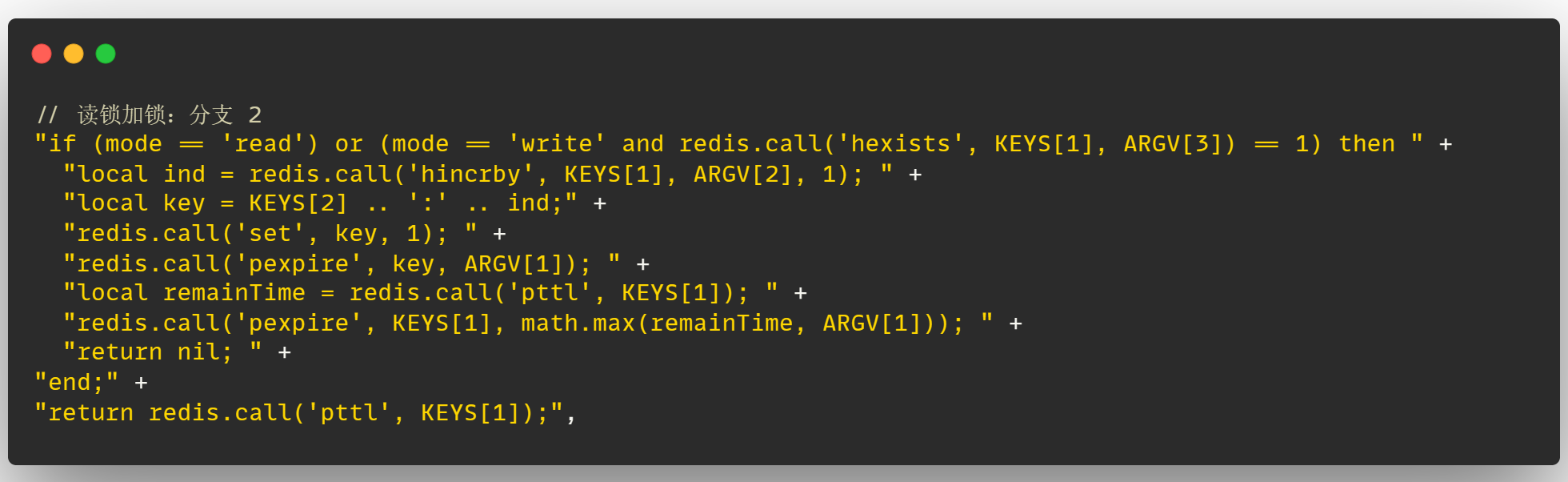
在【分支1】中如果发现锁并没有被其他客户端线程获取的话,就会直接上锁
如果锁已经被其他客户端线程获取时,此时有两种情况:
- 其他客户端线程获取的是读锁,读锁之间不互斥,因此可以获取锁
- 其他客户端获取的锁是写锁,并且发现当前客户端线程的信息在锁的哈希结构中存在,说明是发生了写锁重入
那么在这两种情况下都可以获取锁,在这个【分支 2】中就先通过 hincrby 来对锁的重入次数 +1,并且通过 set 命令将当前线程的信息设置到 Redis 中
这里 set 命令是存储了 key,1 这个键值对这个 key 其实就是 KEYS[2] .. ':' .. ind ,在 lua 脚本中 .. 的含义就是进行字符串拼接,因此这里的 key 就是 KEYS[2]:ind ,这里 ind 的含义是当前锁是重入的第几次,比如是第二次重入,那么 ind = 2
可以看到,整个读锁加锁的流程是比较简单的,主要是了解一下这里对于读锁加锁有在 Redis 中存储的信息
这里再啰嗦一下 Redis 中存储的锁信息为:
- 读写锁的哈希结构:包括了读写锁的类型、每把锁的唯一标识以及重入次数
- 键值对:主要作用就是标识每一把读锁的超时时间
# 根据实际加锁案例来学习读锁加锁的流程
那么假设有一个客户端先来 加读锁 ,那么加锁之后,Redis 中存储的锁信息如下:
可以看到在 KEYS[1] 这个哈希结构中,ARGV[2] 这个键值对主要来标识当前读锁的重入次数
而下边的 KEYS[2]:1 这个键值对则主要来对每一个锁的超时时间进行标识,通过这个键值对就可以获取不同读锁的剩余存活时间
上边说了一个客户端来加锁的情况,假设此时有另一个客户端 B 来加读锁,那么此时 Redis 中的锁结构将变为:
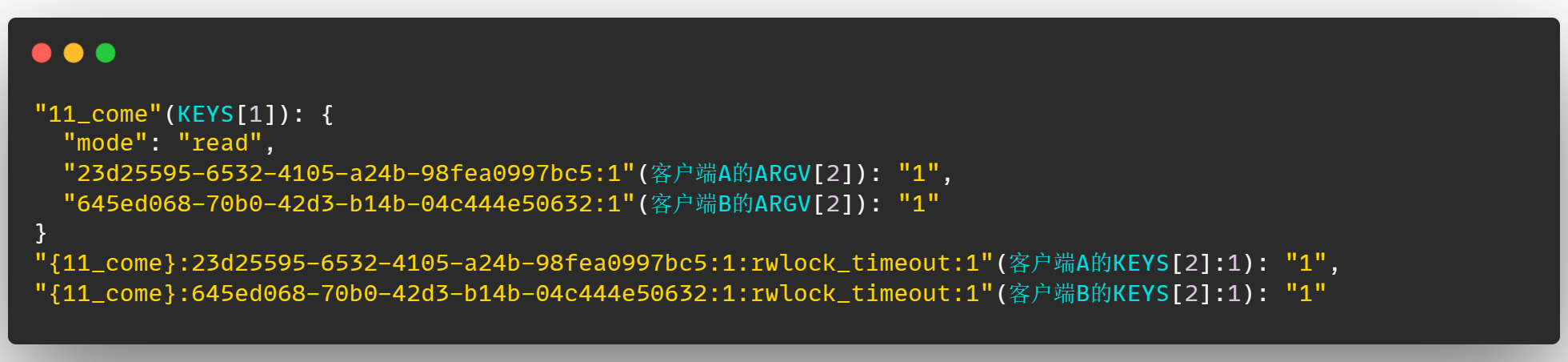
可以看到这里客户端 A 和 B 的分布式锁的 UUID 不同,因此在读写锁 11_come 的哈希结构中出现了两把锁的标识
那么如果此时客户端 A 再次加锁,也就是发生同一把锁的重入,此时 Redis 的锁结构将变为:
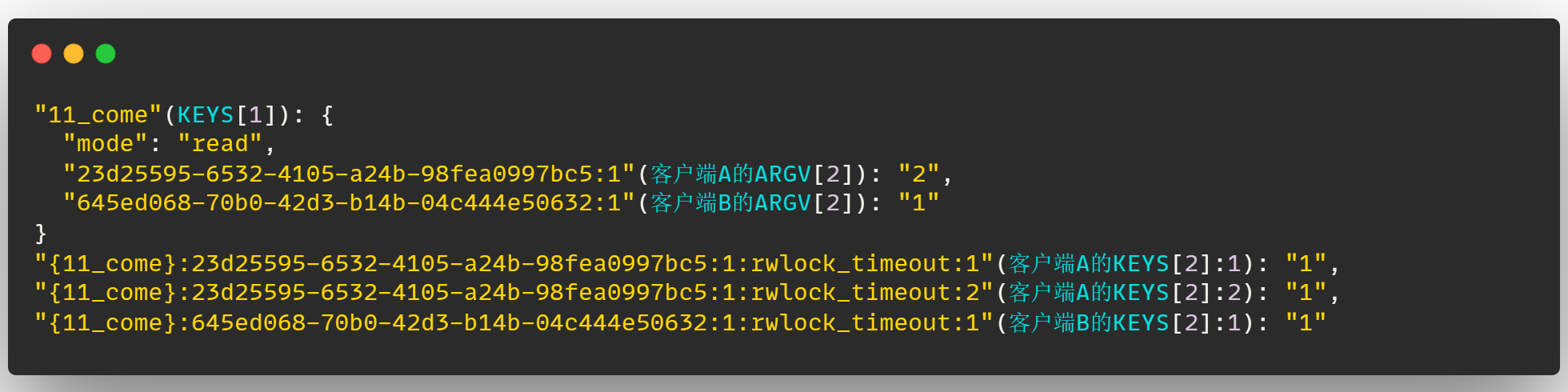
可以看到当发生 锁重入 的时候,会先在锁的哈希结构中,将锁的重入次数 + 1
并且新增加一个键值对 "{11_come}:23d25595-6532-4105-a24b-98fea0997bc5:1:rwlock_timeout:2"(客户端A的KEYS[2]:2): "1" ,这里是客户端 A 重入的
来表示重入的这把锁的超时时间
在 Redisson 中,哈希结构中的键值对主要用来存储每把锁的重入次数,而外边的键值对主要用来存储每把锁的超时时间
那么到了这里应该对读锁的加锁流程,以及在 Redis 中锁信息的存储结构就有比较清楚的了解了
# 为什么要对每个锁的超时时间进行标识?
这里再说一下为什么要给每一个客户端线程都创建一个键值对来标识每个锁的超时时间,如下:

这个键值对的超时时间其实只有在读锁释放的时候才使用得到,接下来举一个例子:
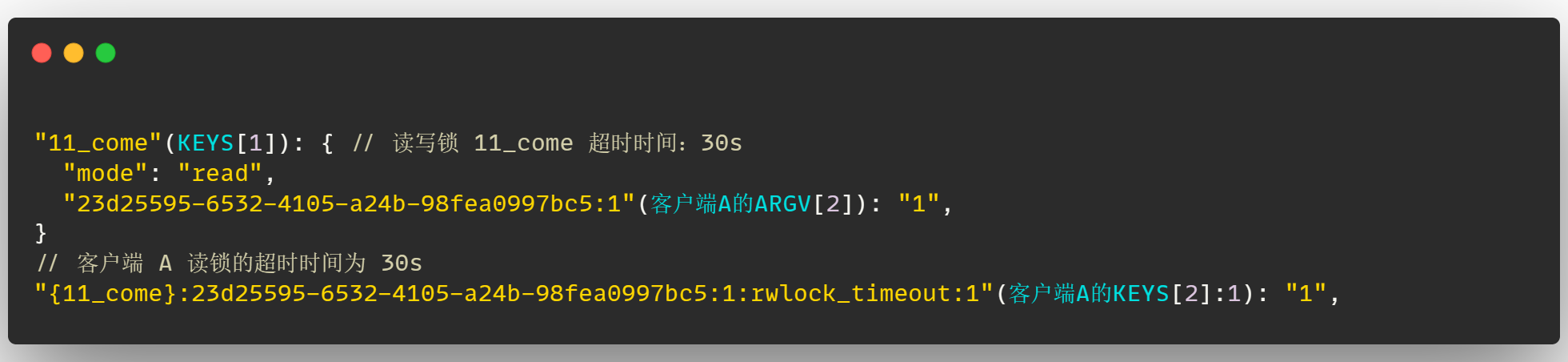
比如说客户端 A 创建一把读锁,此时读锁超时时间默认为 30s,此时读写锁 11_come 的超时时间为 30s,并且客户端 A 创建的这把读锁的超时时间也为 30s,如下:
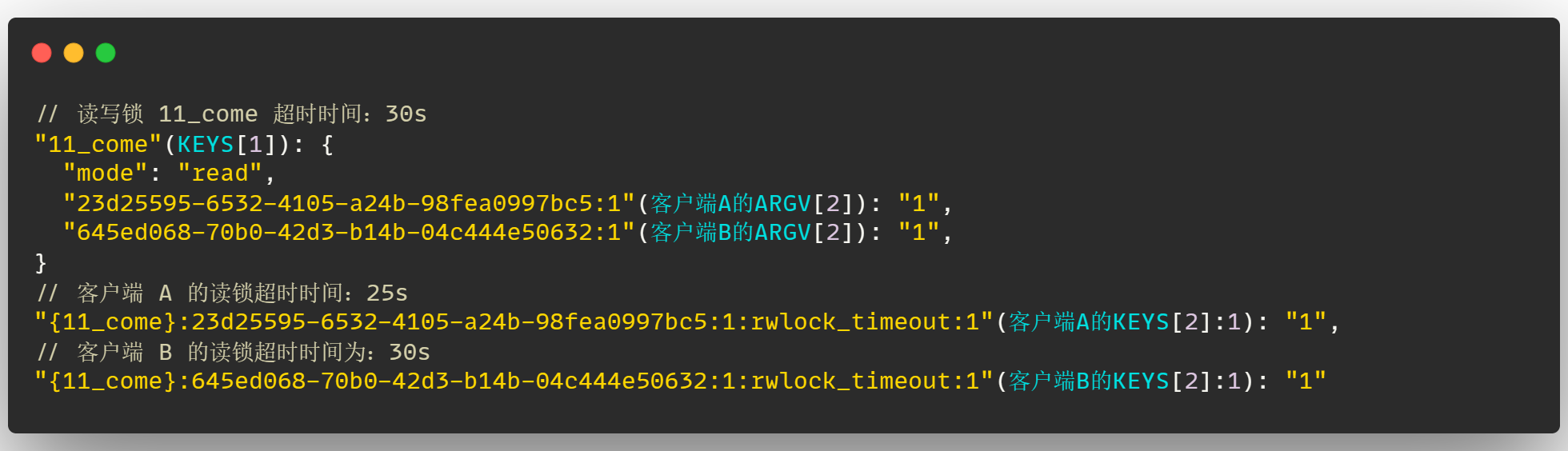
假设此时客户端 B 在 5s 后来创建一把读锁,此时会将读写锁 11_come 的超时时间重置为 30s,并且客户端 B 创建的这把读锁的超时时间也为 30s,由于 B 在 5s 后来加锁了,因此客户端 A 的锁此时超时时间为 25s
那么假如客户端 B 的读锁释放了,此时只剩下客户端 A 的读锁,此时客户端 A 的读锁超时时间为 25s,而读写锁 11_come 的超时时间为 30s,这显然不合理,如下:
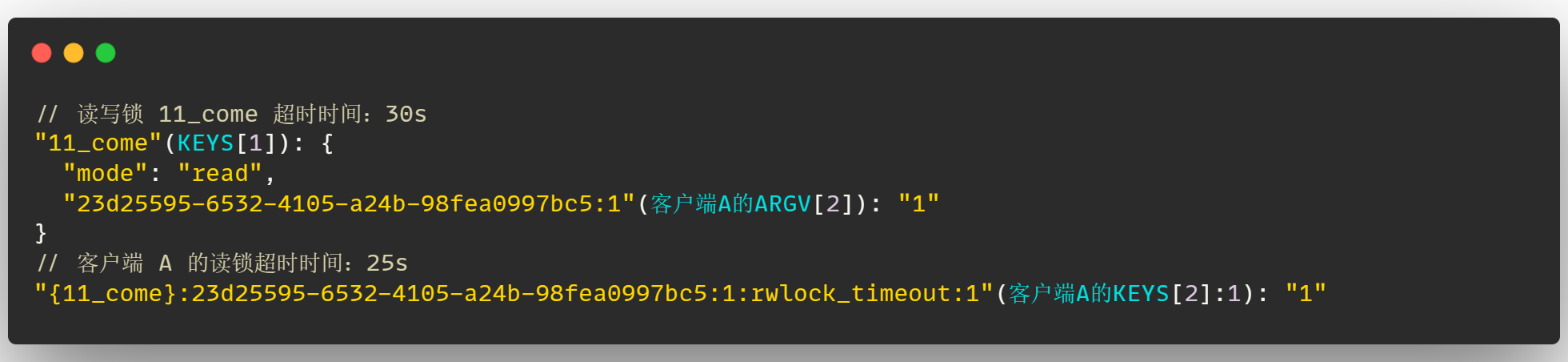
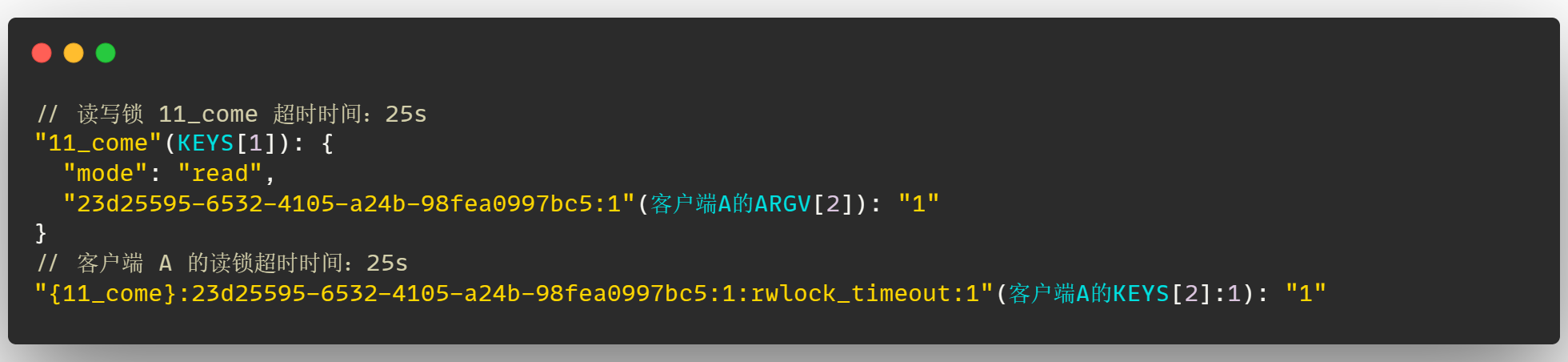
因此 Redisson 考虑到了这种情况,那么为了保证在锁释放之后,可以让 读写锁 11_come 和 每一把读锁的超时时间 保持一直,因此需要记录下来每一把读锁的超时时间,也就是通过 "{11_come}:23d25595-6532-4105-a24b-98fea0997bc5:1:rwlock_timeout:1" 这个 key 来记录
因此在客户端 A 的读锁释放的时候,会去将读写锁 11_come 的超时时间设置为客户端 A 的读锁超时时间,即 25s
# 读锁的锁续期
Redisson 的读锁 重写了锁续期 的方法,如下:
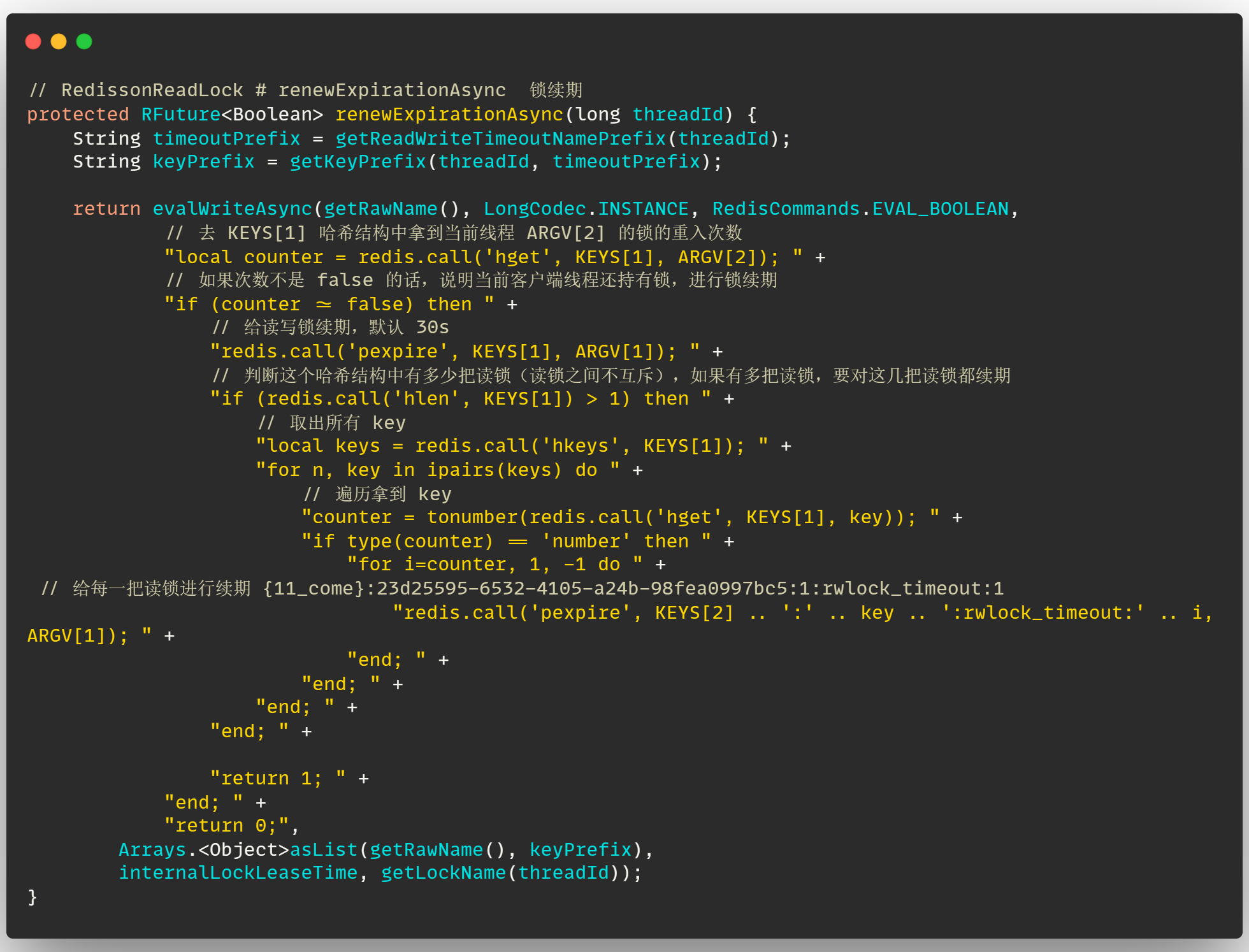
这里先说一下 lua 脚本中参数的含义:
- KEYS[1] :读写锁的名称,即
11_come - KEYS[2] :key 的前缀,即
{11_come} - ARGV[1] :锁超时时间,默认
30s - ARGV[2] :当前客户端线程的唯一标识,UUID+threadId,即
9f459868-d210-43c6-afb5-d1bce1fa3472:1
在这个锁续期方法中,其实就是对 读写锁 以及 每一把读锁 进行续期,整个流程并不算复杂,通过看注释应该就可以理解
# 读锁的解锁流程
读锁的解锁就不打算细说了,如果加锁看明白了,读锁也是不太难的,流程就是减少重入次数,如果重入次数为 0 的话,就将读写锁的哈希结构删除掉即可
不过这里要说一下读锁在解锁时,会使用 publish 发布一条消息,这里说一下发布的这个消息有什么作用
其实不只是在读锁解锁会 publish 消息,在公平锁、可重入锁解锁时都会发布,这里发布消息的目的就是让其他的客户端线程可以知道锁已经被释放了,避免等待较长的时间
# 发布消息
首先,看一下在读锁解锁时,如何发布消息:

可以看到,在解锁的两个地方发布了消息:
- 第一个地方:发现
mode == false,也就是锁已经被释放了,就发布一条通知 - 第二个地方:解锁成功,在删除锁的哈希结构后,通过 publish 发布一条通知
这里发布的通知的命令是:publish [channel] [message]
channel 的值是 KEYS[2] ,即 redisson_rwlock:{11_come} ,redisson_rwlock 是固定前缀,{11_come} 就是我们这把读写锁的名称,因此这里发布的消息是放在这个通道中了
message 的值是 ARGV[1] ,即 LockPubSub.UNLOCK_MESSAGE ,其实就是一个 Long 值,值为 0
# 订阅消息
那么既然发布了通知,肯定就要订阅通知,上边已经说了,这个通知的作用就是在线程加锁失败的时候,会进入等待,那么在等待之前会先去这个通道中订阅消息,这样在其他锁被释放之后,等待锁的线程就可以收到消息通知,直接去获取锁,就不需要一直等待了
那么订阅通知的地方就在 RedissonLock 的 lock 方法中:
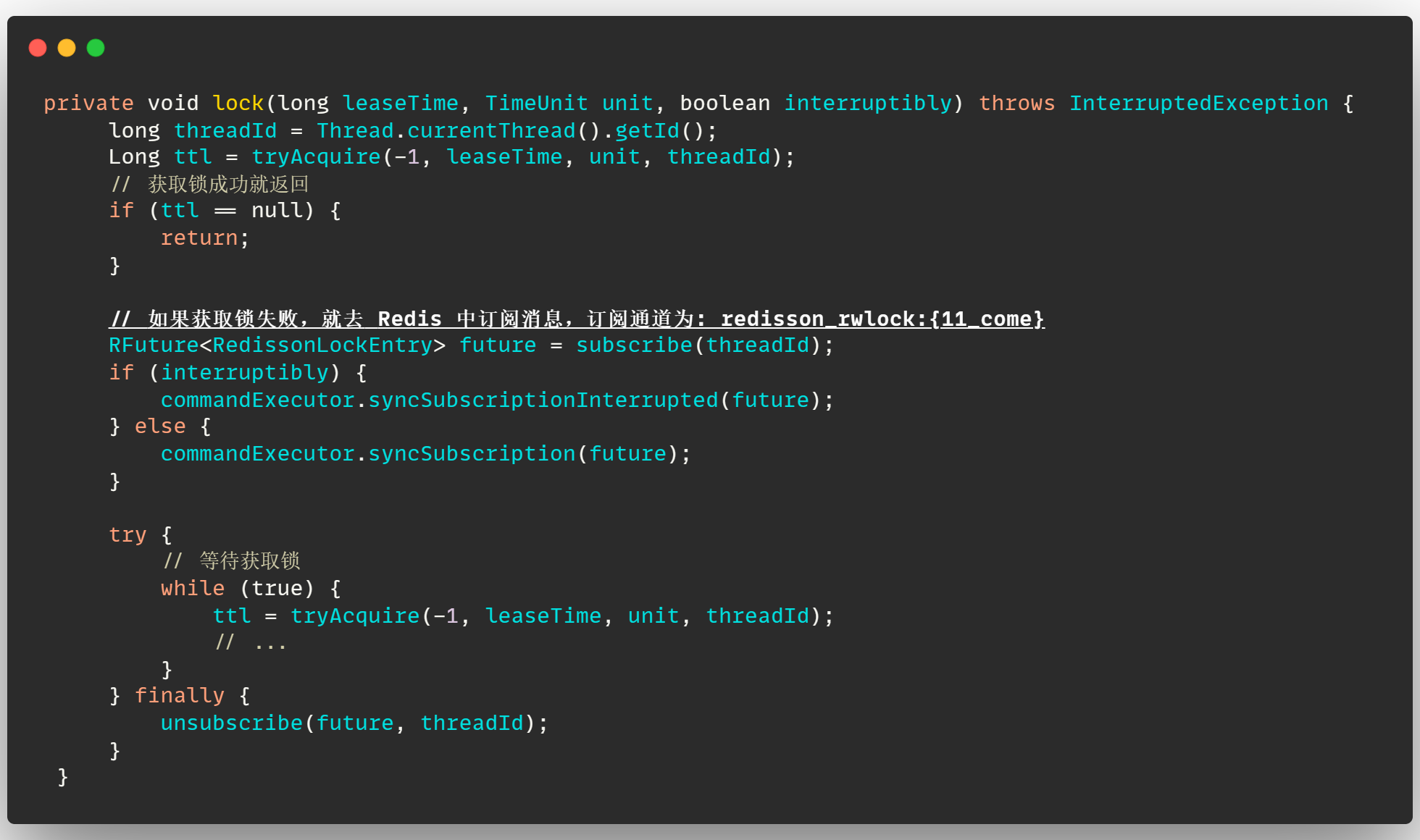
当发现锁获取失败之后,先订阅通道,再去 while 循环中等待获取锁!
至此读写锁中,读锁的加锁、锁续期、解锁就已经说完了,写锁相对于读锁来讲比较简单一些,都是重复性的内容,这里就不再赘述!
# 待整理
分布式锁在高并发场景下的优化问题
如果面试一些互联网大厂,提高分布式锁这块的内容,可能面试官会去问你,有对分布式锁进行过性能优化吗?
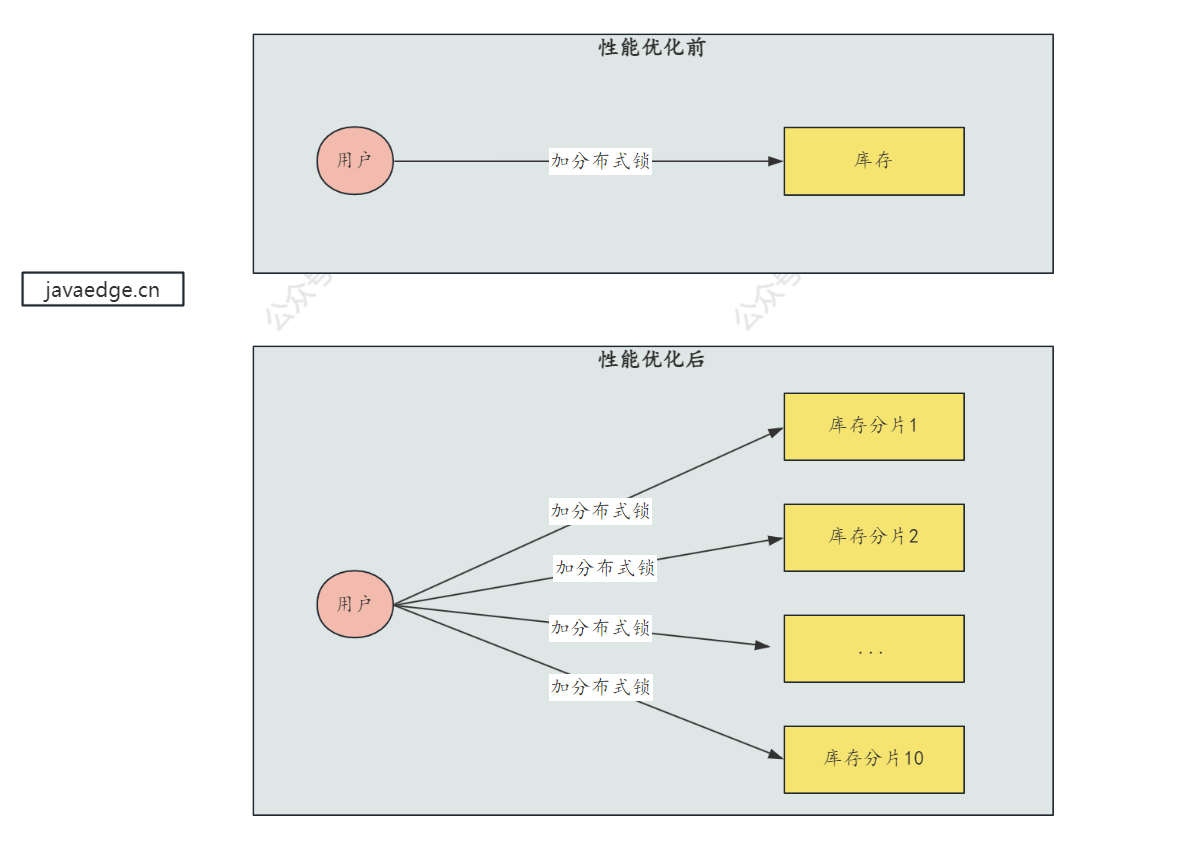
这一块的内容,可能大家没有想过这个问题,其实思路也比较简单,就是 分段加锁,目的就是减小你的锁粒度,以此来 提高系统的并发度
就比如,扣减库存,需要添加分布式锁,如果库存有 10000 个,那么可以在数据库中创建 10 个库存字段,stock_1、stock_2...,那么每次对库存操作,就对其中的一个库存字段给加锁就可以的,将库存分成了 10 个库存字段,原来一个分布式锁对库存加锁,同一时间只可以一个线程来处理,库存分片之后,同一时间可以有 10 个线程获取分布式锁,并发度提高了 十倍
如果某次来扣减库存时,库存不足的情况下,需要合并库存进行扣减,合并库存就是对其他库存字段加锁,并且查询库存,如果足够,就进行库存扣减操作
总的来说,对分布式锁的优化就是:分段锁 + 合并库存扣减